




 本文深入解析SparkCore的WordCount执行流程,统计受欢迎老师TopN的不同方法,包括自定义分区器,以及根据IP计算归属地并写入MySQL的完整过程。
本文深入解析SparkCore的WordCount执行流程,统计受欢迎老师TopN的不同方法,包括自定义分区器,以及根据IP计算归属地并写入MySQL的完整过程。
Spark Core学习
对最近在看的赵星老师Spark视频中关于SparkCore的几个案例进行总结。
目录
1.WordCount
Spark Core入门案例。
//创建spark配置,设置应用程序名字
//val conf=new SparkConf().setAppName("ScalaWordCount")
//设置本地调试
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//创建spark执行的入口
val sc=new SparkContext(conf)
//指定以后从哪里读取数据创建RDD
//sc.textFile(args(0)).flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile(args(1))
val lines: RDD[String] = sc.textFile(args(0))
//切分压平
val words:RDD[String]=lines.flatMap(_.split(""))
//将单词和一组合
val wordAndOne: RDD[(String, Int)] = words.map((_,1))
//按key进行聚合
val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted: RDD[(String, Int)] = reduced.sortBy(_._2,false)
//将结果保存到HDFS中
sorted.saveAsTextFile(args(1))
//释放资源
sc.stop()
WordCount 执行流程详解
WordCount执行过程中一共生成6个 RDD,2个Stage(一次shuffle),task取决于分区数量
注意点:
1. textFile方法生成两个RDD,一个为HadoopRDD,一个为内部调用map方法产生的MapParitionsRDD
2. 切分Stage的方法为区分宽窄依赖,shuffle次数等于宽依赖次数
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
WordCount执行流程:
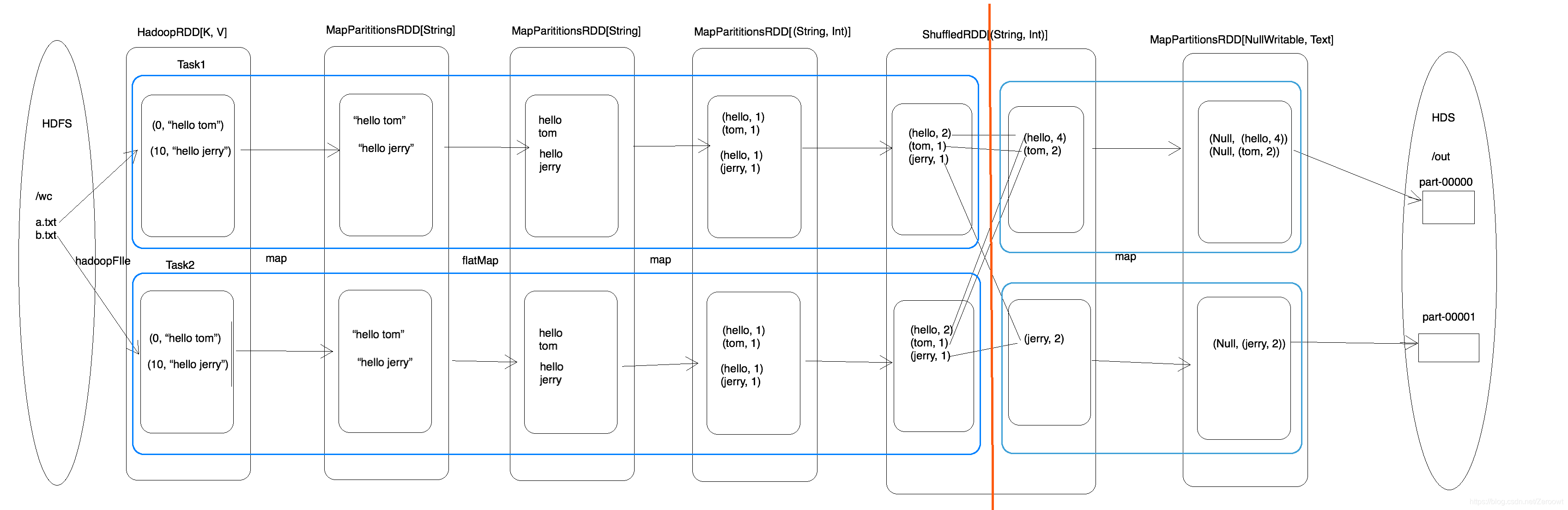
DAG可视化:

2.统计最受欢迎老师topN
数据描述:
数据格式为以下类型:http://学科.edu360.cn/老师
http://bigdata.edu360.cn/laozhang
http://bigdata.edu360.cn/laozhang
http://bigdata.edu360.cn/laozhao
http://bigdata.edu360.cn/laozhao
http://javaee.edu360.cn/xiaoxu
http://javaee.edu360.cn/laoyang
1. 方法一:普通方法,不设置分组/分区
//创建spark配置,设置应用程序名字
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//设置程序执行入口
val sc = new SparkContext(conf)
//读取文件
val Logs: RDD[String] = sc.textFile(args(0))
//压平,定义切分规则
val teacherAndOne: RDD[(String, Int)] = Logs.map(line => {
val words: Array[String] = line.split("/")
val host = words(2)
val teacher = words(3)
val lesson = host.split("[.]")(0)
(teacher, 1)
})
val recuced: RDD[(String, Int)] = teacherAndOne.reduceByKey(_+_)
//排序
val sored: RDD[(String, Int)] = recuced.sortBy(_._2,false)
//执行action
val result: Array[(String, Int)] = sored.collect()
sc.stop()
2. 方法二:设置分组和过滤器
groupby lessson以后,返回一个迭代器,再利用scala的数据结构List进行排序,缺点:利用scala集合进行排序,是在每个执行机器的内存中进行的,非常消耗资源。
//创建spark配置,设置应用程序名字
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//设置程序执行入口
val sc = new SparkContext(conf)
//读取文件
val Logs: RDD[String] = sc.textFile(args(0))
//压平切分
val teacherAndOne: RDD[((String, String),Int)] = Logs.map(line => {
val words: Array[String] = line.split("/")
val host = words(2)
val teacher = words(3)
val lesson = host.split("[.]")(0)
((teacher, lesson),1)
})
val reduced: RDD[((String, String), Int)] = teacherAndOne.reduceByKey(_+_)
//方法一:方法一用scala集合进行排序,是在内存中进行的,但是内存可能不够用
//按学科进行分组
//经过分组后,一个分区内可能有多个学科的数据,一个学科就是一个迭代器
val grouded: RDD[(String, Iterable[((String, String), Int)])] = reduced.groupBy(_._1._2)
//将每个组拿出来进行操作
val sored = grouded.mapValues(_.toList.sortBy(_._1).reverse.take(3))
//执行action
val result: Array[(String, List[((String, String), Int)])] = sored.collect()
groupBy方法描述(shuffle):
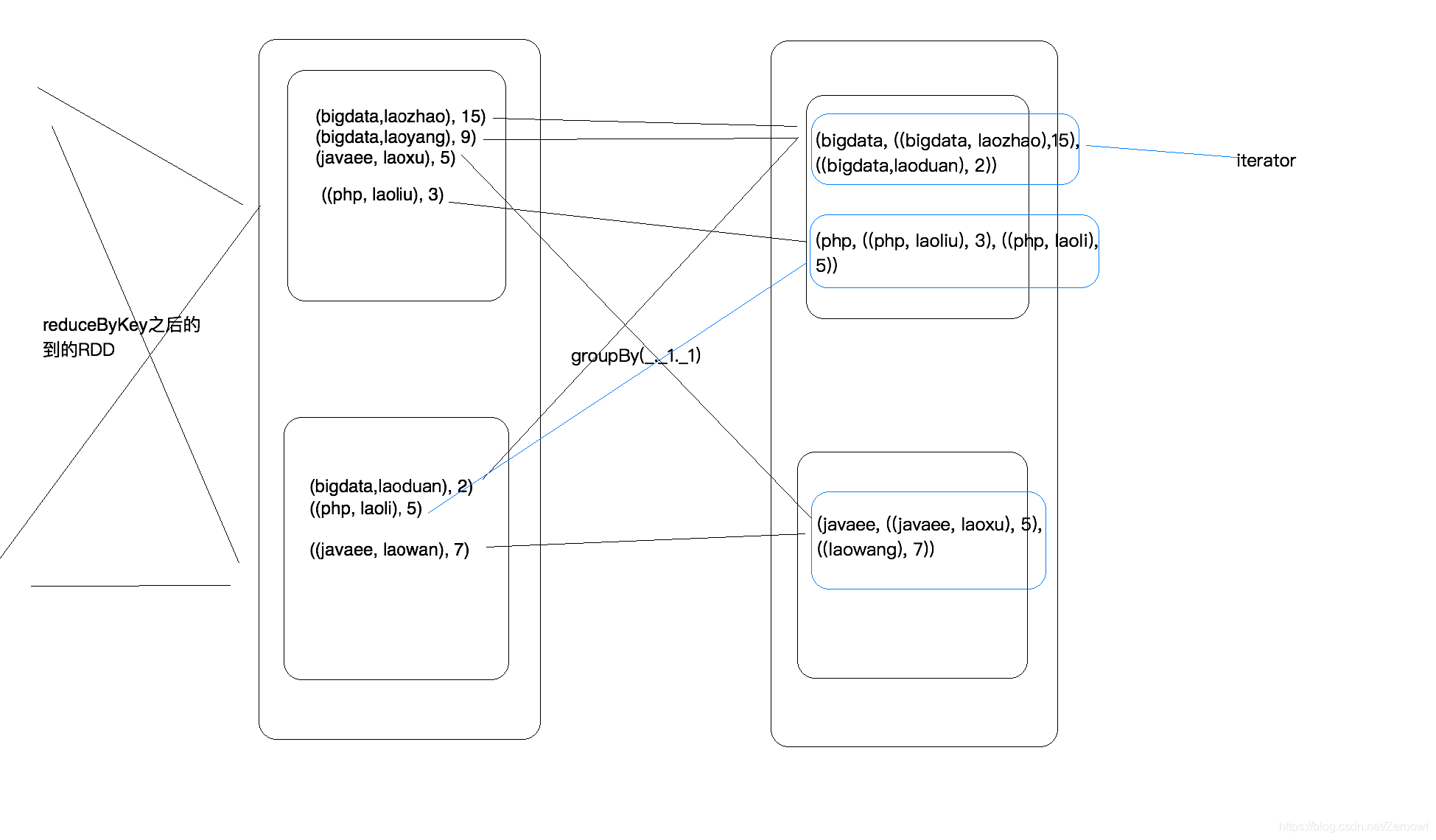
此处采用方法二,设置过滤器,并使用 RDD的sortBy方法,利用内存加磁盘进行计算(中间计算结果会保存在磁盘)
缺点:如果要对每一个学科的数据进行排序,加在循环中,每次循环会触发一次action
//方法二:调用rdd的sortby方法进行,内存+磁条进行排序
val filtered: RDD[((String, String), Int)] = reduced.filter(_._1._2=="bigdata")
//现在调用的是RDD的sortBy方法.take是一个action方法
val result: Array[((String, String), Int)] = filtered.sortBy(_._2,false).take(3)
3. 方法三:自定义分区器
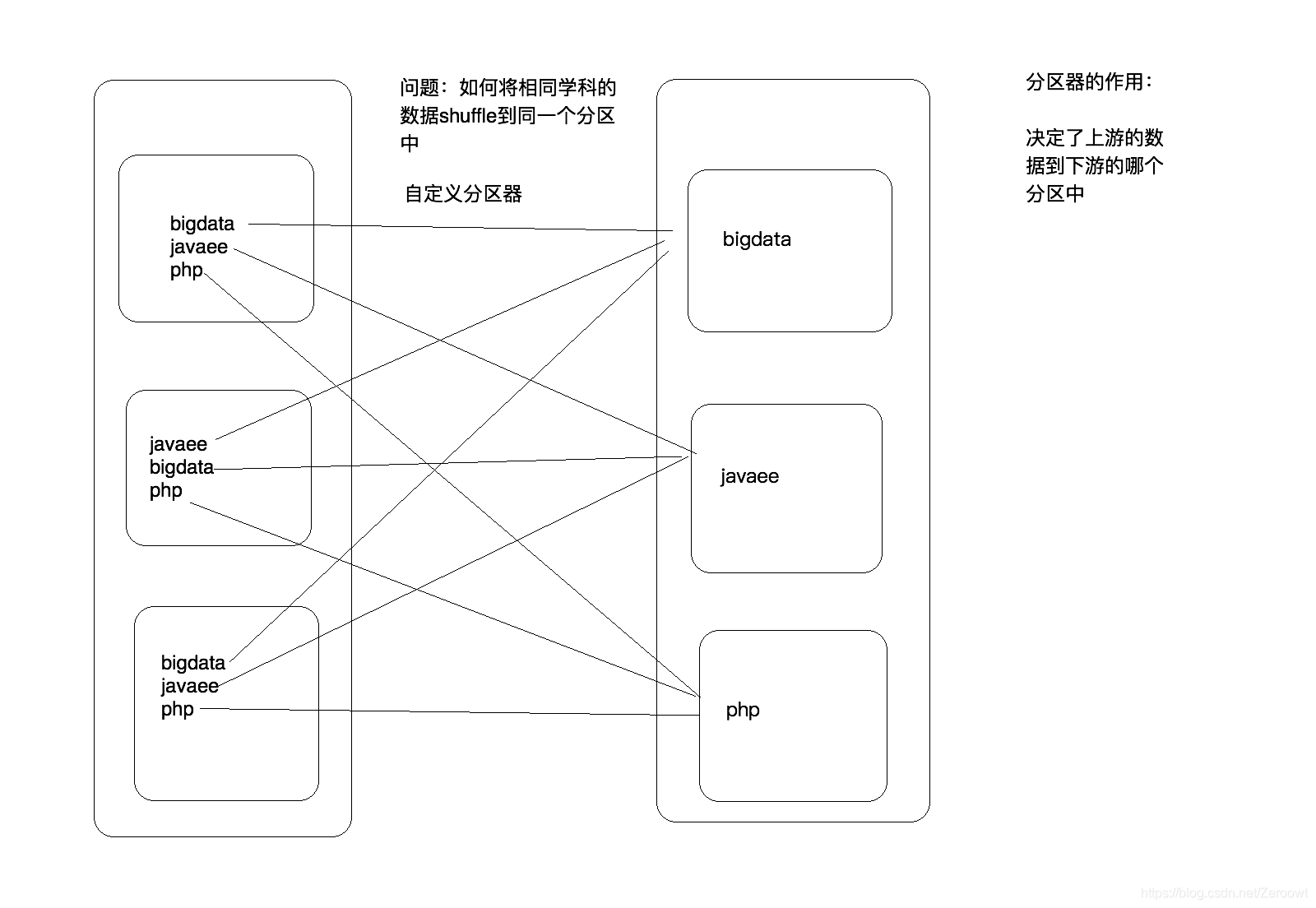
def main(args: Array[String]): Unit = {
val topN = args(1).toInt
//创建spark配置,设置应用程序名字
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//设置程序执行入口
val sc = new SparkContext(conf)
//读取文件
val Logs: RDD[String] = sc.textFile(args(0))
//压平切分
val teacherAndOne: RDD[((String, String),Int)] = Logs.map(line => {
val words: Array[String] = line.split("/")
val host = words(2)
val teacher = words(3)
val lesson = host.split("[.]")(0)
((teacher, lesson),1)
})
//聚合,将学科和老师联合当做key
val reduced: RDD[((String, String), Int)] = teacherAndOne.reduceByKey(_+_)
//计算有多少学科
val subject = reduced.map(_._1._2).distinct().collect()
//自定义分区器,并且按照指定的分区器进行分区
val subjectParitioner = new SubjectParitioner(subject)
//partitionBy按照指定的分区规则进行分区
//调用partitionBy时RDD的Key是(String, String)
val paritioned: RDD[((String, String), Int)] = reduced.partitionBy(subjectParitioner)
//如果一次拿出一个分区(可以操作一个分区中的数据了)
val sored: RDD[((String, String), Int)] = paritioned.mapPartitions(it => {
//将迭代器转换成list,然后排序,在转换成迭代器返回
it.toList.sortBy(_._2).reverse.take(topN).iterator
})
val result = sored.collect()
println(result.toBuffer)
sc.stop()
}
}
//自定义分区器
class SubjectParitioner(sbs:Array[String]) extends Partitioner{
//相当于主构造器(new的时候回执行一次)
//用于存放规则的一个map
val rules = new mutable.HashMap[String,Int]()
var i=0
for(sb <- sbs){
rules.put(sb,i)
i+=1
}
//返回分区的数量(下一个RDD有多少分区)
override def numPartitions: Int = sbs.length
//根据传入的key计算分区标号
//key是一个元组(String, String)
override def getPartition(key: Any): Int = {
//获取学科名称
val subject = key.asInstanceOf[(String, String)]._2
//根据规则计算分区编号
rules(subject)
}
注意点:partitionBy 方法中传入的partitioner: Partitioner类型参数,需要自定义分区规则继承 Partitioner抽象类。重写定义分区数量和根据key计算分区编号
3.根据IP计算归属地
需求:根据访问日志的ip地址计算出访问者的归属地,并且按照省份,计算出访问次数,然后将计算好的结果写入到MySQL
ip规则:
1.0.1.0|1.0.3.255|16777472|16778239|亚洲|中国|福建|福州||电信|350100|China|CN|119.306239|26.075302
1.0.8.0|1.0.15.255|16779264|16781311|亚洲|中国|广东|广州||电信|440100|China|CN|113.280637|23.125178
..................
网站访问日志文件:
20090121000132095572000|125.213.100.123|show.51.com|/shoplist.php?phpfile=shoplist2.php&style=1&sex=137|Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Mozilla/4.0(Compatible Mozilla/4.0(Compatible-EmbeddedWB 14.59 http://bsalsa.com/ EmbeddedWB- 14.59 from: http://bsalsa.com/ )|http://show.51.com/main.php|
20090121000132124542000|117.101.215.133|www.jiayuan.com|/19245971|Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; TencentTraveler 4.0)|http://photo.jiayuan.com/index.php?uidhash=d1c3b69e9b8355a5204474c749fb76ef|__tkist=0; myloc=50%7C5008; myage=2009; PROFILE=14469674%3A%E8%8B%A6%E6%B6%A9%E5%92%96%E5%95%A1%3Am%3Aphotos2.love21cn.com%2F45%2F1b%2F388111afac8195cc5d91ea286cdd%3A1%3A%3Ahttp%3A%2F%2Fimages.love21cn.com%2Fw4%2Fglobal%2Fi%2Fhykj_m.jpg; last_login_time=1232454068; SESSION_HASH=8176b100a84c9a095315f916d7fcbcf10021e3af; RAW_HASH=008a1bc48ff9ebafa3d5b4815edd04e9e7978050; COMMON_HASH=45388111afac8195cc5d91ea286cdd1b; pop_1232093956=1232468896968; pop_time=1232466715734; pop_1232245908=1232469069390; pop_1219903726=1232477601937; LOVESESSID=98b54794575bf547ea4b55e07efa2e9e; main_search:14469674=%7C%7C%7C00; registeruid=14469674;
20090121000132406516000|117.101.222.68|gg.xiaonei.com|/view.jsp?p=389|Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; CIBA)|http://home.xiaonei.com/Home.do?id=229670724|_r01_=1; __utma=204579609.31669176.1231940225.1232462740.1232467011.145; __utmz=204579609.1231940225.1.1.utmccn=(direct)
.......
根据IP地址计算归属地步骤:
- 整理数据,切分出ip字段,然后将ip地址转换成十进制
- 加载规则,整理规则,取出有用的字段,然后将数据缓存到内存中(Executor中的内存中)
- 将访问log与ip规则进行匹配(二分法查找)
- 取出对应的省份名称,然后将其和一组合在一起
- 按省份名进行聚合
- 将聚合后的数据写入到MySQL中
广播机制:
将driver端的任务数据分发到Executor中 broadcast,且广播到的是内存中
广播变量的弊端:广播出去的内容一旦广播出去,就不能改变了;如果需要实时改变的规则,可以将规则放到Redis或者定义在静态代码块中。
执行图:
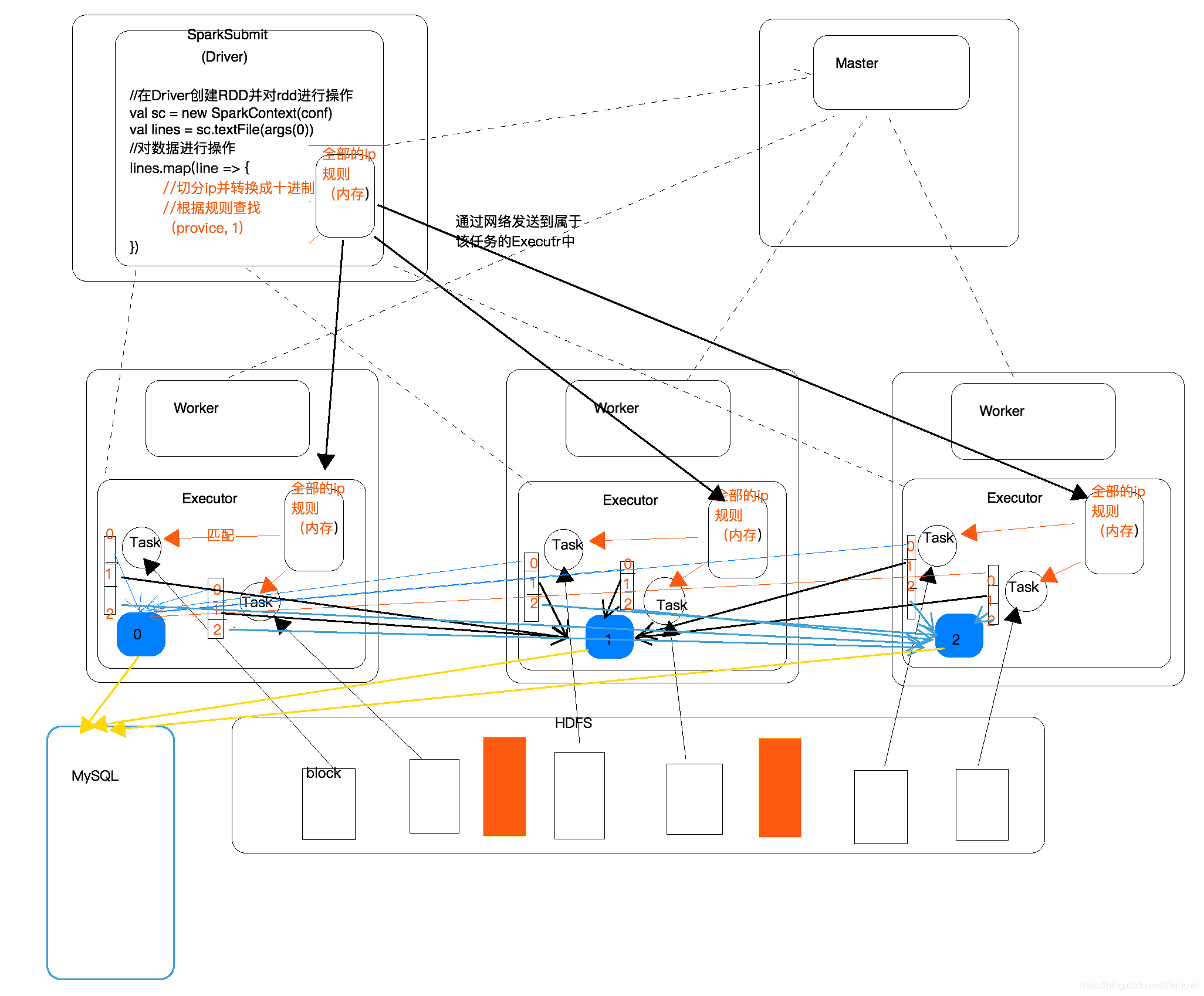
val conf = new SparkConf().setAppName("IpLoaction1").setMaster("local[4]")
val sc = new SparkContext(conf)
//取到HDFS中的ip规则
val rulesLines:RDD[String] = sc.textFile(args(0))
//整理ip规则数据
val ipRulesRDD: RDD[(Long, Long, String)] = rulesLines.map(line => {
val fields = line.split("[|]")
val startNum = fields(2).toLong
val endNum = fields(3).toLong
val province = fields(6)
(startNum, endNum, province)
})
//将分散在多个Executor中的部分IP规则收集到Driver端
val rulesInDriver: Array[(Long, Long, String)] = ipRulesRDD.collect()
//将Driver端的数据广播到Executor
//广播变量的引用(还在Driver端)
val broadcastRef: Broadcast[Array[(Long, Long, String)]] = sc.broadcast(rulesInDriver)
//创建RDD,读取访问日志
val accessLines: RDD[String] = sc.textFile(args(1))
//整理数据
val proviceAndOne: RDD[(String, Int)] = accessLines.map(log => {
//将log日志的每一行进行切分
val fields = log.split("[|]")
val ip = fields(1)
//将ip转换成十进制
val ipNum = MyUtils.ip2Long(ip)
//进行二分法查找,通过Driver端的引用或取到Executor中的广播变量
//(该函数中的代码是在Executor中别调用执行的,通过广播变量的引用,就可以拿到当前Executor中的广播的规则了)
//Driver端广播变量的引用是怎样跑到Executor中的呢?
//Task是在Driver端生成的,广播变量的引用是伴随着Task被发送到Executor中的
val rulesInExecutor: Array[(Long, Long, String)] = broadcastRef.value
//查找
var province = "未知"
val index = MyUtils.binarySearch(rulesInExecutor, ipNum)
if (index != -1) {
province = rulesInExecutor(index)._3
}
(province, 1)
})
//聚合
val reduced: RDD[(String, Int)] = proviceAndOne.reduceByKey(_+_)
//将数据写入mysql
/**
reduced.foreach(tp => {
//将数据写入到MySQL中
//问?在哪一端获取到MySQL的链接的?
//是在Executor中的Task获取的JDBC连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?charatorEncoding=utf-8", "root", "123568")
//写入大量数据的时候,有没有问题?
val pstm = conn.prepareStatement("...")
pstm.setString(1, tp._1)
pstm.setInt(2, tp._2)
pstm.executeUpdate()
pstm.close()
conn.close()
})
*/
//一次拿出一个分区(一个分区用一个连接,可以将一个分区中的多条数据写完在释放jdbc连接,这样更节省资源)
// reduced.foreachPartition(it => {
// val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123568")
// //将数据通过Connection写入到数据库
// val pstm: PreparedStatement = conn.prepareStatement("INSERT INTO access_log VALUES (?, ?)")
// //将一个分区中的每一条数据拿出来
// it.foreach(tp => {
// pstm.setString(1, tp._1)
// pstm.setInt(2, tp._2)
// pstm.executeUpdate()
// })
// pstm.close()
// conn.close()
// })
reduced.foreachPartition(it => MyUtils.data2MySQL(it))
sc.stop()
注意点:
与Mysql连接时,如果使用foreach方法,每写入一条数据就创建一次jdbc连接,浪费资源:
reduced.foreach(tp => {
//将数据写入到MySQL中
//问?在哪一端获取到MySQL的链接的?
//是在Executor中的Task获取的JDBC连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?charatorEncoding=utf-8", "root", "123568")
//写入大量数据的时候,有没有问题?
val pstm = conn.prepareStatement("...")
pstm.setString(1, tp._1)
pstm.setInt(2, tp._2)
pstm.executeUpdate()
pstm.close()
conn.close()
})
离线计算中选择使用foreachPartition进行优化(如果是实时计算,可以考虑线程池),foreachPartition一次拿出一个分区,返回迭代器
//一次拿出一个分区(一个分区用一个连接,可以将一个分区中的多条数据写完在释放jdbc连接,这样更节省资源)
reduced.foreachPartition(it => {
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123568")
//将数据通过Connection写入到数据库
val pstm: PreparedStatement = conn.prepareStatement("INSERT INTO access_log VALUES (?, ?)")
//将一个分区中的每一条数据拿出来
it.foreach(tp => {
pstm.setString(1, tp._1)
pstm.setInt(2, tp._2)
pstm.executeUpdate()
})
pstm.close()
conn.close()
})

















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









