



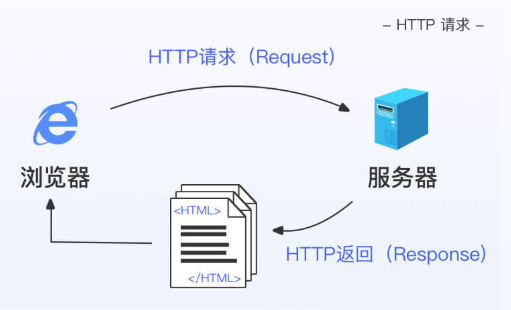
爬虫的原理:刚爬虫是自动化帮我们获取网页数据的程序。那么你可能会好奇,我们究竟是如何获取网页数据的?这里我们将网络通信与打电话做一个类比:当我们想访问某个网址(URL)时,网址(URL)就类似于电话号码,而电脑、智能手机这样的客户端(client)也就类似于电话。我们通过客户端的浏览器(browser)发送访问请求(request),就好比用电话拨打电话号码。接收请求的一方叫做服务器(web server),如果服务器运行正常并且同意我们的请求,则会向客户端发送回答(response),回答的内容会放在HTML文件里。这时,浏览器又可以帮我们解析HTML文件,让它变成我们通常看到的网页的模样。
urllib 是 Python 的一个模块,我们通过 import 调用它,并让它(urllib.request)帮我们向网址发送请求,接收回答。
相当于目标网址给我们一封尚未拆封的信,而接下来要做的是用 urllib中的 read(),来读这封信的具体内容。
from urllib.request import urlopen
page = "https://assets.baydn.com/baydn/public/codetime/1/shanbay_news.html"
# 爬取page数据存入shanbay_news
shanbay_news = urlopen(page)
news_data = shanbay_news.read()
print(news_data)

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









