




 本文介绍了如何在Go语言中实现随机、轮询、加权轮询和一致性哈希等负载均衡算法,通过接口设计和工厂方法选择不同的算法,以避免单点故障问题。
本文介绍了如何在Go语言中实现随机、轮询、加权轮询和一致性哈希等负载均衡算法,通过接口设计和工厂方法选择不同的算法,以避免单点故障问题。
代码地址: https://gitee.com/lymgoforIT/golang-trick/tree/master/12-load-banlance
在实际工作中,为了避免单点故障,一个服务一般都是会部署多个实例的,那么请求来的时候,到底使用哪个服务器处理请求呢?这便涉及到了负载均衡算法了
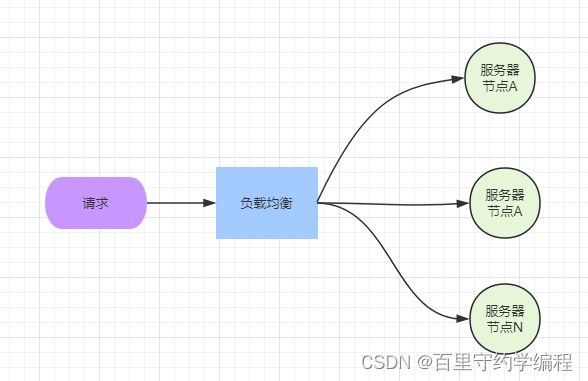
0. 接口设计
为了让用户能够选择使用哪种负载均衡算法,所以我们定义了一个接口,多个负载均衡算法都会实现这个接口,具体使用时便是策略模式了
package main
// 定义负载均衡的接口,拥有添加和获取服务器实例的方法(不考虑删除服务实例)
type LoadBalance interface {
// 往服务集群添加实例
Add(...string) error
// 获取一个实例接收本次请求
Get(string) (string, error)
}
1. 随机负载均衡
顾名思义,就是在所有可用的实例中,随机返回一个响应请求
package main
import (
"errors"
"math/rand"
)
type RandomBalance struct {
rss []string // 服务实例集合,每个元素为一个实例的地址
}
func (r *RandomBalance) Add(params ...string) error {
if len(params) == 0 {
return errors.New("params len 1 at least")
}
addr := params[0]
r.rss = append(r.rss, addr)
return nil
}
func (r *RandomBalance) Get(s string) (string, error) {
return r.Next(), nil
}
func (r *RandomBalance) Next() string {
if len(r.rss) == 0 {
return ""
}
return r.rss[rand.Intn(len(r.rss))]
}
2. 轮询负载均衡
服务器依次轮询
package main
import "errors"
type RoundRobinBalance struct {
// 由于是轮询,所以需要一个变量索引记录当前应该访问哪个实例了
curIndex int
rss []string
}
func (r *RoundRobinBalance) Add(params ...string) error {
if len(params) == 0 {
return errors.New("params len 1 at least")
}
addr := params[0]
r.rss = append(r.rss, addr)
return nil
}
func (r *RoundRobinBalance) Get(s string) (string, error) {
return r.Next(), nil
}
func (r *RoundRobinBalance) Next() string {
if len(r.rss) == 0 {
return ""
}
r.curIndex = (r.curIndex + 1) % len(r.rss) // 下一个请求需要访问的实例
return r.rss[r.curIndex] // 当前请求交给哪台实例处理
}
3. 加权轮询负载均衡
设置三个后端服务ServerA,ServerB和ServerC,它们的权重分布是 5,3,1
按照加权负载均衡算法,在一轮(5+3+1=9次)中ServerA占5次,ServerB占3次,ServerC占1次,从而实现均衡。
如下图所示:
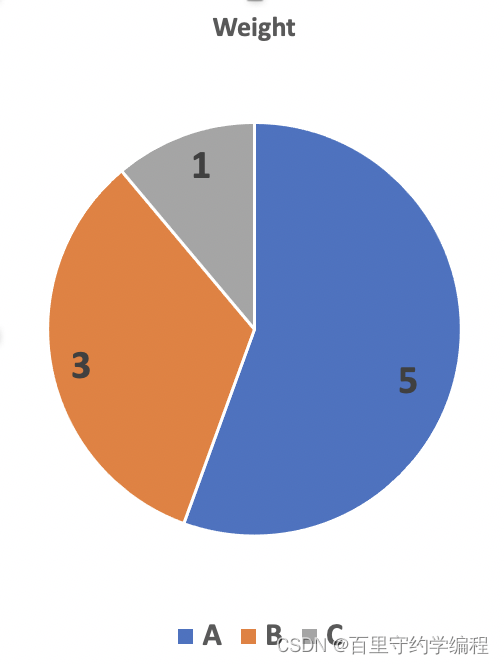
为了实现这个功能,可以给每一个后端设置对应的权重5,3,1
变量1:后端服务的权重 Weight
变量2:均衡器累计的总的有效权重TotalWeight
变量3:实时统计后端服务的当前权重 CurWeight
算法设计
第一步,向均衡器中增加后端服务标识
将三个后端服务标识和权重Weight增加到负载均衡器列表中。
每次增加后端服务时,累计总的有效权重TotalWeight。
第二步,每次获取一个后端服务标识
对均衡器中的所有后端服务增加自己的权重Weight,即(5,3,1),计算ABC三个服务的当前权重。
选择当前权重CurWeight最大的服务,做为本次期望的后端服务。
将期望的后端服务的当前权重CurWeight减小总的权重TotalWeight,供下一轮使用。
如下是一个一轮(5+3+1=9次)获取的权重变化表:
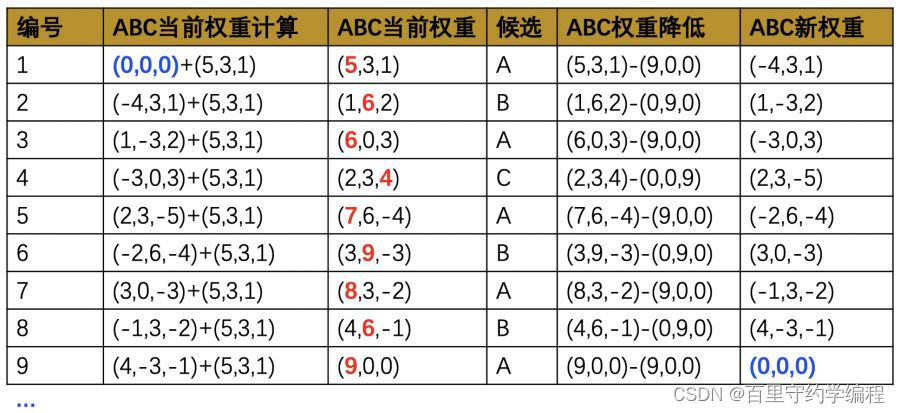
从这个表中可以看到后端服务轮询的顺序是 A B A C A B A B A,其中A出现了5次,B出现了3次,C出现了1次,满足三个服务的权重Weight设置。
完成9次获取后,ABC三个服务的权重都归0,因此下一轮的9次获取也是均衡的,
package main
import (
"errors"
"strconv"
)
type WeightNode struct {
addr string // 服务实例地址
curWeight int64 // 当前权重,每轮都会变化
Weight int64 // 初始化时设置的权重
}
type WeightRoundRobinBalance struct {
totalWeight int64 // 总权重
rss []*WeightNode // 所有的服务实例
}
func (w *WeightRoundRobinBalance) Add(s ...string) error {
if len(s) != 2 {
return errors.New("params len need 2")
}
weight, err := strconv.ParseInt(s[1], 10, 64)
if err != nil {
return err
}
w.totalWeight += weight
node := &WeightNode{
addr: s[0],
curWeight: 0,
Weight: weight,
}
w.rss = append(w.rss, node)
return nil
}
func (w *WeightRoundRobinBalance) Get(s string) (string, error) {
return w.Next(), nil
}
func (w *WeightRoundRobinBalance) Next() string {
var best *WeightNode
for _, node := range w.rss {
// 给每个服务实例加上自身权重,选出权重最大的
node.curWeight += node.Weight
if best == nil || node.curWeight > best.curWeight {
best = node
}
}
// 被选中的服务需要减去总权重用于下次计算
best.curWeight -= w.totalWeight
return best.addr
}
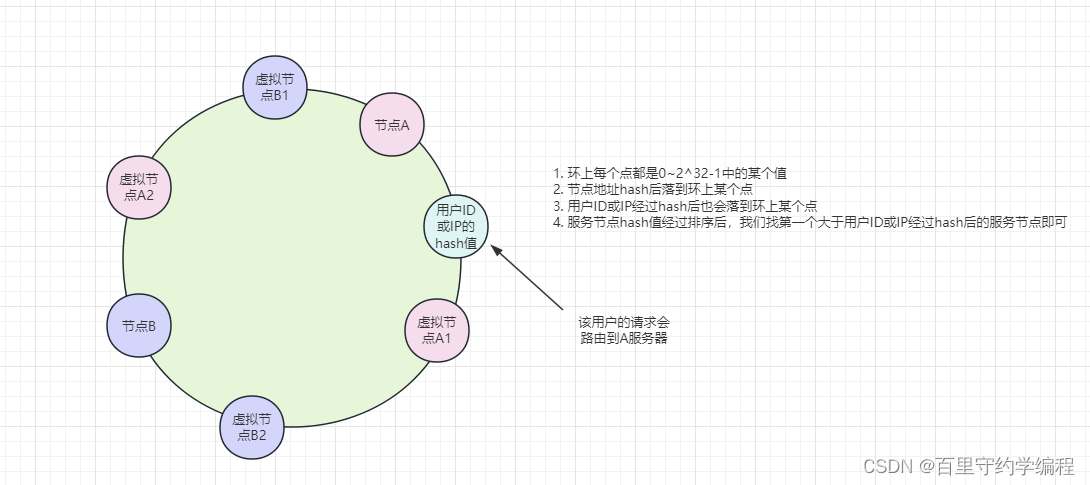
4. 一致性hash负载均衡
使用场景:固定的用户 | 固定的IP |请求固定的URL 时(根据使用何种字段hash决定),请求发到同一个服务器实例处理
一致性hash负载均衡算法简要流程如下图:
package main
import (
"errors"
"hash/crc32"
"sort"
"strconv"
"sync"
)
// 定义要使用的hash算法,参数为要hash的字段,返回值为uint32,即结果能落到一致性hash环上的某个点上
type Hash func(data []byte) uint32
// 定义一个类型,用于存所有的实例hash值排序后的结果,从而获得请求要路由到哪台实例上
// 注:实现Interface接口,从而可以用于排序
type UInt32Slice []uint32
func (s UInt32Slice) Len() int {
return len(s)
}
func (s UInt32Slice) Less(i, j int) bool {
return s[i] < s[j]
}
func (s UInt32Slice) Swap(i, j int) {
s[i], s[j] = s[j], s[i]
}
type ConsistentHashBalance struct {
mux sync.RWMutex
hash Hash
replicas int // 复制因子,即一个实例,会有replicas - 1 个虚拟实例
keys UInt32Slice // 所有实例hash排序后的结果
hashMap map[uint32]string //key : 实例的hash值,value:实例的地址
}
func NewConsistentHashBalance(replicas int, hash Hash) *ConsistentHashBalance {
if hash == nil {
// 用于生成hash值的函数,最多32位,保证是一个2^32-1环
hash = crc32.ChecksumIEEE
}
return &ConsistentHashBalance{
mux: sync.RWMutex{},
hash: hash,
replicas: replicas,
keys: make(UInt32Slice, 0),
hashMap: make(map[uint32]string),
}
}
func (c *ConsistentHashBalance) IsEmpty() bool {
return len(c.keys) == 0
}
// Add 方法用来添加缓存节点,参数为节点key,比如使用IP
func (c *ConsistentHashBalance) Add(params ...string) error {
if len(params) == 0 {
return errors.New("param len 1 at least")
}
addr := params[0]
c.mux.Lock()
defer c.mux.Unlock()
// 结合复制因子计算所有虚拟节点的hash值,并存入m.keys中,同时在m.hashMap中保存哈希值和key的映射
for i := 0; i < c.replicas; i++ {
hash := c.hash([]byte(strconv.Itoa(i) + addr)) // 虚拟节点为实例地址加一个序号,然后hash即可
c.keys = append(c.keys, hash)
c.hashMap[hash] = addr // 注:虚拟节点hash值对应的服务实例也都是addr
}
// 对所有虚拟节点的哈希值进行排序,方便之后进行二分查找
sort.Sort(c.keys)
return nil
}
// Get 方法根据给定的对象获取最靠近它的那个节点
func (c *ConsistentHashBalance) Get(key string) (string, error) {
if c.IsEmpty() {
return "", errors.New("node is empty")
}
hash := c.hash([]byte(key))
// 通过二分查找获取最优节点,第一个"服务器hash"值大于"数据hash"值的就是最优"服务器节点"
idx := sort.Search(len(c.keys), func(i int) bool { return c.keys[i] >= hash })
// 如果查找结果 大于 服务器节点哈希数组的最大索引,表示此时该对象哈希值位于最后一个节点之后,那么放入第一个节点中
if idx == len(c.keys) {
idx = 0
}
c.mux.RLock()
defer c.mux.RUnlock()
return c.hashMap[c.keys[idx]], nil
}
5. 工厂方法使用
package load_balance
type LbType int
const (
LbRandom LbType = iota
LbRoundRobin
LbWeightRoundRobin
LbConsistentHash
)
func LoadBalanceFactory(lbType LbType) LoadBalance {
switch lbType {
case LbRandom:
return &RandomBalance{}
case LbConsistentHash:
return NewConsistentHashBalance(3, nil)
case LbRoundRobin:
return &RoundRobinBalance{}
case LbWeightRoundRobin:
return &WeightRoundRobinBalance{}
default:
return &RandomBalance{}
}
}

















 1747
1747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









