




 本文详细介绍了Zookeeper集群的搭建过程与运行机制,包括数据存储机制、高可用性保障及数据监听功能,深入探讨了Zookeeper在分布式系统中的关键作用。
本文详细介绍了Zookeeper集群的搭建过程与运行机制,包括数据存储机制、高可用性保障及数据监听功能,深入探讨了Zookeeper在分布式系统中的关键作用。
HA:高可用
Namenode挂了就完犊子了,所以再加一台,但是不能两台同时对外服务,so一台的状态是active,一台是stand by,在某个点的时间一台挂了的话就需要把active的切换成stand by,stand by 切换成active,切换成active的前提是这两台namenode的元数据都是一样的,不然就不能接替工作了,而且namenode是有状态的节点,不是无状态的机器,挂了高可用的话重 启一台机器没有影响,而这种有状态的就需要保持状态的一致性,那问题就来了如何同步元素据,
原先一个namenode的时候,是内存里面有元素据,同时磁盘上有一个镜像文件,而且有一个secondenamenode不断去生成镜像文件,通过atis文件去生成镜像文件
原先namenode不光把产生元数据记录在内存里面,还要把操作记录在日志里面,还要把日志写到公共的地方去(公共日志存储管理系统),需要同步的namenode就会不断地去读日志,解析,更新内存中的元素据,并且定期把日志和文件合并形成新的镜像文件,这样就可以避免单点故障了,那么问题又来了,
公共日志存储管理系统也不能有单点故障,他也得是一个集群,分布式集群都有一个老大leader,so依赖于一个zookeeper。
所以安装一个hadoop集群要依赖于一个zookeeper(大数据用到的一个基础组件,用于各种场景)
zookeeper功能:
1、可以为客户端管理数据(k,v)k-目录(子目录) ,v-都行
2、可以为客户端监听指定数据节点的状态,并在指定数据节点发生变化时,通知客户端
zookeeper场景:
服务器上下线的动态感知
配置文件的分布式同步
zookeeper本身就是一个分布式系统,zookeeper集群一般安装奇数台节点,zookeeper只有一种程序,进程叫QUorumpeerMain,当机器启动以后,会投票选举一台机器当leader,其他就是follower。
zookeper集群安装部署:
- 上传安装包到集群服务器
- 解压
- 修改配置文件
进入zookeeper的安装目录的conf目录
修改conf/zoo.cfg
修改:
dataDir=/root/zkdata#
添加:
server.1=hdp-01:2888:3888
server.2=hdp-02:2888:3888
server.3=hdp-03:2888:3888
配置文件修改完后,将安装包拷贝给hdp-02 和 hdp-03
接着,到hdp-01上,新建数据目录/root/zkdata,并在目录中生成一个文件myid,内容为1
接着,到hdp-02上,新建数据目录/root/zkdata,并在目录中生成一个文件myid,内容为2
接着,到hdp-03上,新建数据目录/root/zkdata,并在目录中生成一个文件myid,内容为3
启动zookeeper集群:
bin/zkServer.sh start jps会看到QUorumpeerMain
bin/zkServer.sh status
自己写个zookeeper脚本启动集群vim zjxzk.sh
#!/bin/bash
for host in hdp-01 hdp-02 hdp-03
do
echo "{host}:${1}ing......"
ssh $host "source /etc/profile;/root/zookeeper-3.4.10/bin/zkServer.sh $1"
done
sleep 2
for host in hdp-01 hdp-02 hdp-03
do
ssh $host "source /etc/profile;/root/zookeeper-3.4.10/bin/zkServer.sh status"
done
给一个可执行权限chmod +x zjxzk.sh
zookeeper命令行客户端的功能
连接:bin/zkCli.sh 连集群上的其他机器:bin/zkCli.sh -server hdp-03:2181
查看节点:ls /
创建节点 create /zjx “zjx”
修改节点数据 set /zjx "zjxzjx"
获取节点数据get /zjx
删 rmr /zjx
查看节点并注册监听 get /zjx watch
zookeeper的数据存储机制/形式
zookeeper中对用户的数据采用kv形式存储
只是zk有点特别:
key:是以路径的形式表示的,那就以为着,各key之间有父子关系,比如
/ 是顶层key
用户建的key只能在/ 下作为子节点,比如建一个key: /aa 这个key可以带value数据
也可以建一个key: /bb
也可以建key: /aa/xx
zookeeper中,对每一个数据key,称作一个znode
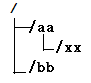
节点znode类型
zookeeper中的znode有多种类型:
- PERSISTENT 持久的:创建者就算跟集群断开联系,该类节点也会持久存在与zk集群中
- EPHEMERAL 短暂的:创建者一旦跟集群断开联系,zk就会将这个节点删除
- SEQUENTIAL 带序号的:这类节点,zk会自动拼接上一个序号,而且序号是递增的
组合类型:
PERSISTENT :持久不带序号
EPHEMERAL :短暂不带序号
PERSISTENT 且 SEQUENTIAL :持久且带序号
EPHEMERAL 且 SEQUENTIAL :短暂且带序号
zookeeper数据监听功能:
ls /aaa watch
## 查看/aaa的子节点的同时,注册了一个监听“节点的子节点变化事件”的监听器
get /aaa watch
## 获取/aaa的value的同时,注册了一个监听“节点value变化事件”的监听器
注意:注册的监听器在正常收到一次所监听的事件后,就失效
归总一下zookeeper整体运行机制
高可靠,高可用
2zookeeper软件应读安装在奇数台服务器上
只要宕机的节点 小于 集群/2.那么,zookeeper是可以正常对外服务的
zookeeper在安装的时侯不区分主从,不区分角色
zookeeper在运行时还是区分主从角色的。zookeeper在运行时会自动选举出个节点作为主节点
选举视票:
1、 第一台启动的zk进程。 会向局域网进行组播投票,投自己
2、第二台启动的工进程,会向局场网进行组播投票,我自己(因为自己的id大)
3、1和2两个进程都会收到第二轮校票。各自好一票,继续投票
4、1在这一轮会投票给2,而2也投票给2,校票结果。2得2票。此时。2得多数票顺利当leader, 1自动切换为falloer
5、第三合启动的zk进程。上线就能发现已经有leader了. 自动变成followr


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









