



手把手带你了解Redis分布式锁
一、情境:一场注定“超卖”的抢购
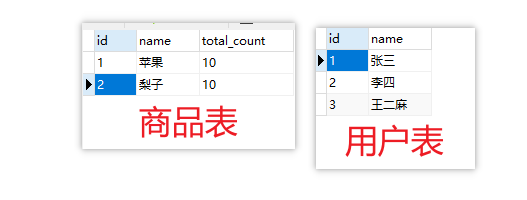
在电商系统中,搞了一场火爆的限时抢购活动,一群吃瓜群众们在疯狂抢购苹果和梨子,但是水果的数量有限,用户每次只能买一件水果,简单的DB表如下:
- 商品: 苹果 ,梨子各有10个库存
- 用户: 张三、李四、王二麻
抢购时间到了,用户们开始疯狂下单了,让我们看看会发生什么?
/**
* 用户下单接口
* @param userId: 用户ID
* @param goodsId: 商品ID
*/
@PostMapping("/sub_stock/{userId}/{goodsId}")
public void subStock(@PathVariable("userId") String userId, @PathVariable("goodsId") String goodsId) {
testBiz.subStock(userId, goodsId);
}
1. 单机版无锁抢购
代码如下:
public void subStock(String userId, String goodsId) {
Goods goods = goodsService.selectById(goodsId);
if(goods != null) {
String totalCount = goods.getTotalCount();
// 判断库存是否大于0
if(Integer.parseInt(totalCount) > 0) {
// 创建订单
Orders orders = new Orders();
orders.setId(UUID.randomUUID().toString());
orders.setUserId(userId);
orders.setGoodsId(goodsId);
orders.setCount("1");
ordersService.save(orders);
// 扣减库存
totalCount = String.valueOf(Integer.parseInt(totalCount) - 1);
goods.setTotalCount(totalCount);
goodsService.update(goods);
System.out.println("用户:" + userId + " 购买了:" + goodsId);
}
}
}
使用Jmeter同时调用接口,线程数为10,循环3次
/test/sub_stock/1/1
/test/sub_stock/2/1
/test/sub_stock/3/1
/test/sub_stock/1/2
/test/sub_stock/2/2
/test/sub_stock/3/2
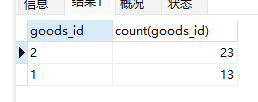
查下DB,看下库存情况和订单情况:
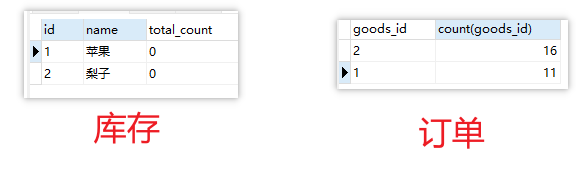
这里可以看到,库存清空了,但是两个商品都超卖了,显然是有问题的。
于是,我们给单机版的加锁,来应对超卖问题。
2. 单机版加锁抢购
代码如下:
public void subStock(String userId, String goodsId) {
synchronized (this) {
Goods goods = goodsService.selectById(goodsId);
if(goods != null) {
String totalCount = goods.getTotalCount();
if(Integer.parseInt(totalCount) > 0) {
Orders orders = new Orders();
orders.setId(UUID.randomUUID().toString());
orders.setUserId(userId);
orders.setGoodsId(goodsId);
orders.setCount("1");
ordersService.save(orders);
totalCount = String.valueOf(Integer.parseInt(totalCount) - 1);
goods.setTotalCount(totalCount);
goodsService.update(goods);
System.out.println("用户:" + userId + " 购买了:" + goodsId);
}
}
}
}
代码很简单,就是加了synchronized锁,保证同一时刻只有一个线程可以进行抢购的操作。使用Jmeter后,再来查询下订单表的情况,如下图所示。从图中可以看出,两个商品都正好卖完了,并没有存在超卖的情况,符合我们的预期。
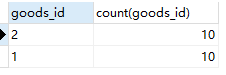
3. 分布式+synchronized抢购
3.1 尝试抢购
但是单机版的性能是有限的,无法很好的应对高并发的场景,于是,我们为了应对高并发流量,这个服务被部署在了三台服务器上:WebApplication1, WebApplication2, WebApplication3。

代码如下:
public void subStock(String userId, String goodsId) {
synchronized (this) {
Goods goods = goodsService.selectById(goodsId);
if(goods != null) {
String totalCount = goods.getTotalCount();
if(Integer.parseInt(totalCount) > 0) {
Orders orders = new Orders();
orders.setId(UUID.randomUUID().toString());
orders.setUserId(userId);
orders.setGoodsId(goodsId);
orders.setCount("1");
ordersService.save(orders);
totalCount = String.valueOf(Integer.parseInt(totalCount) - 1);
goods.setTotalCount(totalCount);
goodsService.update(goods);
System.out.println("用户:" + userId + " 购买了:" + goodsId);
}
}
}
}
从代码中可以看出,并没有什么变化,唯一的区别就是由单机变成了3台服务同时处理请求,那看下抢购的情况吧~
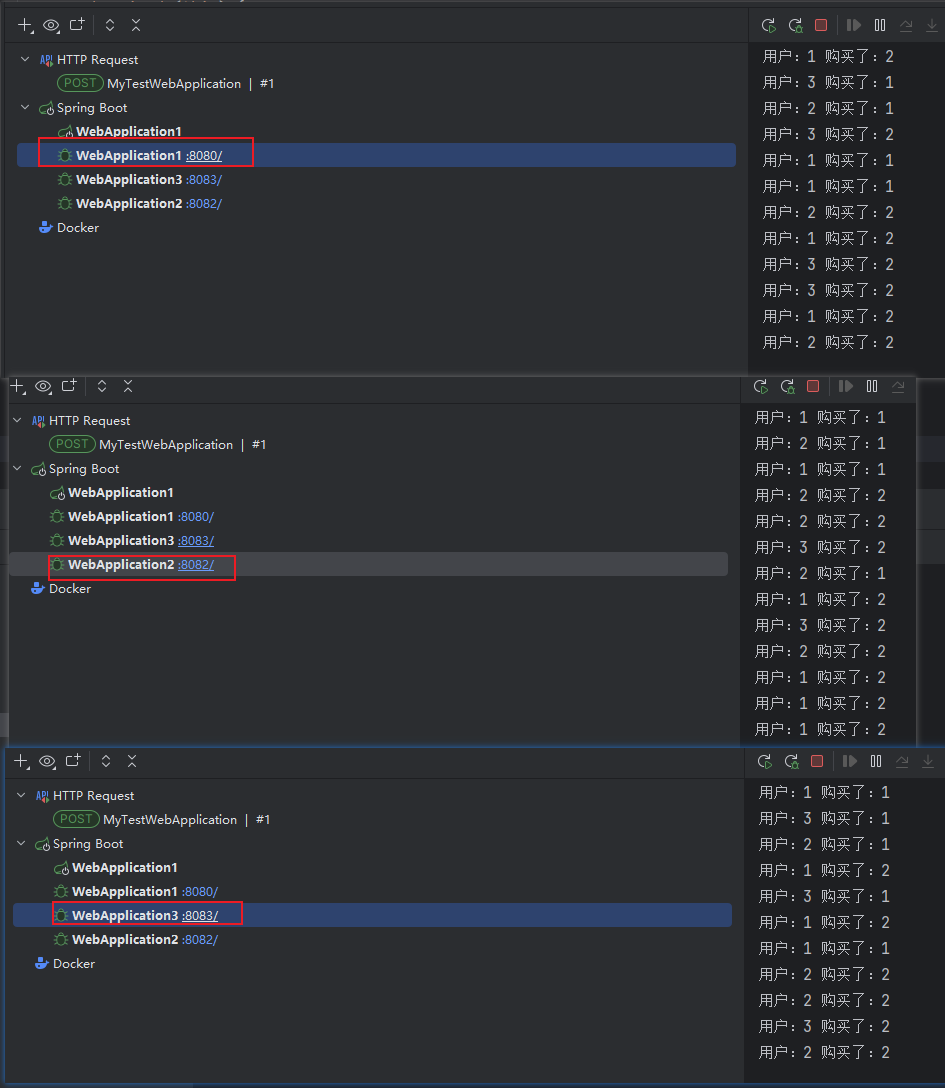
3.2 依然超卖
从控制台的输出可以看出,3台服务都处理了一些请求,即使加了synchronized 锁,但是商品依旧超卖了。
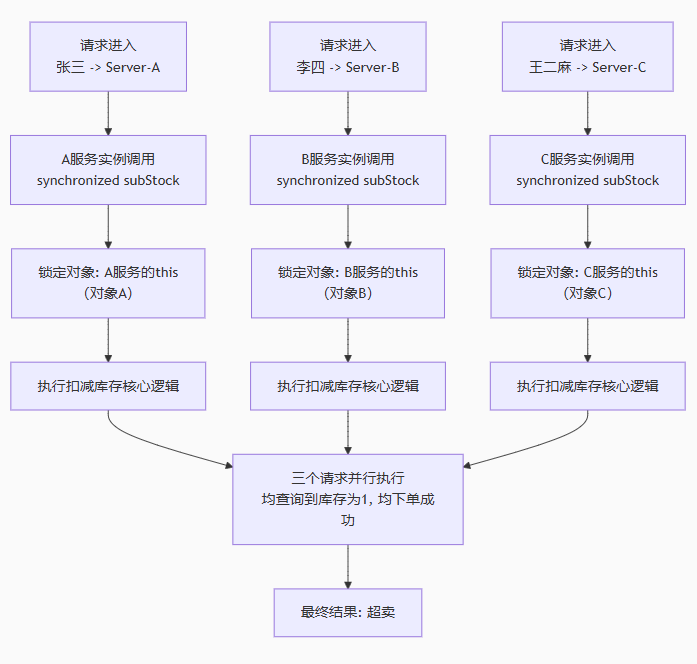
假设苹果只剩最后1个。张三的请求到达 Server-A,李四的请求到达 Server-B,王二麻的请求到达 Server-C。
- 几乎同时,三台服务器都执行了
goodsService.selectById("goods_id"),它们都查询到库存totalCount = 1。 - 判断都通过
(1 > 0),于是都开始创建订单、扣减库存。 - 三台服务器分别计算:
1 - 1 = 0,并将库存0更新回数据库。 - 最终结果是:生成了3个订单,但库存只扣减了1次。苹果被超卖了!公司血亏,活动失败。
3.3 为什么synchronized 在分布式的场景中不起效果呢?
3.3.1 核心原因:作用域不同
synchronized 是单机锁(线程锁),而分布式锁是全局锁(进程锁)。
synchronized 的作用域是 单个Java虚拟机(JVM)进程。它只能保证在这个JVM内部,多个线程之间互斥地访问共享资源。
分布式锁 的作用域是 所有服务实例。它保证在跨机器、跨进程的整个分布式系统中,只有一个进程的线程能访问共享资源。
可以把它们想象成:
synchronized 就像一栋楼里每个房间的门锁。它只能防止同一个房间(JVM)里的其他人(线程)进来,但管不了其他楼(其他服务器)里的人也进来拿东西。
分布式锁 就像这整个小区的唯一的通行证。无论你来自哪栋楼,只有拿到这个通行证的人,才能进入房间拿东西。
3.3.2 分析执行过程:
独立的 JVM 进程:
Server-A 启动,是一个独立的JVM进程。它加载 SecKillService 类,并在内存中有一个该类的实例。
Server-B 启动,是另一个完全独立的JVM进程。它同样加载 SecKillService 类,但在自己的内存中有另一个独立的实例。
Server-C 同理。
锁的是不同的对象:
synchronized 实例方法锁的是当前对象实例(this)。
当张三的请求进入 Server-A,它会获取 Server-A 的JVM中那个 SecKillService 实例的锁。
当李四的请求进入 Server-B,它会去获取 Server-B 的JVM中那个完全不同的 SecKillService 实例的锁。这个锁和 Server-A 的锁毫无关系。
王二麻的请求在 Server-C 也是同样的情况。
并行执行,而非互斥:
因为三把锁锁的是三个不同的对象,存在于三个不同的内存空间中,所以获取锁这个动作不存在任何竞争。
张三、李四、王二麻的请求在各自的服务器上都成功地获取到了自己服务器的锁,然后并行地执行查询库存、判断、下单的逻辑。
它们都会查询到库存为1,然后都成功下单,最终导致超卖。
3.3.3 问题根源
在分布式(多实例部署)环境下,传统的单机锁(如Java的synchronized)完全失效,因为它们只能锁住自己所在的JVM进程。我们需要一个所有服务实例都能访问和认可的全局锁来协调资源。
二、救世主登场:什么是分布式锁?
分布式锁是分布式系统或集群环境中,用于控制不同进程互斥访问共享资源的一种协调技术。
它的核心思想是:在一个所有进程都能访问的地方,设置一个标志(锁),大家一起来抢这个标志,谁抢到了,谁就有权执行后续操作。
实现分布式锁的方式有很多,如基于数据库、ZooKeeper、Etcd等。而 Redis 因其高性能、原子操作和丰富的数据结构,成为了实现分布式锁的最热门选择之一。
三、Redis(Redisson)分布式锁核心实现
1. Redisson分布式锁代码实现
这里直接使用了Redisson作为分布式锁,下面看下代码的实现,也是比较简单粗暴。
@Autowired
RedissonClient redissonClient;
public void subStock(String userId, String goodsId) {
RLock lock = redissonClient.getLock(goodsId);
lock.lock(60, TimeUnit.SECONDS);
try {
Goods goods = goodsService.selectById(goodsId);
if(goods != null) {
String totalCount = goods.getTotalCount();
if(Integer.parseInt(totalCount) > 0) {
Orders orders = new Orders();
orders.setId(UUID.randomUUID().toString());
orders.setUserId(userId);
orders.setGoodsId(goodsId);
orders.setCount("1");
ordersService.save(orders);
totalCount = String.valueOf(Integer.parseInt(totalCount) - 1);
goods.setTotalCount(totalCount);
goodsService.update(goods);
System.out.println("用户:" + userId + " 购买了:" + goodsId);
}
}
}catch (Exception e) {
}finally {
lock.unlock();
}
}
2. Redisson原理
我们来深入剖析一下 Redisson 实现分布式锁的原理。它远比我们自己用 SETNX 实现的简单锁要强大和复杂得多。
Redisson 的分布式锁(RLock)实现了 java.util.concurrent.locks.Lock 接口,这意味着它的使用方式和Java自带的可重入锁(ReentrantLock)非常相似,但背后却是一套完善的分布式协调机制。
其核心原理可以概括为:Lua脚本 + 看门狗机制 + Pub/Sub发布订阅。
3. 核心加锁逻辑
当我们调用 lock.lock() 时,Redisson 在背后做了以下事情:
使用 Lua 脚本保证原子性,加锁的核心操作是通过一个 Lua 脚本完成的,这确保了多个操作的原子性,是安全性的基石。脚本的 key 是锁的名称(如 my_lock),value 是一个 UUID + 线程ID 的唯一标识(如 b983c153-ae1c-4d2a-8a3a-f6a6d8d6c7a1:1)。
Lua 脚本逻辑如下:
-- KEYS[1]: 锁的key (e.g., 'my_lock')
-- ARGV[1]: 锁的过期时间 (毫秒) (e.g., 30000)
-- ARGV[2]: 唯一客户端标识 (UUID + threadId) (e.g., 'b983c153-ae1c-4d2a-8a3a-f6a6d8d6c7a1:1')
-- 1. 判断锁是否存在
if (redis.call('exists', KEYS[1]) == 0) then
-- 2. 不存在,直接加锁。创建一个哈希结构,并设置重入次数为1。
redis.call('hset', KEYS[1], ARGV[2], 1);
-- 3. 设置锁的过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil; -- 加锁成功,返回nil
end;
-- 4. 锁已存在,检查是否是当前线程持有的
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
-- 5. 是当前线程,重入次数+1
redis.call('hincrby', KEYS[1], ARGV[2], 1);
-- 6. 重置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil; -- 重入成功,返回nil
end;
-- 7. 锁被其他线程持有,返回该锁的剩余生存时间(毫秒)
return redis.call('pttl', KEYS[1]);
这个脚本一次性完成了所有关键操作:
- 互斥性:
exists命令判断锁是否存在。 - 可重入性:使用 Hash 结构,
key是锁名,field是客户端唯一ID,value是重入次数。hexists和hincrby实现了可重入计数。 - 防死锁:
pexpire设置了锁的过期时间。
如果加锁成功,当前线程就获得了锁,可以执行业务代码。
4、看门狗机制(Watchdog)—— 自动续期
这是 Redisson 的一大亮点,解决了锁过期时间设置难题。
- 问题:如果设置过期时间太短,业务没执行完锁就释放了,会导致数据混乱。如果设置太长,客户端崩溃后恢复时间又太长。
- 解决方案:看门狗。
- 默认行为:如果你没有指定
leaseTime(锁的租约时间)而直接调用lock(),看门狗就会启动。 - 工作机制:锁默认的过期时间是 30秒。看门狗是一个后台定时任务,它会每隔 10秒(过期时间的1/3)检查一下当前线程是否还持有锁。
- 自动续期:如果业务还在执行(即线程还持有锁),看门狗就会再次通过 Lua 脚本将锁的过期时间重置为30秒。
- 释放停止:一旦业务执行完毕,调用
lock.unlock()释放了锁,看门狗任务就会自动取消。
这样就实现了“只要业务还在运行,锁就不会过期”的理想状态,完美避免了业务执行时间超过锁超时时间的问题。
注意:如果你调用
lock.lock(10, TimeUnit.SECONDS)显式指定了租约时间,看门狗就不会生效,Redis 会在 10 秒后自动删除 key。
5、阻塞与竞争锁的机制(Pub/Sub)
如果锁已经被其他客户端持有,当前客户端加锁会失败。Redisson 如何处理竞争呢?它没有采用低效的循环重试(自旋),而是使用了高效的 发布订阅(Pub/Sub) 模型。
- 订阅频道:当尝试加锁失败后,客户端并不会立即重试,而是会订阅 Redis 中的一个特定频道(Channel),这个频道的名字与锁的名称相关(例如
redisson_lock__channel:{my_lock})。 - 进入等待:线程进入等待状态,不消耗CPU资源。
- 接收通知:当其他线程释放锁时(通过
DEL命令),Redisson 会向这个频道发布一条消息:“锁被释放了!” - 唤醒重试:所有订阅了这个频道的客户端都会收到消息,然后被唤醒,重新尝试去获取锁。
这个过程极大地减少了不必要的 Redis 请求,避免了网络和CPU资源的浪费,尤其是在高并发抢锁的场景下优势非常明显。
6、解锁逻辑
解锁操作 lock.unlock() 同样通过 Lua 脚本来保证原子性。
Lua 脚本逻辑如下:
-- KEYS[1]: 锁的key
-- KEYS[2]: 发布订阅的channel name
-- ARGV[1]: 发布的消息 (一般是0, 代表解锁消息)
-- ARGV[2]: 锁的过期时间
-- ARGV[3]: 唯一客户端标识 (UUID + threadId)
-- 1. 检查锁是否存在,且持有者是不是当前线程
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil; -- 锁不存在或不是自己的锁,直接返回(可能已过期)
end;
-- 2. 是自己的锁,重入次数减1
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
-- 3. 重入次数减1后还大于0,说明是重入锁,尚未完全释放。重置过期时间。
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
-- 4. 重入次数已为0,可以删除锁了
redis.call('del', KEYS[1]);
-- 5. 向发布订阅频道发送消息,通知其他等待的客户端“锁已释放”
redis.call('publish', KEYS[2], ARGV[1]);
return 1; -- 完全释放成功
end;
return nil;
这个脚本确保了:
- 安全性:只有锁的持有者才能释放锁。
- 可重入性:必须等重入次数减到0才会真正删除锁。
- 高效性:通过发布消息,立即通知等待的客户端,而不是让他们盲目重试。
总结:Redisson 分布式锁的优势
| 特性 | 简单 SETNX 实现 | Redisson 实现 |
|---|---|---|
| 可重入性 | 不支持,同一线程重复获取会死锁 | 支持,通过 Hash 结构记录重入次数 |
| 锁续期 | 不支持,需业务方预估超时时间 | 支持 (看门狗),自动续期,防止业务未执行完锁过期 |
| 等待机制 | 自旋,循环重试,浪费资源 | Pub/Sub,订阅通知,高效节能 |
| 原子性 | 多个命令,非绝对原子 | Lua 脚本,所有操作原子执行 |
| 易用性 | 低,需要自己处理所有细节 | 高,实现了 Java Lock 接口,用法和本地锁一致 |
因此,在生产环境中,强烈推荐使用 Redisson 这类成熟框架来实现分布式锁,而不是自己重复造轮子,因为它提供了更完善的安全性、可靠性和易用性保障。
四、最终效果:秩序重归
让我们回到张三、李四、王二麻抢最后一个苹果的场景:
- 三个请求到达三台服务器。
- 它们同时尝试执行
lock.lock(60, TimeUnit.SECONDS);。 - 由于Redis的单线程特性,只有一个请求(假设是
Server-A上的张三)的SET命令会成功执行,获取到锁。李四和王二麻的请求获取失败,返回false。 - 只有张三的请求可以执行查询库存、创建订单、扣减库存的核心逻辑。
- 执行完毕后,张三的请求在
finally块中安全地释放了锁。 - 此时,锁被释放,其他正在等待的请求(如果有重试机制)可以再次尝试获取锁,但此时库存已是0。
结果:只产生了一个订单,库存正确地扣减为0。超卖问题被完美解决!
五、总结
我们实现了一个基础且健壮的Redis分布式锁,它具备了:
- 互斥性:利用
SET NX保证只有一个客户端能持有锁。 - 防死锁:通过设置过期时间
PX,即使客户端崩溃,锁也会自动释放。 - 安全性:使用Lua脚本和唯一Value,保证只有锁的持有者才能释放锁,避免误解锁。
希望这篇博客能帮助你彻底理解并上手Redis分布式锁,让你的分布式系统在高并发下也能保持数据的一致性!

















 5080
5080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









