




 本文详细探讨了C/C++编程中的内存操作,如索引内存、间接寻址、数据交换,以及四则运算(加减乘除)、位移(左移、右移)和逻辑运算。还涵盖了Bubble Sort算法及乘法溢出处理。
本文详细探讨了C/C++编程中的内存操作,如索引内存、间接寻址、数据交换,以及四则运算(加减乘除)、位移(左移、右移)和逻辑运算。还涵盖了Bubble Sort算法及乘法溢出处理。
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
第三章 Using Integer
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、操作内存
1.1 INDEXED MOEMORY MODE
索引访问内存。

base_address(offset_address,index,size)
1.2 INDIRECT ADDRESSING

movl $values, %edi #将values的地址赋值给edi寄存器
movl %ebx, (%edi) #将寄存器ebx中的值赋给以寄存器edi中数值作为地址指向的内存
#(%edi)用法是base_address(offset_address,index,size)演化而来,base_address为0,offset_address为%edi,index和size都为0,省略了。把寄存器%edi做指针用
movl $99, 4(%edi) #4也可以是负数
例子:
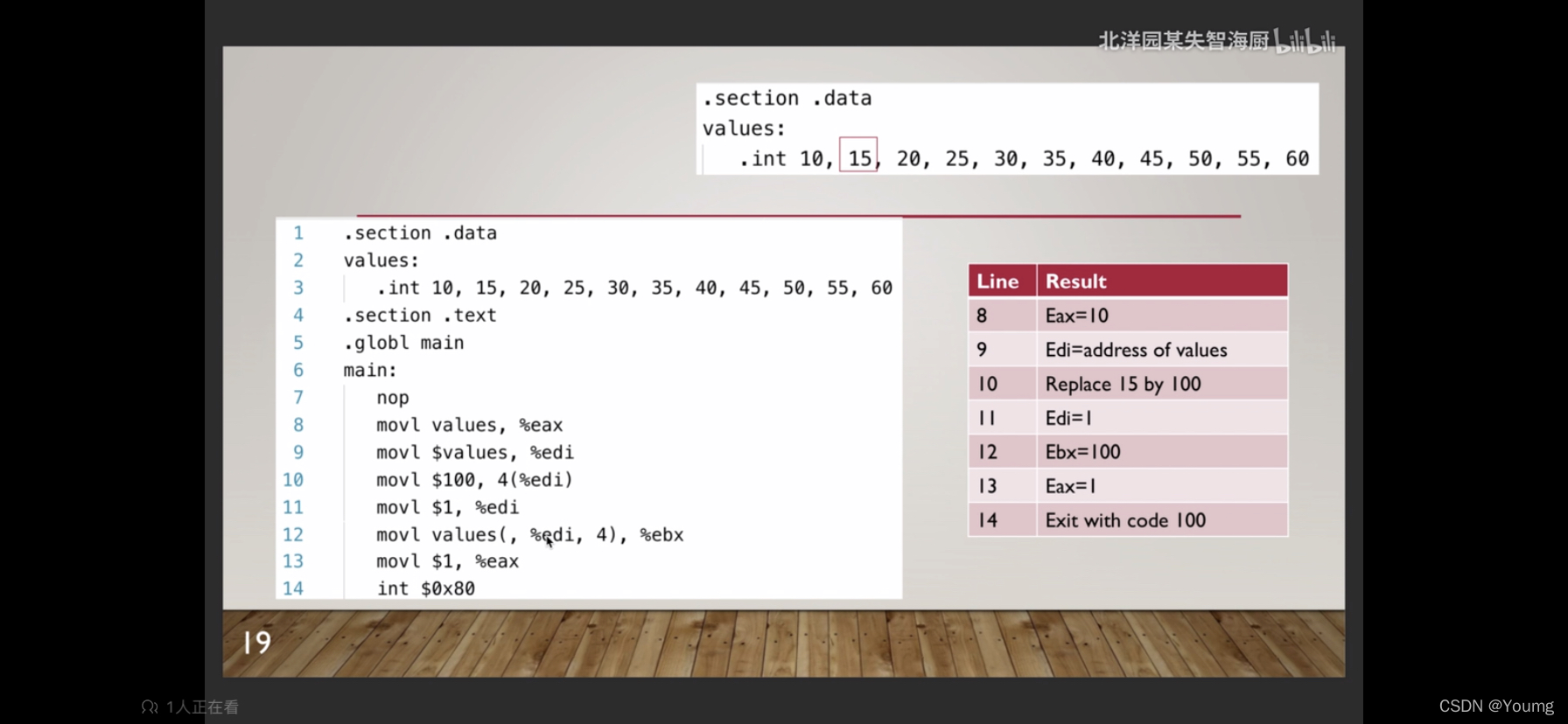
.section .data
output:
.ascii "The value is x\n"
values:
.int 1, 3, 5, 7, 9
.section .text
.globl main
main:
nop
movl $output, %esi # esi保存output的地址
movl $0, %edi
loop:
movl values(, %edi, 4), %eax
addl $0x30, %eax
movb %al, 13(%esi) # (%esi)取内存地址为%esi的值,4(%esi)取内存地址为%esi+4的值
movl $4, %eax # write
movl $1, %ebx # 输出到屏幕
movl $output, %ecx # 输出数据
movl $15, %edx # 输出长度
int $0x80 # 执行调用: write(1, output, 15)
inc %edi # 自增,等同于addl $1, %edi
cmpl $5, %edi # 比较,if (5 == %edi)
jne loop # jump to loop if not equal,即(5 != %edi)
movl $0, %ebx
movl $1, %eax # exit
int $0x80 # call exit(0), ebx保存返回值
1.3 DATA EXCHANGE
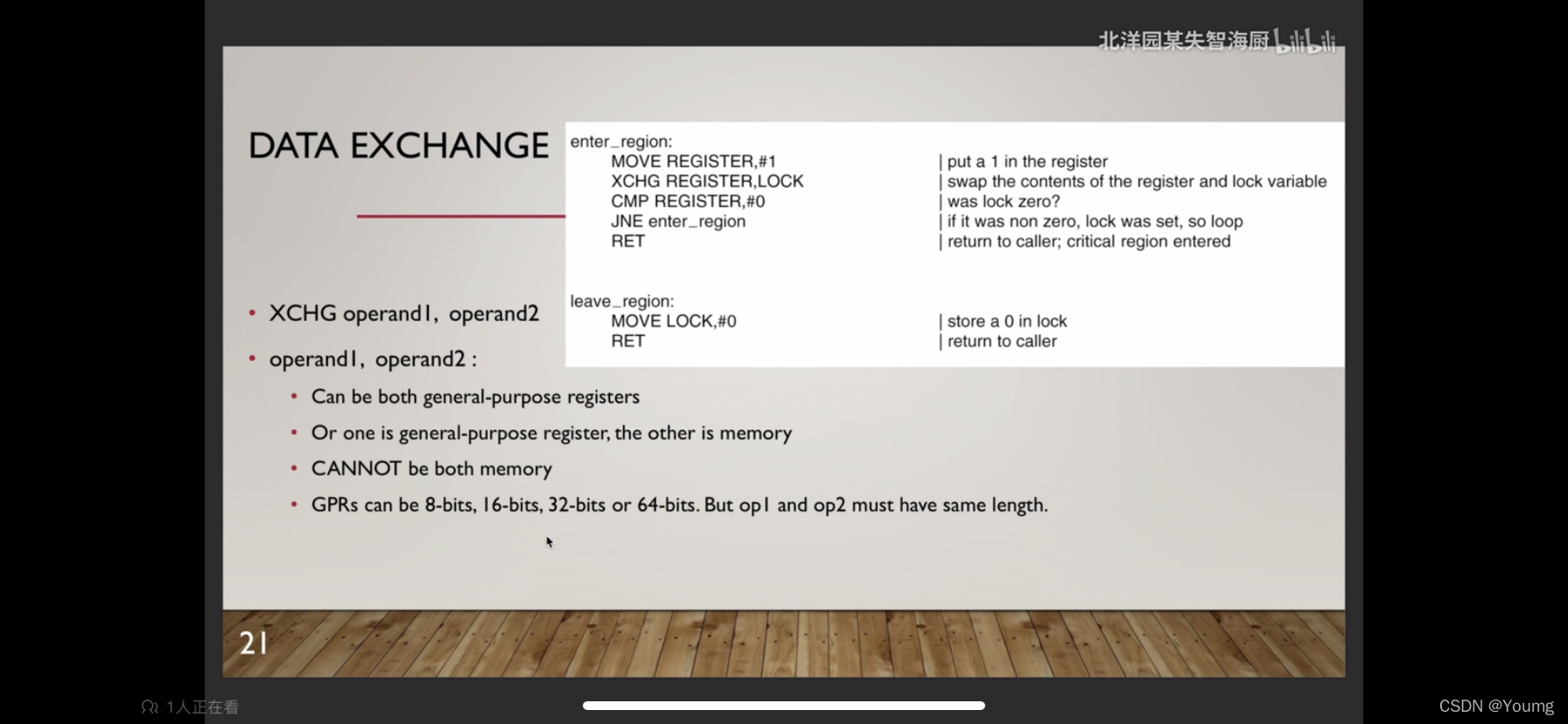
XCHG作为原子操作,可以解决并发访问时,不可控的时序问题。
同时在加锁时,判断如果未加锁,则加锁,但是判断过程也课程被其他并发打断。
if (lock等于0)
{
lock 等于1
}
判断和赋值是两个原子操作,线程A在判断的时候,线程B、C可能同时也在判断。
线程A加上锁对于线程B、C已经没有用了,因为他们已经判断,并认为未上锁。
而XCHG的原子操作可以解决这个上锁、判断会被打断的问题。
右上角的伪汇编是Intel格式写的,我用AT&T重新一遍并解释
enter_region:
movl $1, %ebx #
xchg lock, %ebx
cmp $0, %ebx
jne enter_region
ret
1.4 Bubble Sort

for (out = array_size - 1; out > 0; out--)
{
for (in = 0; in < out; in++)
{
if (array[in] > array[in+1])
{
swap(array[in], array[in+1]);
}
}
}
# bubble.s - An example of the XCHG instruction
.section .data
values:
.int 105, 235, 61, 315, 134, 221, 53, 145, 117, 5
.section .text
.globl main
main:
movl $values, %esi
movl $9, %ecx
movl $9, %ebx
loop:
movl (%esi), %eax
cmp %eax, 4(%esi)
jge skip
xchg %eax, 4(%esi)
movl %eax, (%esi)
skip:
add $4, %esi
dec %ebx
jnz loop
dec %ecx
jz end
movl $values, %esi
movl %ecx, %ebx
jmp loop
end:
movl $1, %eax
movl $0, $ebx
int $0x80
cmp source, destination,比较指令做desitination - source,但是结果不会放在destination中。只是会设置CF、OF、SF和ZF。
cmp之后用判断指令控制程序,例如je,jge等。

二、四则运算
2.1 ADD? source, destination
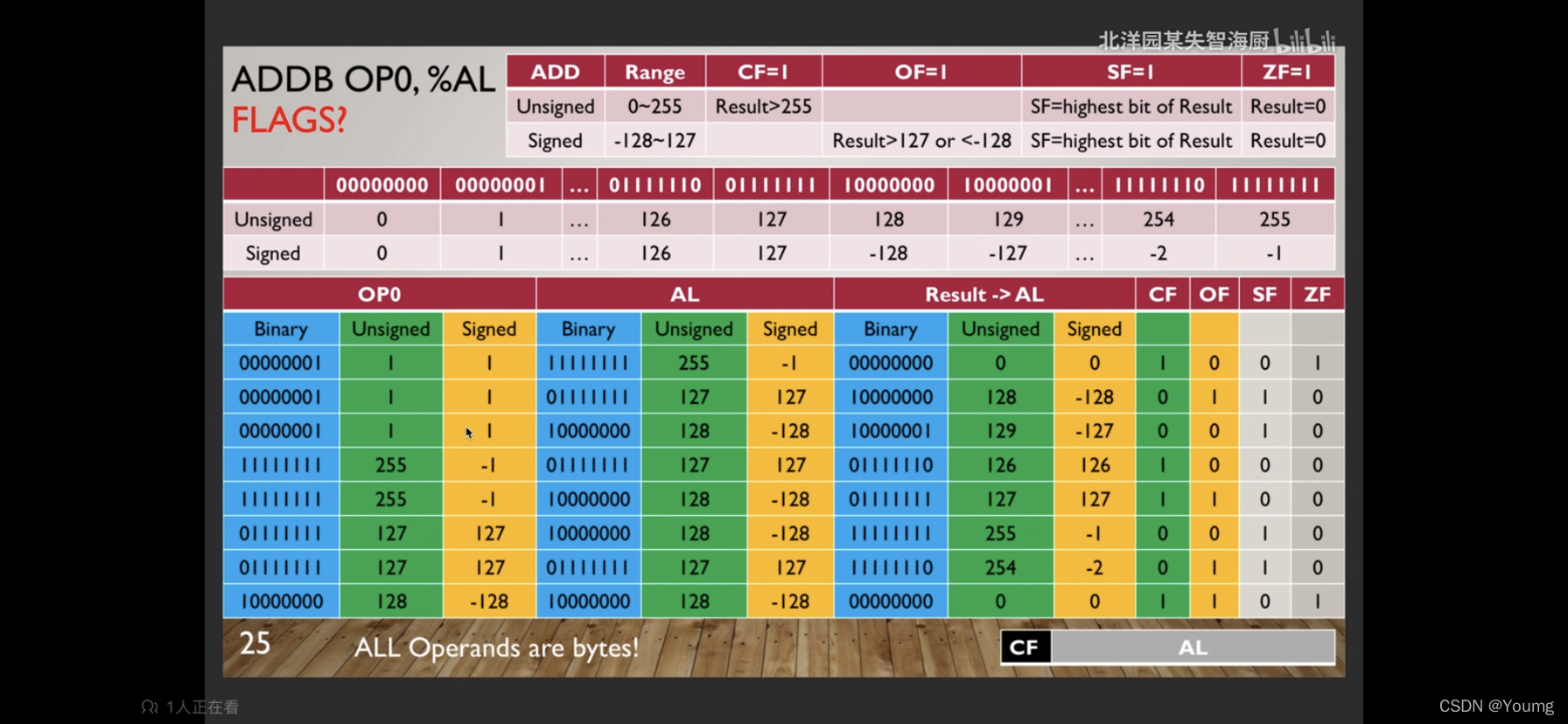
在加法计算过程中,如果将操作数都看作有符号数,则判断计算结果(数学结果)的范围是否超出指定位数,如果超出则OF置1。或者可以判断同号操作数相加,如果最高位符号变化,则认为Overflow了。
如果将操作数都看作无符号数,则判断计算结果(数学结果)的范围是否超出指定位数的无符号数范围,超出则CF置1。以8bits无符号数为例,可以把CF看作增加的最高位,第9bits。如果计算结果进位,即CF等于1。
SF:Sign Flag of Result
| Highest bit of Result | SF |
|---|---|
| 1 | 1 |
| 0 | 0 |
ZF:Zero Flag of Result
| Result | ZF |
|---|---|
| 0 | 1 |
| 非0 | 0 |
2.2 SUB? source, destination

inc?,dec?不修改CF,但是修改OF、SF和ZF
2.3 MULTIPLY
2.3.1 UNSIGNED MULTIPY
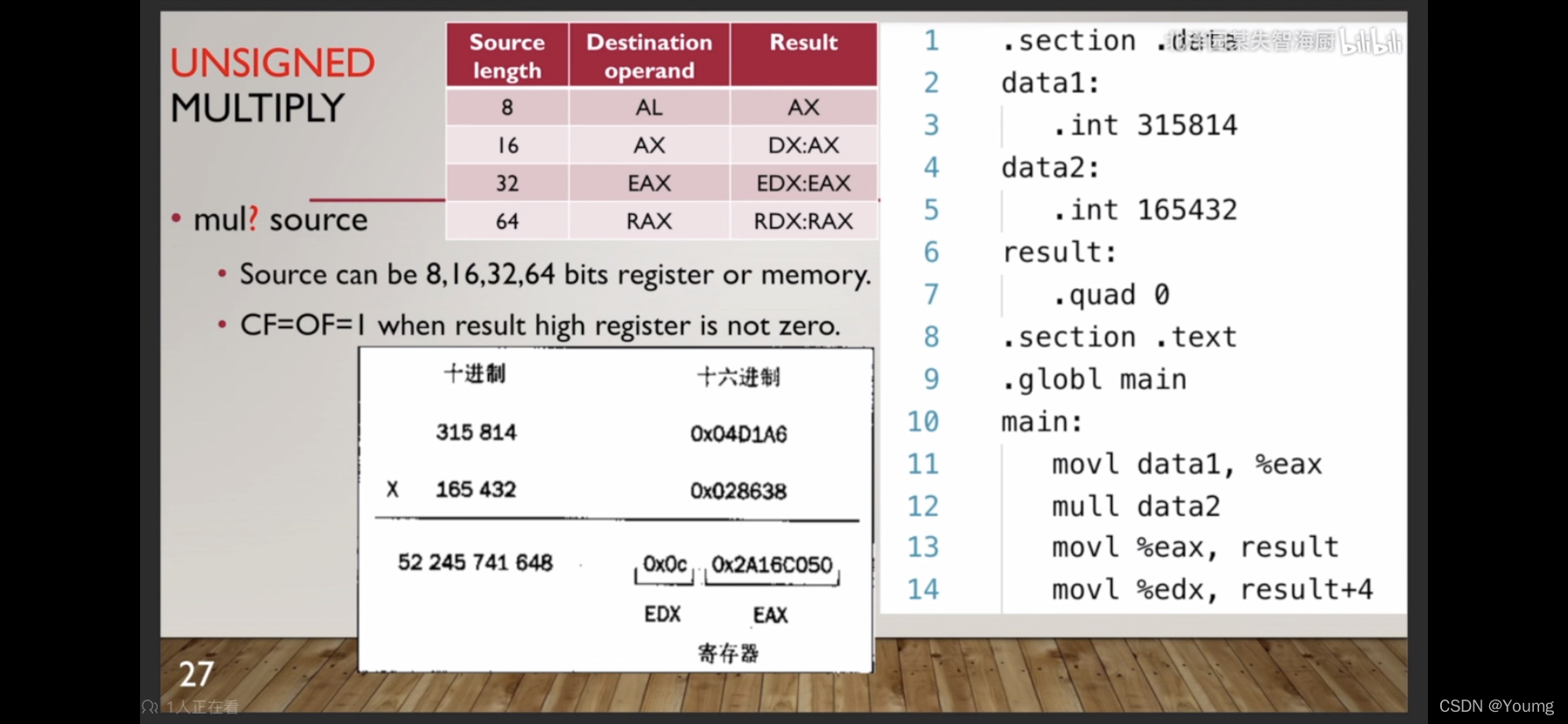
先设置好AL、AX、EAX或者RAX,然后才能用mul?指令。
source的位数,决定了使用哪个寄存器。
计算结果会覆盖AL、AX、EAX、RAX
result是内存,Linux的内存是Little-Endian。所以低地址放低4字节,高地址放高4字节。
因为result比乘数位数大一倍,这里CF、OF和加法的进位、溢出用法不太一样。
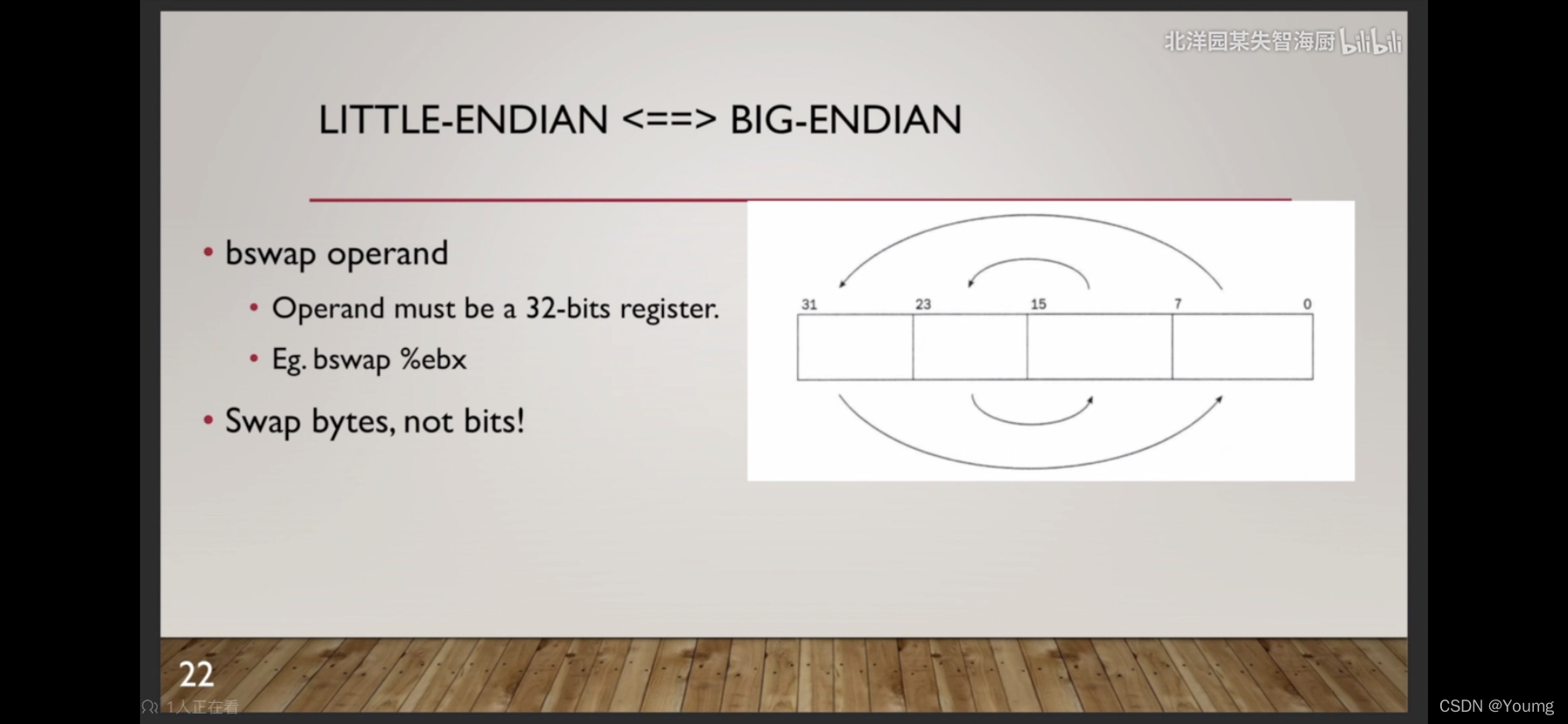
2.3.2 SIGNED MULTIPLY

imul? source与mul?用法相同
2.4 DIVIDE

三、位移
3.1 SHIFT LEFT

sal与shl完全相同。左移不存在算术与逻辑之分。
CF保存最高位,恰好与进位的含义对应。如果高位是1,则作为无符号数大于等于128,左移1位就是乘2,大于等于256,所以需要进位。
3.2 SHIFT RIGHT

算术右移,右移补充的是高位的bit位。
逻辑右移,右移补充的是0。
当前右移的bit位,放入CF中,表示除2之后的余数。
3.3 ROTATE SHIFT

问题:带CF位循环位移时,第一次位移时,CF当前内容需要设置、默认是0还是随机?
4. 逻辑运算

| 运算符 | 说明 |
|---|---|
| NOT | 1个操作数,按位取反 |
| AND | and? source, destination,两个操作数按位与 |
| OR | 两个操作数,按位或 |
| XOR | 两个操作数,按位异或 |
初始化为0操作:
xor %eax, %eax # 据说需要3个时钟周期,所以一般都用xor进行初始化为0操作
movl $0, %eax # 据说需要4个时钟周期
5. 总结

















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









