




 本文深入介绍了Hive作为基于Hadoop的数据仓库工具的功能与特点,包括其可扩展性、延展性和容错性。详细讲解了如何安装MySQL作为元数据库,配置Hive的元数据库,以及启动和测试Hive服务的过程。同时,探讨了使用Hive的优势,如类SQL接口、减少MapReduce开发成本等。
本文深入介绍了Hive作为基于Hadoop的数据仓库工具的功能与特点,包括其可扩展性、延展性和容错性。详细讲解了如何安装MySQL作为元数据库,配置Hive的元数据库,以及启动和测试Hive服务的过程。同时,探讨了使用Hive的优势,如类SQL接口、减少MapReduce开发成本等。
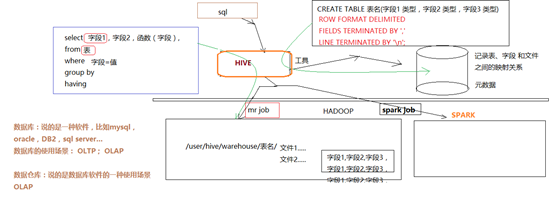
Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件(hdfs上的文件)映射为一张数据库表,并提供类SQL查询功能。
(大白话就是::把hdfs上的文件映射为数据库表,hive把映射关系记录下来,hive提供一个命令行界面输入sql,hive解析sql语法,然后根据sql组装自动生成一个mapreduce程序,再提交job到yarn上运行)
Hive的特点
可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
容错性
良好的容错性,节点出现问题SQL仍可完成执行。
hive的基本架构
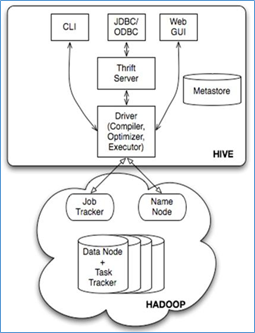
Jobtracker是hadoop1.x中的组件,它的功能相当于: Resourcemanager+MRAppMaster
TaskTracker 相当于: Nodemanager + yarnchild
安装mysql作为元数据库
- mysql安装
- 上传mysql安装包 https://pan.baidu.com/s/1OclppCyrxv9BGIssn3xA8A 提取码:pg2k
- 解压:tar -xvf MySQL-5.6.26-1.linux_glibc2.5.x86_64.rpm-bundle.tar
- 安装mysql的server包 rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
-
问题:缺依赖perl 和 libaio
查看yum上的包 yum list |grep perl
找好下载yum install -y perl的包
问题 冲突
看日志卸载冲突的包
rpm -e 要卸载的包 --nodeps
(配置本地yum源:
1、先在vmware中给这台虚拟机连接一个光盘镜像
2、挂在光驱到一个指定目录:mount -t iso9660 -o loop /dev/cdrom /mnt/cdrom
3、将yum的配置文件中baseURL指向/mnt/cdrom
)
4、继续重新安装mysql-server rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
成功后,注意提示:里面有初始密码及如何改密码的信息
初始密码:/root/.mysql_secret
改密码脚本:/usr/bin/mysql_secure_installation
- 安装mysql的客户端包: rpm -ivh MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm
- 启动mysql的服务端:service mysql start Starting MySQL. SUCCESS!
- 修改root的初始密码:/usr/bin/mysql_secure_installation
用mysql命令行客户端登陆mysql服务器看能否成功
[root@mylove ~]# mysql -uroot -proot
mysql> show databases;
- 给root用户授予从任何机器上登陆mysql服务器的权限:
mysql> grant all privileges on *.* to 'root'@'%' identified by '你的密码' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
注意点:要让mysql可以远程登录访问
最直接测试方法:从windows上用Navicat去连接,能连,则可以,不能连,则要去mysql的机器上用命令行客户端进行授权:
在mysql的机器上,启动命令行客户端:
mysql -uroot -proot
mysql>grant all privileges on *.* to 'root'@'%' identified by 'root的密码' with grant option;
mysql>flush privileges;
mysql安装完成!!!!!!!
其他的安装方式:https://blog.youkuaiyun.com/ZJX103RLF/article/details/86590363
hive的元数据库配置
vi conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
- 上传一个mysql的驱动jar包到hive的安装目录的lib中
- 配置HADOOP_HOME 和HIVE_HOME到系统环境变量中:/etc/profile
- source /etc/profile
hive启动测试
1、用命令启动hive交互界面:
[root@hdp20-04 ~]# hive
2、启动hive服务使用
启动hive的服务:
[root@hdp20-04 hive-1.2.1]# bin/hiveserver2 -hiveconf hive.root.logger=DEBUG,console
上述启动,会将这个服务启动在前台,如果要启动在后台,则命令如下:
nohup bin/hiveserver2 1>/dev/null 2>&1 &
启动成功后,可以在别的节点上用beeline去连接
方式(1)
[root@hdp20-04 hive-1.2.1]# bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2//mini1:10000
(hadoop01是hiveserver2所启动的那台主机名,端口默认是10000)
方式(2)
启动时直接连接:
bin/beeline -u jdbc:hive2://mini1:10000 -n root
接下来就可以做正常sql查询了
3、脚本化运行
大量的hive查询任务,如果用交互式shell来进行输入的话,显然效率及其低下,因此,生产中更多的是使用脚本化运行机制:
该机制的核心点是:hive可以用一次性命令的方式来执行给定的hql语句
[root@hdp20-04 ~]# hive -e "insert into table t_dest select * from t_src;"
然后,进一步,可以将上述命令写入shell脚本中,以便于脚本化运行hive任务,并控制、调度众多hive任务,示例如下:
vi t_order_etl.sh
| #!/bin/bash hive -e "select * from db_order.t_order" hive -e "select * from default.t_user" hql="create table default.t_bash as select * from db_order.t_order" hive -e "$hql" |
如果要执行的hql语句特别复杂,那么,可以把hql语句写入一个文件:
vi x.hql
| select * from db_order.t_order; select count(1) from db_order.t_user; |
然后,用hive -f /root/x.hql 来执行
- 为什么要使用Hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
功能扩展很方便。
- 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
设置一些基本参数,让hive使用起来更便捷,比如:
在linux的当前用户目录中,编辑一个.hiverc文件,将参数写入其中:
vi .hiverc
set hive.cli.print.header=true;
set hive.cli.print.current.db=true;
总览
cdh(hadoop进化版)的下载地址:
CDH5.4
http://archive.cloudera.com/cdh5/
Cloudera Manager5.4.3:
http://www.cloudera.com/downloads/manager/5-4-3.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









