



在AI技术飞速迭代的今天,智能体(Agent)与模型上下文协议(MCP)早已成为AI应用落地的核心支柱。但很多刚踏入AI开发领域的程序员和技术小白,常常陷入“先攻智能体还是先学MCP”的两难困境——收藏了海量学习资源,却始终找不到高效的切入点,最终陷入无效学习的循环。
本文专为AI开发初学者量身打造,不仅梳理了一条逻辑清晰、可直接落地的阶段性学习路线,还补充了新手专属的实战避坑技巧、工具选型指南和代码注释详解。跟着这份指南学,帮你从零搭建AI智能体开发能力体系,避开80%的新手弯路,快速实现从“会用AI”到“能开发AI应用”的跨越。
核心洞察:如果把智能体比作具备决策能力的“智能大脑”,那MCP就是负责连接各类工具的“神经中枢”。新手最高效的学习路径,是先掌握“神经中枢”的工具调用逻辑,再学习“智能大脑”的决策协调机制——这种由浅入深的递进式学习,能让你少走大量弯路,学习效率直接翻倍。

第一阶段:基础能力筑牢(4-6周)—— 从编程到AI接口的实战突破
核心目标:具备"操控AI工具"的基础能力,重点打磨Python实战与API调用技巧,这是后续开发的核心底座。建议每天固定2小时学习时间,拒绝碎片化低效输入。
第1-2周:Python进阶强化(聚焦AI开发常用特性)
周一/三/五:语法攻坚 + 场景落地—— 不背概念,只练AI开发高频用法
- 装饰器:重点练"接口请求重试""日志打印"等实用场景,比如给OpenAI API加个失败自动重试的装饰器
- 生成器与上下文管理器:用生成器处理大模型返回的流式数据,用上下文管理器管理API连接
- 类型提示(Type Hints):AI工具开发必备,避免传参类型错误,配合Pyright工具实时校验
- 并发编程:asyncio实战——批量调用AI接口时,用异步提升10倍效率,这是爬虫和多工具调用的核心
# 实战示例:带重试机制的异步API调用
import asyncio
import aiohttp
from tenacity import retry, stop_after_attempt, wait_exponential
# 失败自动重试装饰器:AI接口调用必备
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
async def fetch_ai_data(url, params):
async with aiohttp.ClientSession() as session: # 上下文管理器自动管理连接
async with session.post(url, json=params) as response:
if response.status != 200:
raise Exception(f"API请求失败: {response.status}")
return await response.json()
# 批量异步调用:同时请求3个AI服务
async def batch_ai_requests():
urls = [
"https://api.example.com/ai/analyze",
"https://api.example.com/ai/summarize",
"https://api.example.com/ai/translate"
]
params_list = [{"text": "AI智能体开发"}, {"text": "MCP协议解析"}, {"text": "LangGraph实战"}]
tasks = [fetch_ai_data(url, params) for url, params in zip(urls, params_list)]
results = await asyncio.gather(*tasks, return_exceptions=True) # 捕获单个任务异常
return [res for res in results if not isinstance(res, Exception)]
# 运行入口
if __name__ == "__main__":
results = asyncio.run(batch_ai_requests())
print("批量调用结果:", results)
周二/四:小型项目驱动练习—— 把语法融入实际开发场景
- CLI任务管理器:集成"任务添加/查询/删除",用装饰器记录操作日志,练手函数封装与参数解析
- 网络请求工具:支持同步/异步切换,实现请求头自动携带、响应数据格式化,为调用AI API打基础
周末综合项目:异步多线程爬虫——爬取技术博客文章,用生成器逐行处理内容,批量提取"AI智能体"相关段落,练手并发与数据处理结合
第3周:AI API与提示词工程双突破
这是连接"编程基础"与"AI开发"的关键一步,重点掌握"如何让AI听懂你的需求"。
1. OpenAI API实战通关
- 模型选型指南:GPT-4o适合复杂推理,GPT-3.5适合批量处理,用实际案例测不同模型的响应速度与成本
- 调参秘籍:temperature(0.2精确/0.8创意)、top_p(控制输出多样性)、max_tokens(避免冗余),附调参对比表
- 流式响应核心:处理大模型长文本输出,实现"边生成边显示"效果,提升用户体验
# 带调参对比的高级API调用示例
from openai import OpenAI
import time
client = OpenAI(api_key="你的API密钥")
def compare_model_performance(prompt, models=["gpt-3.5-turbo", "gpt-4o"], temps=[0.3, 0.7]):
"""对比不同模型和参数的响应效果"""
results = []
for model in models:
for temp in temps:
start_time = time.time()
# 调用API(支持流式/非流式切换)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temp,
stream=False
)
cost_time = time.time() - start_time
results.append({
"model": model,
"temperature": temp,
"response": response.choices[0].message.content[:100] + "...",
"cost_time": round(cost_time, 2)
})
# 打印对比结果
for res in results:
print(f"模型: {res['model']} | 温度: {res['temperature']} | 耗时: {res['cost_time']}s | 内容: {res['response']}")
# 测试:让AI解释MCP协议核心概念
compare_model_performance(prompt="用程序员能听懂的话解释MCP协议,不超过200字")
2. 提示词工程系统化学习—— 这是"免费提升AI能力"的关键
- 角色锚定法:给AI加"资深AI开发工程师"角色,附模板:“你是拥有3年AI智能体开发经验的工程师,用Python开发者能理解的语言解释技术点,避免晦涩术语”
- 思维链(CoT)实战:复杂问题拆分成"步骤引导",比如"先解释MCP的核心组件,再说明各组件如何交互,最后举一个天气查询工具的例子"
- 少样本学习:给AI1-2个示例,让它按格式输出,比如批量提取代码中的函数名,先给"输入:代码段 | 输出:[函数1, 函数2]"的示例
第4周:RAG技术落地——让AI"记住"你的私有数据
RAG(检索增强生成)是智能体的核心能力之一,能解决大模型"知识过时"和"不会私有数据"的问题。本周聚焦"文档问答系统"实战。
- 核心流程:文档加载→文本分块→向量存储→检索匹配→生成答案
- 工具选型:用LangChain加载文档,ChromaDB做本地向量库(轻量易部署),OpenAI Embeddings生成向量
- 优化技巧:文本分块用"1000字符+200重叠",提升检索准确率;给检索结果加"相关性评分",过滤无效信息
# 可直接运行的简易RAG系统
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain.chains import RetrievalQA
class LocalDocQA:
def __init__(self, doc_path, api_key):
self.embeddings = OpenAIEmbeddings(api_key=api_key)
self.llm = ChatOpenAI(model_name="gpt-3.5-turbo", api_key=api_key)
self.vector_db = self._build_vector_db(doc_path)
def _build_vector_db(self, doc_path):
"""构建本地向量数据库"""
# 加载文档(支持txt、pdf等,需安装对应依赖)
loader = TextLoader(doc_path, encoding="utf-8")
documents = loader.load()
# 文本分块:核心参数优化
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块1000字符
chunk_overlap=200, # 重叠200字符,保持上下文连贯
length_function=len
)
chunks = text_splitter.split_documents(documents)
# 存入ChromaDB
return Chroma.from_documents(chunks, self.embeddings, persist_directory="./chroma_db")
def query_doc(self, question, k=3):
"""查询文档并生成答案"""
# 构建检索链
qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff", # 适合短文档,长文档用"map_reduce"
retriever=self.vector_db.as_retriever(search_kwargs={"k": k}),
return_source_documents=True # 返回检索到的源文档,方便验证
)
result = qa_chain({"query": question})
# 整理结果
return {
"answer": result["result"],
"source": [doc.page_content[:50] + "..." for doc in result["source_documents"]]
}
# 实战:查询本地MCP文档
if __name__ == "__main__":
qa = LocalDocQA(doc_path="./mcp_doc.txt", api_key="你的API密钥")
res = qa.query_doc(question="MCP协议中的Server组件有什么作用?")
print("答案:", res["answer"])
print("参考来源:", res["source"])
第二阶段:MCP深度掌握(3-4周)—— 智能体的"工具中枢"开发
MCP是智能体调用工具的标准化协议,学会开发MCP服务,就能让你的智能体无缝对接天气、翻译、数据库等各类工具。
第1周:MCP核心概念与协议规范
必学资源:MCP官方文档(附中文注解版链接)、GitHub开源MCP项目源码(推荐"modelcontextprotocol/mcp-python")
核心笔记整理
MCP三大核心组件(牢记"谁提供-谁调用-怎么传"):
1. Server(工具提供方):封装具体工具能力,暴露标准化接口(比如天气查询服务)
2. Client(智能体/应用方):作为调用者,向Server发送工具调用请求
3. Transport(通信层):支持进程内调用、HTTP、stdio等,开发初期用进程内调试更高效
MCP四大开发优势(新手必懂):
- 类型安全:强类型定义,工具参数错了编译期就报错,减少线上问题
- 可组合性:多个MCP服务可自由组合,比如"翻译MCP+总结MCP"实现多步处理
- 权限隔离:工具权限独立管控,避免智能体越权调用危险工具
- 跨语言:Python写的Server,JS的智能体也能调用,兼容性强
第2周:MCP服务器开发实战(天气查询服务)
从0开发第一个MCP服务,重点掌握"工具定义-服务启动-调用测试"全流程。
# weather_mcp_server.py(完整可运行版)
import asyncio
from mcp import Server, Tool
import httpx
from pydantic import Field # 强类型校验,MCP开发必备
# 1. 定义天气查询工具(带参数校验)
class WeatherQueryTool(Tool):
name = "get_real_time_weather" # 工具名,智能体调用时需匹配
description = "获取指定城市的实时天气,返回温度、湿度、天气状况"
# 定义参数:用Field做校验和描述,智能体能自动识别
city: str = Field(description="城市名称,如'北京'、'上海',仅支持国内地级市")
async def run(self) -> dict:
"""工具核心逻辑:调用第三方天气API"""
# 参数预处理:避免空格等问题
city = self.city.strip()
# 调用公开天气API(这里用模拟接口,实际可替换为高德/百度API)
async with httpx.AsyncClient(timeout=10) as client:
try:
response = await client.get(
url="https://restapi.amap.com/v3/weather/weatherInfo",
params={"key": "你的高德API密钥", "city": city, "extensions": "base"}
)
data = response.json()
# 提取核心信息并格式化
if data["status"] == "1" and len(data["lives"]) > 0:
weather = data["lives"][0]
return {
"city": city,
"temperature": weather["temperature"],
"humidity": weather["humidity"],
"weather": weather["weather"],
"update_time": weather["reporttime"]
}
else:
return {"error": f"未查询到{city}的天气信息,请检查城市名称"}
except Exception as e:
return {"error": f"天气查询失败:{str(e)}"}
# 2. 启动MCP服务器
async def start_mcp_server():
# 初始化服务器,指定服务名称
server = Server(identifier="weather-mcp-server-v1")
# 添加工具到服务器
server.add_tool(WeatherQueryTool)
# 启动服务(默认进程内通信,端口可配置)
print("MCP天气服务启动成功,等待调用...")
await server.run()
if __name__ == "__main__":
# 运行服务器
asyncio.run(start_mcp_server())
测试方法(新手友好)
# 1. 安装依赖
pip install mcp-python httpx pydantic
npm install -g @modelcontextprotocol/cli # 安装MCP CLI工具
# 2. 启动服务器(新开终端)
python weather_mcp_server.py
# 3. 另开终端,用CLI测试工具调用
mcp call get_real_time_weather --city 北京
# 成功响应示例:
# {
# "city": "北京",
# "temperature": "25",
# "humidity": "45%",
# "weather": "晴",
# "update_time": "2025-12-17 14:30"
# }
第3周:高级MCP特性——让服务更健壮
聚焦企业级开发需求,解决"权限控制"“错误处理”"动态资源"等问题。
- 资源管理:动态返回可查询的城市列表,让智能体知道"能调用哪些参数"
- 错误处理:定义标准化错误码(如1001=城市无效,1002=API超时),方便智能体重试
- 权限控制:给工具加调用白名单,避免未授权访问
# 高级MCP服务示例(含资源管理与权限控制)
from mcp import Server, Tool, Resource
from pydantic import Field
# 1. 定义权限校验Mixin
class PermissionMixin:
allowed_api_keys: list = ["dev_key_001", "prod_key_002"]
def check_permission(self, api_key: str):
if api_key not in self.allowed_api_keys:
raise PermissionError("API密钥无效,无调用权限")
# 2. 带权限控制的天气工具
class SecuredWeatherTool(Tool, PermissionMixin):
name = "get_weather_with_perm"
description = "带权限校验的天气查询工具"
city: str = Field(description="城市名称")
api_key: str = Field(description="调用者API密钥") # 权限校验参数
async def run(self) -> dict:
# 先做权限校验
self.check_permission(self.api_key)
# 天气查询逻辑(同前)
return {"city": self.city, "temperature": "26", "weather": "多云"}
# 3. 动态资源:返回可查询的城市列表
class AvailableCitiesResource(Resource):
name = "list_supported_cities"
description = "返回所有支持天气查询的城市"
async def get(self) -> list:
# 实际开发中可从数据库/配置文件读取
return ["北京", "上海", "广州", "深圳", "杭州"]
# 4. 启动高级MCP服务器
async def start_advanced_server():
server = Server(identifier="advanced-weather-server")
server.add_tool(SecuredWeatherTool)
server.add_resource(AvailableCitiesResource)
print("高级MCP服务启动,支持权限校验和动态资源查询")
await server.run()
if __name__ == "__main__":
asyncio.run(start_advanced_server())
第三阶段:智能体开发精通(4-5周)—— 打造会"思考"的AI
核心目标:用LangGraph构建具备"推理-行动-反馈"能力的智能体,实现MCP工具的自动调用与结果整合。
第1-2周:LangGraph核心与ReAct模式实战
LangGraph是构建智能体的主流框架,核心是"用图结构定义智能体的工作流程"。
必学概念:
- 节点(Node):执行具体逻辑,如"推理节点"“工具调用节点”“结果整理节点”
- 状态(State):存储智能体运行中的数据,如"用户问题"“工具结果”“消息历史”
- 边(Edge):定义节点间的流转规则,如"推理后需要调用工具则去行动节点,否则直接输出结果"
ReAct模式落地:Reason(推理)→ Act(行动)→ Observe(观察结果)→ Repeat(循环)
# 基础ReAct智能体(LangGraph实现)
from langgraph import StateGraph, START, END
from langgraph.graph import ConditionalEdge
from typing import TypedDict, Annotated
import operator
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
from my_mcp_servers import SecuredWeatherTool # 导入之前写的MCP工具
# 1. 定义智能体状态:存储所有运行数据
class AgentState(TypedDict):
# 消息历史:用operator.add实现列表追加
messages: Annotated[list, operator.add]
# 当前任务状态:idle/reasoning/acting
task_status: str
# 2. 初始化LLM和MCP工具
llm = ChatOpenAI(model="gpt-4o", temperature=0.3)
weather_tool = SecuredWeatherTool(api_key="dev_key_001") # 初始化MCP工具
tools = [weather_tool]
# 3. 定义推理节点:分析是否需要调用工具
def reasoning_node(state: AgentState) -> dict:
"""根据用户问题,判断是否需要调用工具"""
last_msg = state["messages"][-1]
# 让LLM做决策:输出是否调用工具及调用参数
system_prompt = """你是一个智能助手,能判断是否需要调用工具。
如果需要调用工具,请输出工具调用格式:<tool_call>{"name":"工具名","parameters":{"参数名":"值"}}</tool_call>
如果不需要,直接回答用户问题。"""
prompt = f"{system_prompt}\n用户问题:{last_msg.content}"
response = llm.invoke([HumanMessage(content=prompt)])
return {
"messages": [response],
"task_status": "reasoning_done"
}
# 4. 定义行动节点:执行工具调用
async def acting_node(state: AgentState) -> dict:
"""根据推理结果,调用对应的MCP工具"""
last_msg = state["messages"][-1].content
# 解析工具调用指令(实际开发中需完善解析逻辑)
tool_call = {"name": "get_weather_with_perm", "parameters": {"city": "北京", "api_key": "dev_key_001"}}
# 调用MCP工具
if tool_call["name"] == weather_tool.name:
tool_result = await weather_tool.run(**tool_call["parameters"])
# 封装工具结果为ToolMessage
tool_msg = ToolMessage(content=str(tool_result), tool_call_id="1")
return {
"messages": [tool_msg],
"task_status": "acting_done"
}
return {
"messages": [AIMessage(content="未找到匹配的工具")],
"task_status": "acting_failed"
}
# 5. 定义流转规则:判断推理后是否需要调用工具
def should_call_tool(state: AgentState) -> str:
"""根据推理结果,决定下一步走向"""
last_msg = state["messages"][-1].content
if "<tool_call>" in last_msg:
return "act" # 调用工具
else:
return END # 直接结束
# 6. 构建智能体工作流
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("reason", reasoning_node)
builder.add_node("act", acting_node)
# 定义流转路径
builder.add_edge(START, "reason")
# 条件流转:推理后判断是否调用工具
builder.add_conditional_edges("reason", should_call_tool)
# 工具调用后直接结束(后续可扩展结果整理节点)
builder.add_edge("act", END)
# 编译智能体
agent = builder.compile()
# 7. 运行智能体
async def run_agent(user_query: str):
initial_state = {
"messages": [HumanMessage(content=user_query)],
"task_status": "idle"
}
# 执行智能体
final_state = await agent.ainvoke(initial_state)
# 输出最终结果
for msg in final_state["messages"]:
if isinstance(msg, AIMessage) and "<tool_call>" not in msg.content:
print("智能体回答:", msg.content)
elif isinstance(msg, ToolMessage):
print("工具调用结果:", msg.content)
# 测试:让智能体查询北京天气
if __name__ == "__main__":
asyncio.run(run_agent("查询北京今天的天气,用你能调用的工具获取实时数据"))
第3周:MCP与智能体深度集成
核心解决"智能体如何自动发现并调用MCP工具"的问题,实现工具的动态加载与管理。
# MCP工具自动加载的智能体
from langgraph import StateGraph, START, END
from typing import TypedDict, List
from langchain_core.messages import HumanMessage, AIMessage
from mcp import Client # MCP客户端,用于发现工具
import asyncio
# 1. 定义智能体状态
class MCPAgentState(TypedDict):
user_query: str
available_tools: List[dict] # 可用MCP工具列表
tool_results: List[dict]
final_answer: str
# 2. MCP工具管理器:自动发现和加载工具
class MCPToolManager:
def __init__(self, mcp_server_urls: List[str]):
self.mcp_servers = [Client(url) for url in mcp_server_urls]
async def discover_tools(self) -> List[dict]:
"""发现所有MCP服务器上的工具"""
all_tools = []
for server in self.mcp_servers:
# 调用MCP服务的元数据接口,获取工具列表
tools = await server.list_tools()
# 格式化工具信息:供LLM识别
for tool in tools:
all_tools.append({
"name": tool["name"],
"description": tool["description"],
"parameters": tool["parameters"]
})
return all_tools
# 3. 定义智能体节点
async def tool_discovery_node(state: MCPAgentState) -> MCPAgentState:
"""发现可用的MCP工具"""
tool_manager = MCPToolManager(mcp_server_urls=["http://localhost:8000"])
available_tools = await tool_manager.discover_tools()
print("发现MCP工具:", [tool["name"] for tool in available_tools])
return {**state, "available_tools": available_tools}
async def tool_selection_node(state: MCPAgentState) -> MCPAgentState:
"""选择合适的MCP工具并调用"""
llm = ChatOpenAI(model="gpt-4o")
# 让LLM从可用工具中选择合适的
prompt = f"""根据用户问题{state['user_query']},从以下工具中选择合适的工具调用:
{state['available_tools']}
输出工具调用参数:{"name":"工具名","parameters":{"参数名":"值"}}"""
response = llm.invoke([HumanMessage(content=prompt)])
# 解析工具调用参数(简化版)
tool_call = eval(response.content) # 实际开发中用安全解析方式
# 调用MCP工具
client = Client(url="http://localhost:8000")
tool_result = await client.call(tool_call["name"], **tool_call["parameters"])
return {**state, "tool_results": [tool_result]}
def answer_generation_node(state: MCPAgentState) -> MCPAgentState:
"""根据工具结果生成最终答案"""
llm = ChatOpenAI(model="gpt-4o")
prompt = f"""用户问题:{state['user_query']}
工具调用结果:{state['tool_results']}
请整理成自然语言回答,突出核心信息。"""
final_answer = llm.invoke([HumanMessage(content=prompt)]).content
return {**state, "final_answer": final_answer}
# 4. 构建集成MCP的智能体
builder = StateGraph(MCPAgentState)
builder.add_node("discover_tools", tool_discovery_node)
builder.add_node("select_and_call_tool", tool_selection_node)
builder.add_node("generate_answer", answer_generation_node)
# 定义流转路径
builder.add_edge(START, "discover_tools")
builder.add_edge("discover_tools", "select_and_call_tool")
builder.add_edge("select_and_call_tool", "generate_answer")
builder.add_edge("generate_answer", END)
# 编译并运行
agent = builder.compile()
async def run_mcp_agent(user_query: str):
initial_state = {
"user_query": user_query,
"available_tools": [],
"tool_results": [],
"final_answer": ""
}
final_state = await agent.ainvoke(initial_state)
print("最终回答:", final_state["final_answer"])
# 测试:自动发现工具并查询天气
if __name__ == "__main__":
asyncio.run(run_mcp_agent("帮我查一下上海今天的实时天气"))
第4周:复杂智能体项目——研究助手智能体
整合前三周知识,开发一个能"分析问题→网络搜索→文档总结→生成报告"的多节点智能体。
# 研究助手智能体(完整流程)
from langgraph import StateGraph, START, END
from typing import TypedDict, List
from langchain_openai import ChatOpenAI
from langchain_community.tools import DuckDuckGoSearchRun # 网络搜索工具
from my_mcp_servers import SecuredWeatherTool # 之前的MCP工具
from my_rag_system import LocalDocQA # 第二阶段的RAG系统
# 1. 定义研究状态
class ResearchState(TypedDict):
topic: str # 研究主题
search_queries: List[str] # 生成的搜索关键词
search_results: List[str] # 网络搜索结果
doc_summaries: List[str] # 文档总结结果
final_report: str # 最终研究报告
# 2. 初始化依赖工具
llm = ChatOpenAI(model="gpt-4o")
search_tool = DuckDuckGoSearchRun() # 网络搜索工具
rag_system = LocalDocQA(doc_path="./ai_agent_doc.txt", api_key="你的API密钥") # RAG工具
# 3. 定义核心节点
def analyze_topic_node(state: ResearchState) -> ResearchState:
"""分析研究主题,生成搜索关键词"""
topic = state["topic"]
prompt = f"为研究主题'{topic}'生成3个精准的搜索关键词,用于网络搜索,仅输出关键词列表(用逗号分隔)"
response = llm.invoke([HumanMessage(content=prompt)])
search_queries = [q.strip() for q in response.content.split(",")]
return {**state, "search_queries": search_queries}
def search_node(state: ResearchState) -> ResearchState:
"""根据关键词执行网络搜索"""
search_results = []
for query in state["search_queries"]:
result = search_tool.run(query)
search_results.append(f"关键词[{query}]:{result[:300]}...") # 截取部分内容
return {**state, "search_results": search_results}
def summarize_doc_node(state: ResearchState) -> ResearchState:
"""用RAG系统总结相关文档"""
doc_summaries = []
for query in state["search_queries"]:
# 用RAG查询本地文档
rag_result = rag_system.query_doc(question=f"总结关于'{query}'的内容")
doc_summaries.append(f"关键词[{query}]:{rag_result['answer']}")
return {**state, "doc_summaries": doc_summaries}
def generate_report_node(state: ResearchState) -> ResearchState:
"""整合所有结果,生成研究报告"""
prompt = f"""根据以下信息,为主题'{state['topic']}'撰写一份结构化研究报告:
1. 网络搜索结果:{state['search_results']}
2. 文档总结结果:{state['doc_summaries']}
报告结构:主题概述→核心观点→参考来源,语言简洁专业,适合程序员阅读。"""
report = llm.invoke([HumanMessage(content=prompt)]).content
return {**state, "final_report": report}
# 4. 构建研究流程
builder = StateGraph(ResearchState)
# 添加节点
builder.add_node("analyze_topic", analyze_topic_node)
builder.add_node("search", search_node)
builder.add_node("summarize_doc", summarize_doc_node)
builder.add_node("generate_report", generate_report_node)
# 定义流转顺序
builder.add_edge(START, "analyze_topic")
builder.add_edge("analyze_topic", "search")
builder.add_edge("search", "summarize_doc")
builder.add_edge("summarize_doc", "generate_report")
builder.add_edge("generate_report", END)
# 编译智能体
research_agent = builder.compile()
# 5. 运行研究助手
def run_research(topic: str) -> str:
initial_state = {
"topic": topic,
"search_queries": [],
"search_results": [],
"doc_summaries": [],
"final_report": ""
}
final_state = research_agent.invoke(initial_state)
return final_state["final_report"]
# 测试:研究"AI智能体与MCP协议的集成方案"
if __name__ == "__main__":
report = run_research(topic="AI智能体与MCP协议的集成方案")
print("研究报告:")
print(report)
第四阶段:进阶实战(持续学习)—— 从单智能体到系统级开发
智能体开发的终极目标是解决复杂业务问题,这需要掌握多智能体协作、性能优化等进阶能力。
多智能体协作系统(CrewAI实战)
当一个智能体无法完成复杂任务时,就需要多个智能体分工协作——比如"研究员+程序员+测试员"组成AI开发团队。
# 基于CrewAI的AI智能体开发团队
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
from langchain_community.tools import DuckDuckGoSearchRun, FileWriteTool
# 1. 初始化LLM和工具
llm = ChatOpenAI(model="gpt-4o", temperature=0.4)
search_tool = DuckDuckGoSearchRun()
write_tool = FileWriteTool()
# 2. 定义智能体角色
# 角色1:AI技术研究员
researcher = Agent(
role="资深AI技术研究员",
goal="深入调研AI智能体开发的最新技术和最佳实践,重点关注MCP协议的应用",
tools=[search_tool],
llm=llm,
verbose=True,
backstory="拥有5年AI领域研究经验,擅长梳理技术发展脉络和核心知识点"
)
# 角色2:Python开发工程师
developer = Agent(
role="Python全栈开发工程师",
goal="将研究成果转化为可运行的AI智能体代码,符合Python编码规范",
tools=[write_tool],
llm=llm,
verbose=True,
backstory="精通LangChain、LangGraph等AI开发框架,曾开发多个企业级智能体应用"
)
# 角色3:测试工程师
tester = Agent(
role="AI应用测试工程师",
goal="对开发的智能体代码进行测试,找出bug并提供优化建议",
llm=llm,
verbose=True,
backstory="擅长AI应用的功能测试和性能优化,熟悉智能体常见的边界问题"
)
# 3. 定义任务
# 任务1:调研MCP协议的最新应用
research_task = Task(
description="""1. 调研MCP协议在2025年的最新应用案例,重点关注智能体开发场景;
2. 整理MCP与LangGraph集成的3个核心方法;
3. 输出调研报告,结构为:应用案例→核心方法→未来趋势""",
agent=researcher,
expected_output="不少于800字的调研报告,包含具体案例和技术细节"
)
# 任务2:开发MCP+LangGraph的演示代码
dev_task = Task(
description=f"""1. 基于研究员的调研报告,开发一个"天气查询智能体"演示代码;
2. 集成MCP天气服务和LangGraph工作流;
3. 代码需包含注释,提供运行步骤和依赖清单""",
agent=developer,
expected_output="完整的Python代码文件,含requirements.txt和README.md内容"
)
# 任务3:测试并优化代码
test_task = Task(
description="""1. 测试开发工程师提供的代码,检查是否能正常运行;
2. 模拟3种异常场景(如无效城市、API密钥错误、网络超时)测试鲁棒性;
3. 提供测试报告和代码优化建议""",
agent=tester,
expected_output="测试报告(含测试用例、结果)和优化后的代码片段"
)
# 4. 组建智能体团队并运行
ai_dev_crew = Crew(
agents=[researcher, developer, tester],
tasks=[research_task, dev_task, test_task],
process=Process.sequential, # 顺序执行任务
llm=llm,
verbose=True
)
# 启动团队协作
results = ai_dev_crew.kickoff(inputs={"topic": "MCP协议在AI智能体中的应用"})
# 输出最终结果
print("="*50)
print("多智能体协作最终成果:")
print(results)
智能体性能优化与监控
企业级应用必须关注"响应速度"“成本控制”"错误率"三大核心指标,以下是实战方案。
- 响应时间优化:工具调用异步化、缓存高频查询结果、选择合适的模型(简单任务用GPT-3.5)
- 成本控制:限制单轮对话的token数、对大模型输出做截断、用开源模型(如Llama 3)做本地部署
- 监控告警:记录工具调用成功率、响应时间、错误类型,异常时触发邮件/钉钉告警
# 智能体性能监控与优化工具
import time
import json
from datetime import datetime
from functools import wraps
# 1. 性能监控装饰器
def agent_perf_monitor(monitor_file="agent_perf.log"):
"""监控智能体函数的性能:耗时、成功率、错误信息"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
# 记录开始时间和请求参数
start_time = time.time()
func_name = func.__name__
params = {"args": str(args[:2]), "kwargs": str({k: v for k, v in kwargs.items() if k != "api_key"})}
try:
# 执行被装饰函数
result = await func(*args, **kwargs)
end_time = time.time()
# 记录成功日志
log_data = {
"time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"function": func_name,
"status": "success",
"duration": round(end_time - start_time, 2),
"params": params,
"error": ""
}
return result
except Exception as e:
end_time = time.time()
# 记录错误日志
log_data = {
"time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"function": func_name,
"status": "failed",
"duration": round(end_time - start_time, 2),
"params": params,
"error": str(e)[:100]
}
# 触发告警(这里简化为打印,实际可对接钉钉/邮件API)
print(f"⚠️ 智能体调用失败:{func_name},错误:{str(e)[:50]}")
raise
finally:
# 写入日志文件
with open(monitor_file, "a", encoding="utf-8") as f:
f.write(json.dumps(log_data, ensure_ascii=False) + "\n")
return wrapper
return decorator
# 2. 结果缓存装饰器(优化重复查询)
def result_cache(cache_file="agent_cache.json", expire_seconds=3600):
"""缓存函数结果,避免重复调用耗时操作"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
# 生成缓存键(基于函数名和参数)
cache_key = f"{func.__name__}_{str(args)}_{str(kwargs)}"
# 读取缓存
try:
with open(cache_file, "r", encoding="utf-8") as f:
cache = json.load(f)
except (FileNotFoundError, json.JSONDecodeError):
cache = {}
# 检查缓存是否有效
now = time.time()
if cache_key in cache:
cache_data = cache[cache_key]
if now - cache_data["timestamp"] < expire_seconds:
print(f"📦 使用缓存:{cache_key}")
return cache_data["result"]
# 执行函数并缓存结果
result = await func(*args, **kwargs)
cache[cache_key] = {
"timestamp": now,
"result": result
}
# 写入缓存
with open(cache_file, "w", encoding="utf-8") as f:
json.dump(cache, f, ensure_ascii=False)
return result
return wrapper
return decorator
# 3. 优化后的智能体工具调用
@agent_perf_monitor() # 性能监控
@result_cache(expire_seconds=1800) # 缓存30分钟
async def call_weather_tool(city: str, api_key: str):
"""优化后的MCP天气工具调用"""
weather_tool = SecuredWeatherTool(city=city, api_key=api_key)
return await weather_tool.run()
# 测试:重复调用会使用缓存,失败会记录日志
if __name__ == "__main__":
# 第一次调用:执行实际逻辑并缓存
asyncio.run(call_weather_tool(city="北京", api_key="dev_key_001"))
# 第二次调用:使用缓存
asyncio.run(call_weather_tool(city="北京", api_key="dev_key_001"))
# 错误调用:记录错误日志并告警
asyncio.run(call_weather_tool(city="无效城市", api_key="wrong_key"))
学习资源与避坑指南(新手必看)
1. 核心学习资源
- Python进阶:《流畅的Python》第2版(重点看第7-10章)、B站"黑马程序员Python异步编程"教程
- AI API:OpenAI官方文档(有中文版本)、LangChain中文网(https://www.langchain.com.cn/)
- MCP协议:GitHub官方仓库(modelcontextprotocol/mcp)、优快云专栏"AI智能体开发实战"
- LangGraph:LangGraph官方文档(带交互式示例)、YouTube"LangChain Developer"频道
2. 新手避坑技巧
- 不要一开始就啃大模型源码:先用API实现功能,再深入原理,避免劝退
- 工具调用先模拟后实战:开发初期用固定返回值模拟工具结果,验证流程通了再对接真实API
- 控制学习范围:先掌握OpenAI+LangChain+MCP的组合,再扩展到多智能体和开源模型
- 坚持做小项目:每周一个小demo(如天气查询、文档总结),比单纯看文档效率高10倍
AI智能体开发是"编程能力+AI思维"的结合,这条路径从基础到实战,层层递进,只要跟着练完每个阶段的项目,3-4个月就能具备独立开发智能体应用的能力。收藏本文,跟着节奏学,下次开发AI应用时就能直接拿来当手册用!如果在学习中遇到具体问题,欢迎在评论区留言讨论。
小白/程序员如何系统学习大模型LLM?
作为在一线互联网企业深耕十余年的技术老兵,我经常收到小白和程序员朋友的提问:“零基础怎么入门大模型?”“自学没有方向怎么办?”“实战项目怎么找?”等问题。难以高效入门。
这里为了帮助大家少走弯路,我整理了一套全网最全最细的大模型零基础教程。涵盖入门思维导图、经典书籍手册、实战视频教程、项目源码等核心内容。免费分享给需要的朋友!

👇👇扫码免费领取全部内容👇👇

1、我们为什么要学大模型?
很多开发者会问:大模型值得花时间学吗?答案是肯定的——学大模型不是跟风追热点,而是抓住数字经济时代的核心机遇,其背后是明确的行业需求和实打实的个人优势:
第一,行业刚需驱动,并非突发热潮。大模型是AI规模化落地的核心引擎,互联网产品迭代、传统行业转型、新兴领域创新均离不开它,掌握大模型就是拿到高需求赛道入场券。
第二,人才缺口巨大,职业机会稀缺。2023年我国大模型人才缺口超百万,2025年预计达400万,具备相关能力的开发者岗位多、薪资高,是职场核心竞争力。
第三,技术赋能增效,提升个人价值。大模型可大幅提升开发效率,还能拓展职业边界,让开发者从“写代码”升级为“AI解决方案设计者”,对接更高价值业务。
对于开发者而言,现在入门大模型,不仅能搭上行业发展的快车,还能为自己的职业发展增添核心竞争力——无论是互联网大厂的AI相关岗位,还是传统行业的AI转型需求,都在争抢具备大模型技术能力的人才。


人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
2、大模型入门到实战全套学习大礼包分享
最后再跟大家说几句:只要你是真心想系统学习AI大模型技术,这份我耗时许久精心整理的学习资料,愿意无偿分享给每一位志同道合的朋友。
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
部分资料展示
2.1、 AI大模型学习路线图,厘清要学哪些
对于刚接触AI大模型的小白来说,最头疼的问题莫过于“不知道从哪学起”,没有清晰的方向很容易陷入“东学一点、西补一块”的低效困境,甚至中途放弃。
为了解决这个痛点,我把完整的学习路径拆解成了L1到L4四个循序渐进的阶段,从最基础的入门认知,到核心理论夯实,再到实战项目演练,最后到进阶优化与落地,每一步都明确了学习目标、核心知识点和配套实操任务,带你一步步从“零基础”成长为“能落地”的大模型学习者。后续还会陆续拆解每个阶段的具体学习内容,大家可以先收藏起来,跟着路线逐步推进。

L1级别:大模型核心原理与Prompt
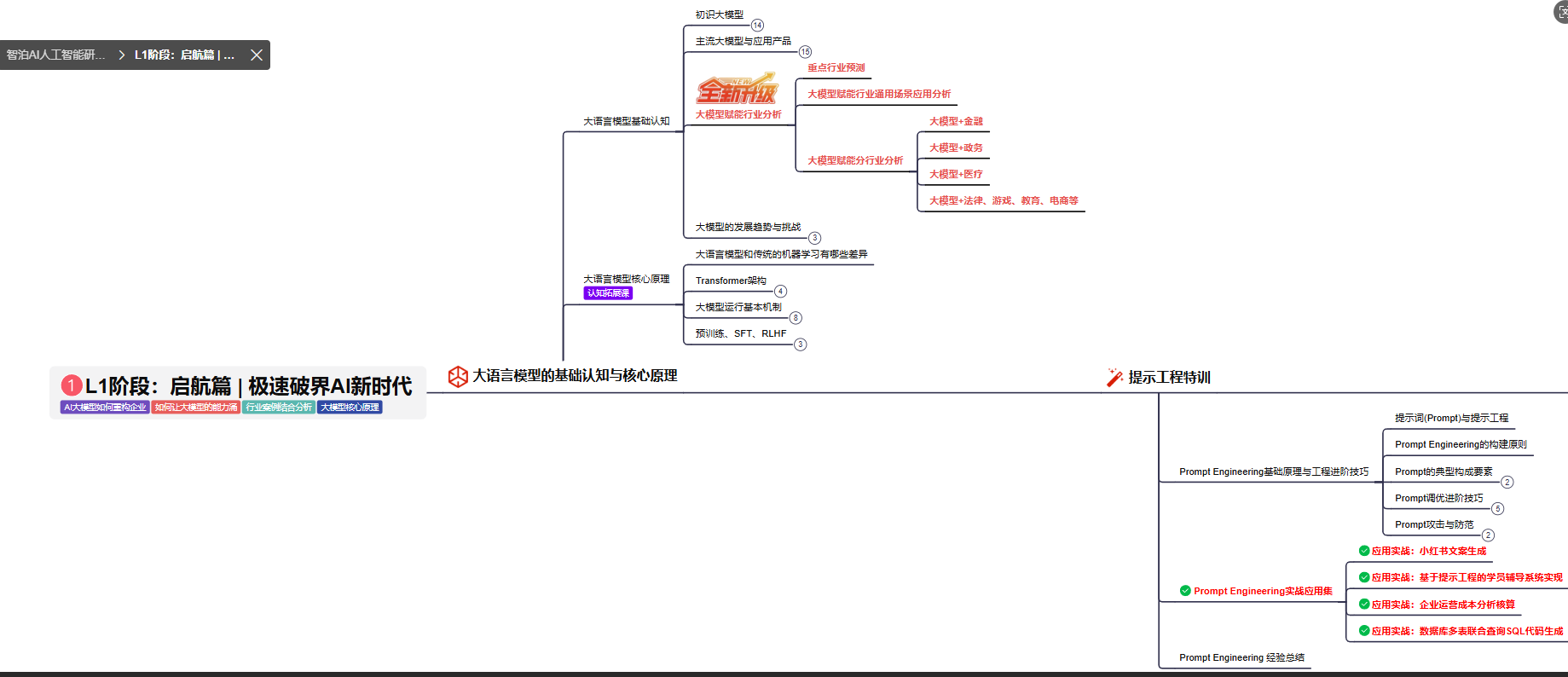
L1阶段: 将全面介绍大语言模型的基本概念、发展历程、核心原理及行业应用。从A11.0到A12.0的变迁,深入解析大模型与通用人工智能的关系。同时,详解OpenAl模型、国产大模型等,并探讨大模型的未来趋势与挑战。此外,还涵盖Pvthon基础、提示工程等内容。
目标与收益:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为AI应用开发打下坚实基础。
L2级别:RAG应用开发工程
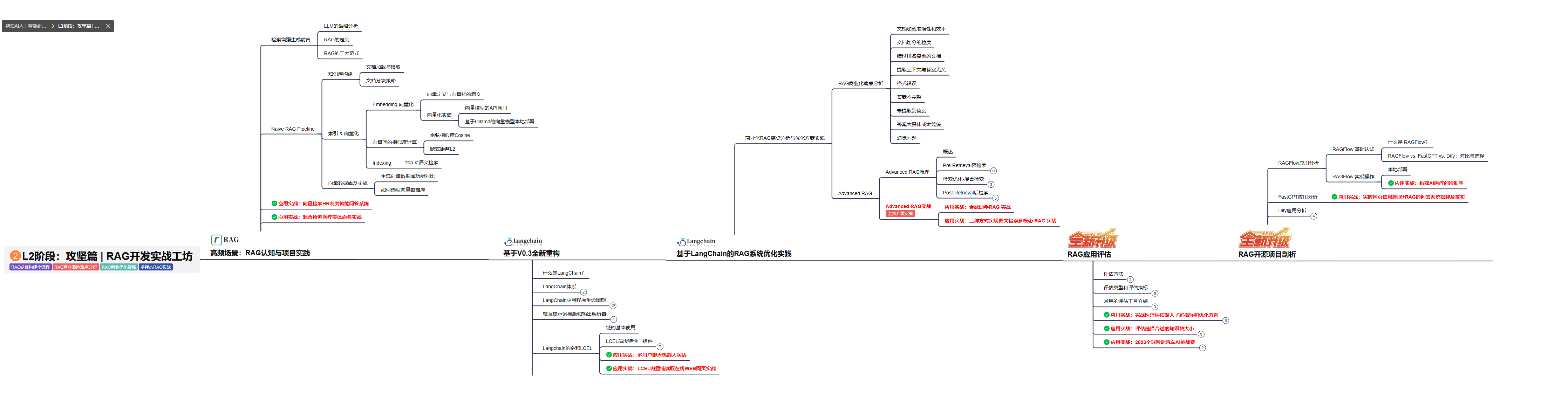
L2阶段: 将深入讲解AI大模型RAG应用开发工程,涵盖Naive RAGPipeline构建、AdvancedRAG前治技术解读、商业化分析与优化方案,以及项目评估与热门项目精讲。通过实战项目,提升RAG应用开发能力。
目标与收益: 掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
L3级别:Agent应用架构进阶实践
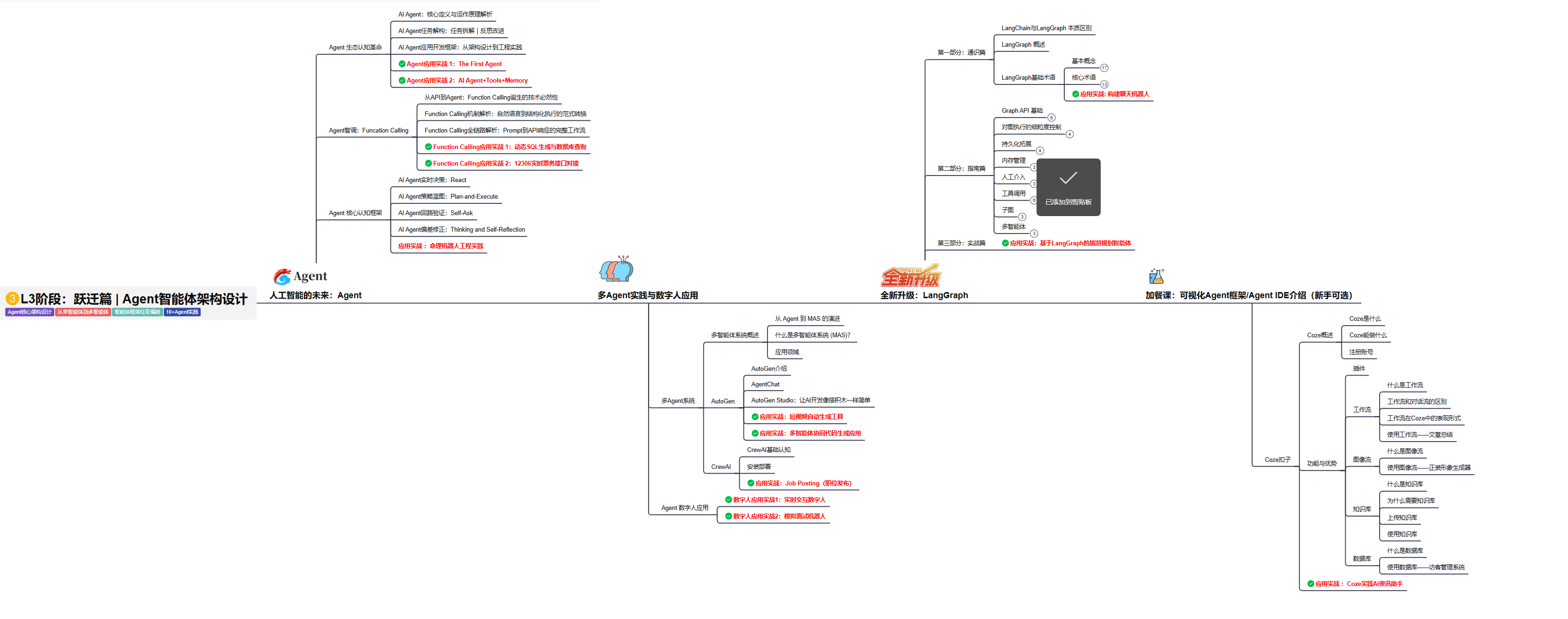
L3阶段: 将 深入探索大模型Agent技术的进阶实践,从Langchain框架的核心组件到Agents的关键技术分析,再到funcation calling与Agent认知框架的深入探讨。同时,通过多个实战项目,如企业知识库、命理Agent机器人、多智能体协同代码生成应用等,以及可视化开发框架与IDE的介绍,全面展示大模型Agent技术的应用与构建。
目标与收益:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
L4级别:模型微调与私有化大模型
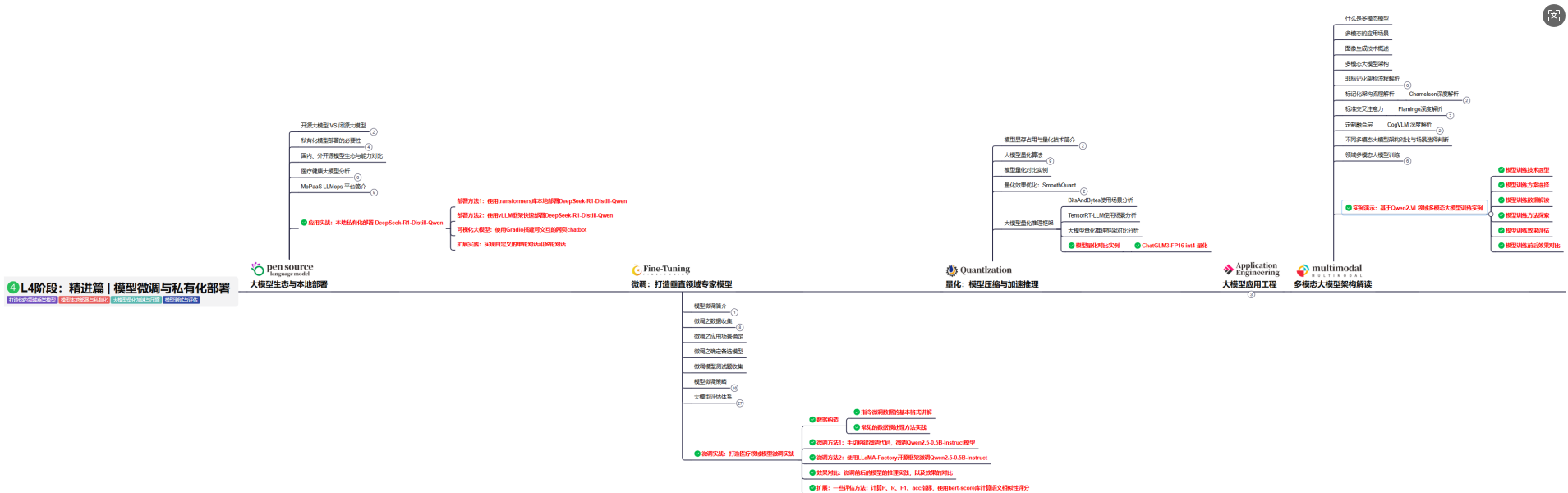
L4级别: 将聚焦大模型微调技术与私有化部署,涵盖开源模型评估、微调方法、PEFT主流技术、LORA及其扩展、模型量化技术、大模型应用引警以及多模态模型。通过chatGlM与Lama3的实战案例,深化理论与实践结合。
目标与收益:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。
2.2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

2.3、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

2.4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

2.5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

2.6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









