




朋友们、伙计们,我们又见面了,本期来给大家带来负载均衡式在线OJ项目,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、
C + + 专 栏 :C++
Linux 专 栏 :Linux

目录
引言
本项目只是用于项目的学习思路以及编写思路,提升对大型代码的组织能力,只是将其核心部分拿出来了解,并不是为了完整的实现出在线OJ的全部功能,但是最基本的功能是要有的,我们只来实现一个基础的基于负载均衡式的在线OJ。
项目介绍
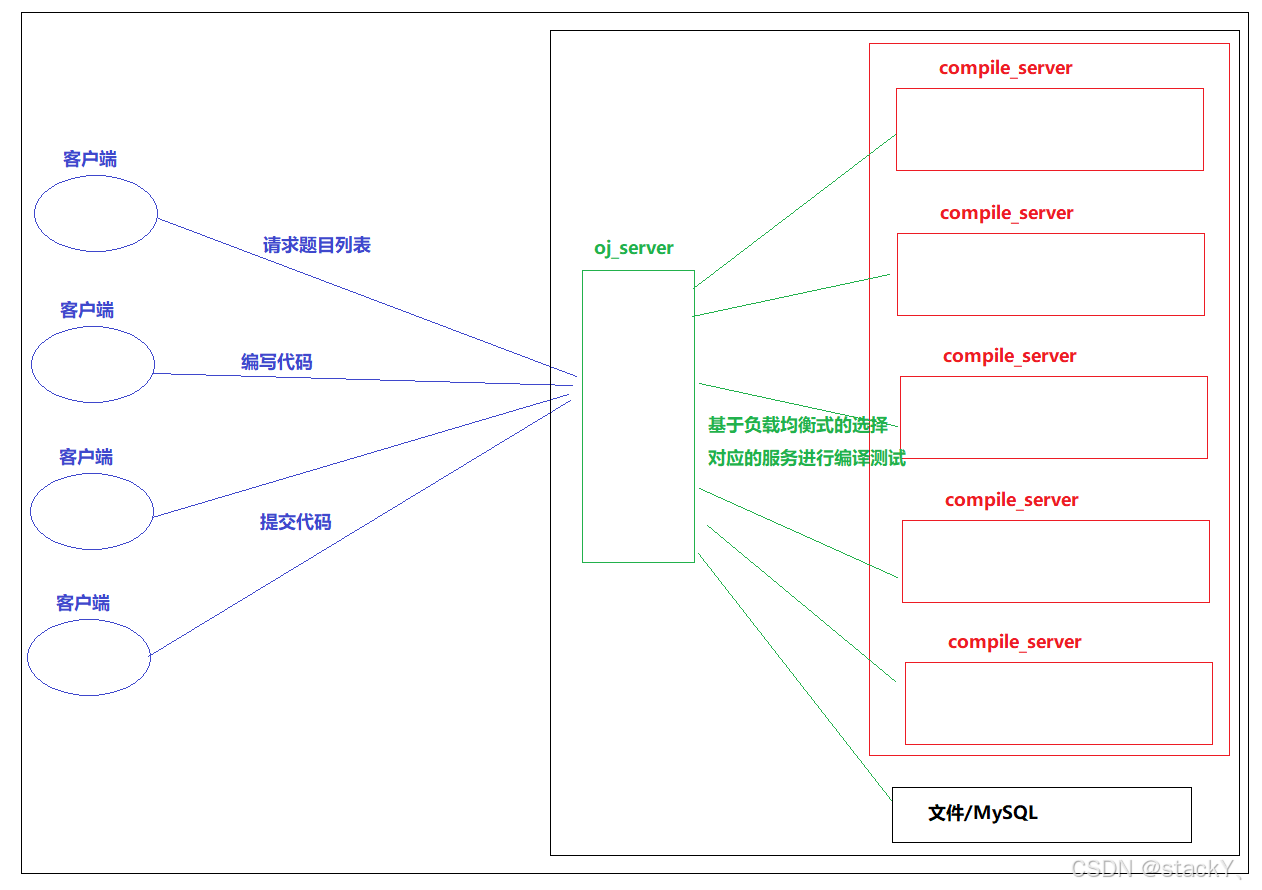
该项目是基于负载均衡的在线OJ,模拟我们平时刷题网站(leetcode和牛客)写的一个在线判题系统。
项目主要分为三个模块:
- ① comm模块:主要是实现一些公共方法(日志,工具类);
- ② compile_server模块:对于提交上来代码进行编译与运行;
- ③ oj_server模块:获取题目列表,查看题目编写界面,实现负载均衡,其他功能。
注意:我们只实现类似 leetcode 的题⽬列表+在线编程功能
开发环境
Ubuntu 22.04 64bit云服务器、C/C++、vscode、MySQL Workbench
整体框架
负载均衡式在线OJ宏观结构:
编写思路
- 先实现compile_server模块;
- 再实现oj_server模块;
- 实现version1版本的基于文件的在线OJ
- 进行一些前端页面的设计(了解)
- 实现version2版本的基于MySQL的在线OJ
- 对于comm模块在整个代码的编写环节中哪里用到就直接写进去了,不做单独环节的编写
1. compile服务
该模块是用来进行编译运行的,所以我们先根据当前所需创建一些需要的文件,后面再根据需要进行调整:
- compiler.hpp:用于对提交的代码进行编译;
- runner.hpp:对编译好的代码进行运行;
- compile_run.hpp:为了方便,将编译和运行结合在一起;
- compile_server:使用网络相关的接口进行服务请求。
- Makefile:自动化构建代码
1.1 compiler.hpp
在这里我们用于实现代码的编译效果:
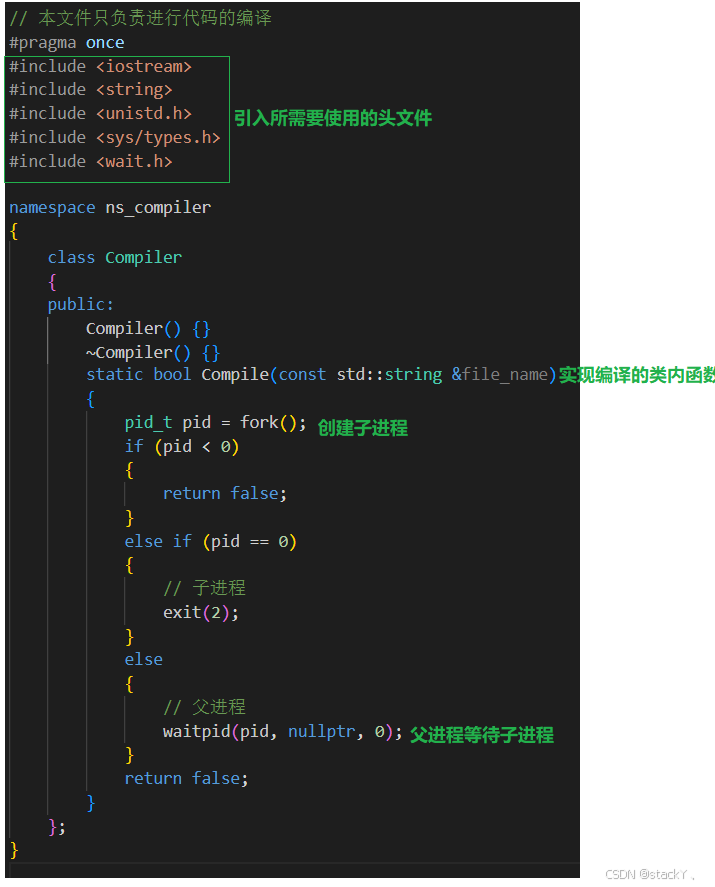
编译操作我们用类进行封装,将这些类封装在命名空间中;
首先我们需要知道的是,我们的主进程在运行的时候是不能进行编译操作的,主进程有自己的代码逻辑,所以首先得创建子进程,让子进程去完成编译的操作,创建子进程和父进程等待子进程的操作我们先来实现:
拼接文件后缀:
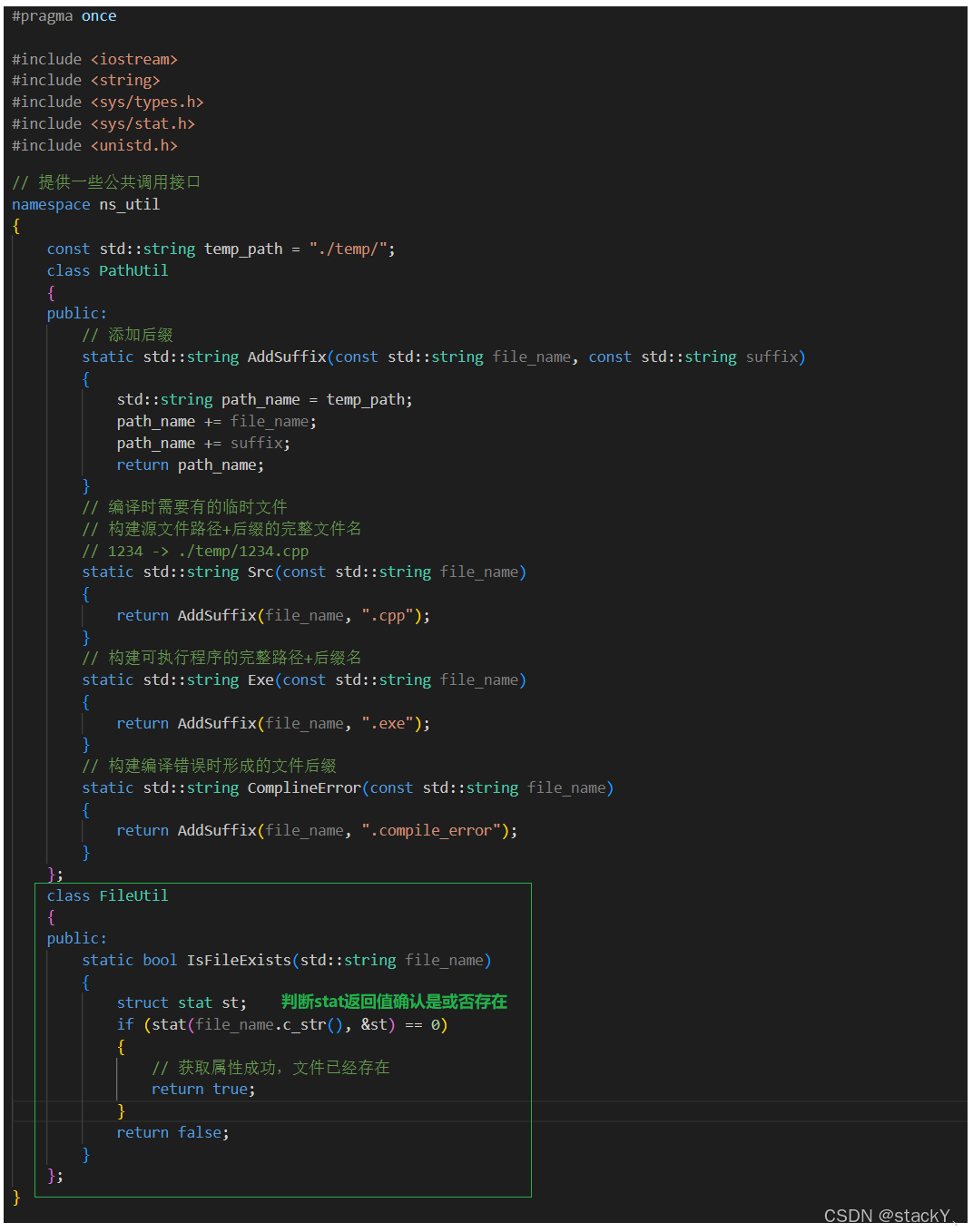
基本的框架实现完成之后,我们来仔细想一下子进程要对源文件进行编译时,需要传递文件名,这也没问题,但是g++在编译时需要根据文件后缀来进行识别,我们传递的文件名需要再添加上后缀,同时,我们编译好的文件也需要添加后缀,再者,当g++编译出错时的这个错误信息我们也需要保存在一个临时文件中,所以这就需要完成一个给文件拼接后缀的接口,这个接口我们可以直接实现在comm模块的工具中,首先在comm模块中创建util.hpp(本文件中用于实现一些公共使用的工具)
同样的,对于拼接文件后缀的接口我们也是写进命名空间封装在类中,同时我们需要有一个文件来保存这些临时文件的路径,所以我们在compile模块中添加一个temp文件
接下来我们就来实现文件后缀拼接的工作:
在拼接文件后缀时,首先得所要拼接的文件名和拼接的后缀,所以需要传入这两个参数,然后通过string的+=操作来进行拼接,我们需要完成三种文件后缀的拼接工作,第一种是源文件的拼接后缀.cpp,第二种拼接可执行文件的后缀.exe,第三种编译出错时出错信息文件的后缀.stderr;
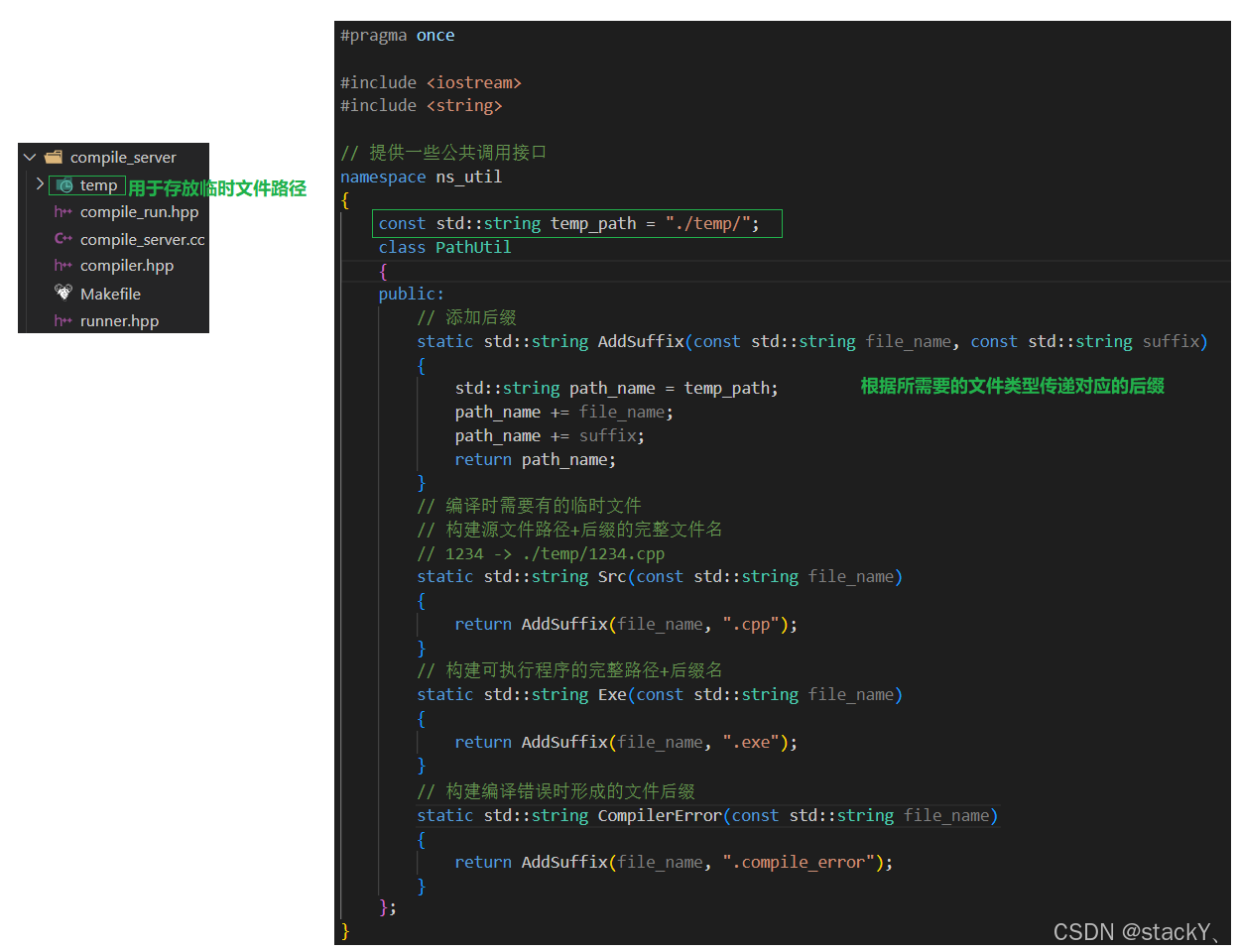
注意:该方法是实现在util.hpp中的
标准错误重定向:
文件后缀拼接好之后,接下来就可以让子进程实现编译功能了,子进程要进行程序编译,就需要使用到程序替换的系统调用接口,那么在程序替换之前呢,我们还需要做一件事情,我们都知道g++在编译出错时会默认将错误信息打印到标准错误中,也就是我们的显示器,但是我们既然创建了保存错误信息的临时文件,那么就需要将错误信息从标准错误中重定向到临时文件中,接下来我们先来实现这个功能:
我们可以先通过open接口将临时文件打开,记录临时文件的文件描述符,然后通过dup2接口对错误信息进行重定向;

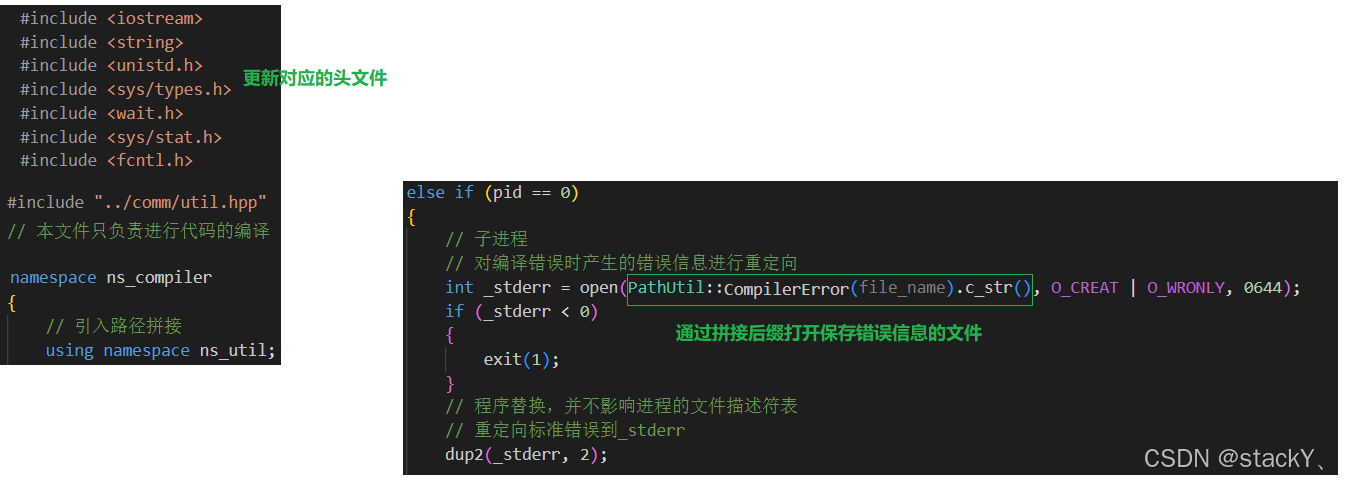
标准错误的文件描述符是2,可以将其重定向。
程序替换执行g++:
接下来就让子进程进行程序替换操作,我们使用execlp接口:
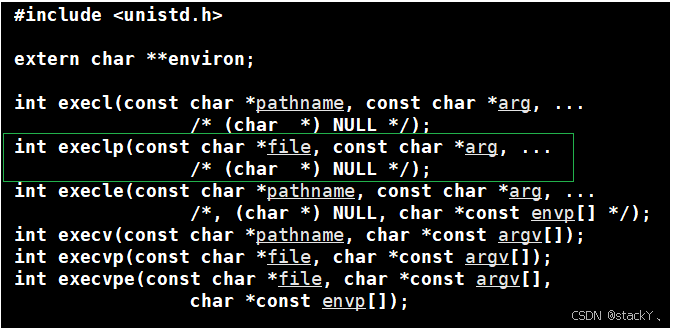
此时就可以根据所需进行对应文件后缀的拼接,从而完成程序替换操作;
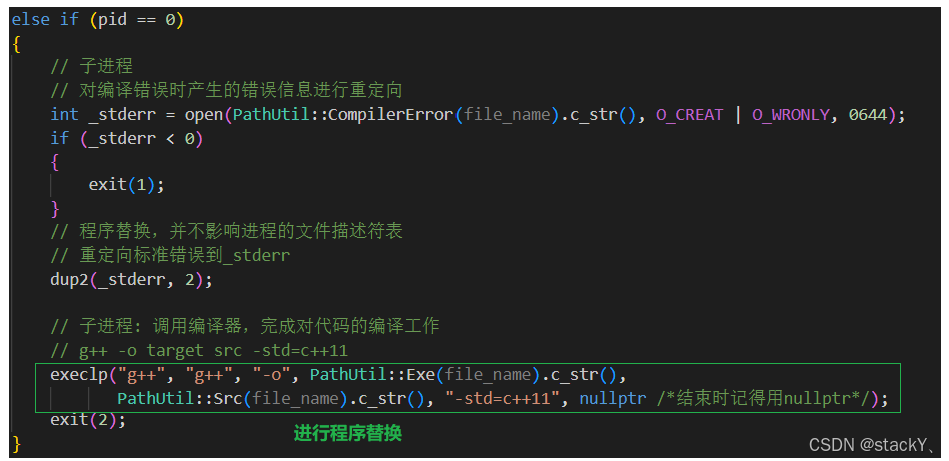
注意:程序替换时,并不会影响进程文件描述符表,不要担心重定向的问题。
检测编译是否成功:
子进程完成了程序替换、编译的工作,那么接下来编译是否成功呢?就需要让父进程来进行了,对于检测编译是否成功直接检测是否生成了对应的可执行文件就可以了,所以我们需要用到一个检测文件是否存在的接口,同样的我们还是写在comm模块中的util.hpp中:
创建一个FileUtil类,实现一个IsFileExists的方法,只需要传递文件名,通过拼接后缀来判断文件是否存在,那么判断一个文件是否存在需要用到的接口是stat接口,该接口是用来获取文件的属性的,换而言之如果文件存在那么可以获取成功,所以我们只需要关系stat是否获取成功即可判断文件是否存在:

comm/util.hpp
接下来就需要在父进程中调用该接口即可,因为前面我们已经将util.hpp引入了,所以直接使用即可:
compiler.hpp
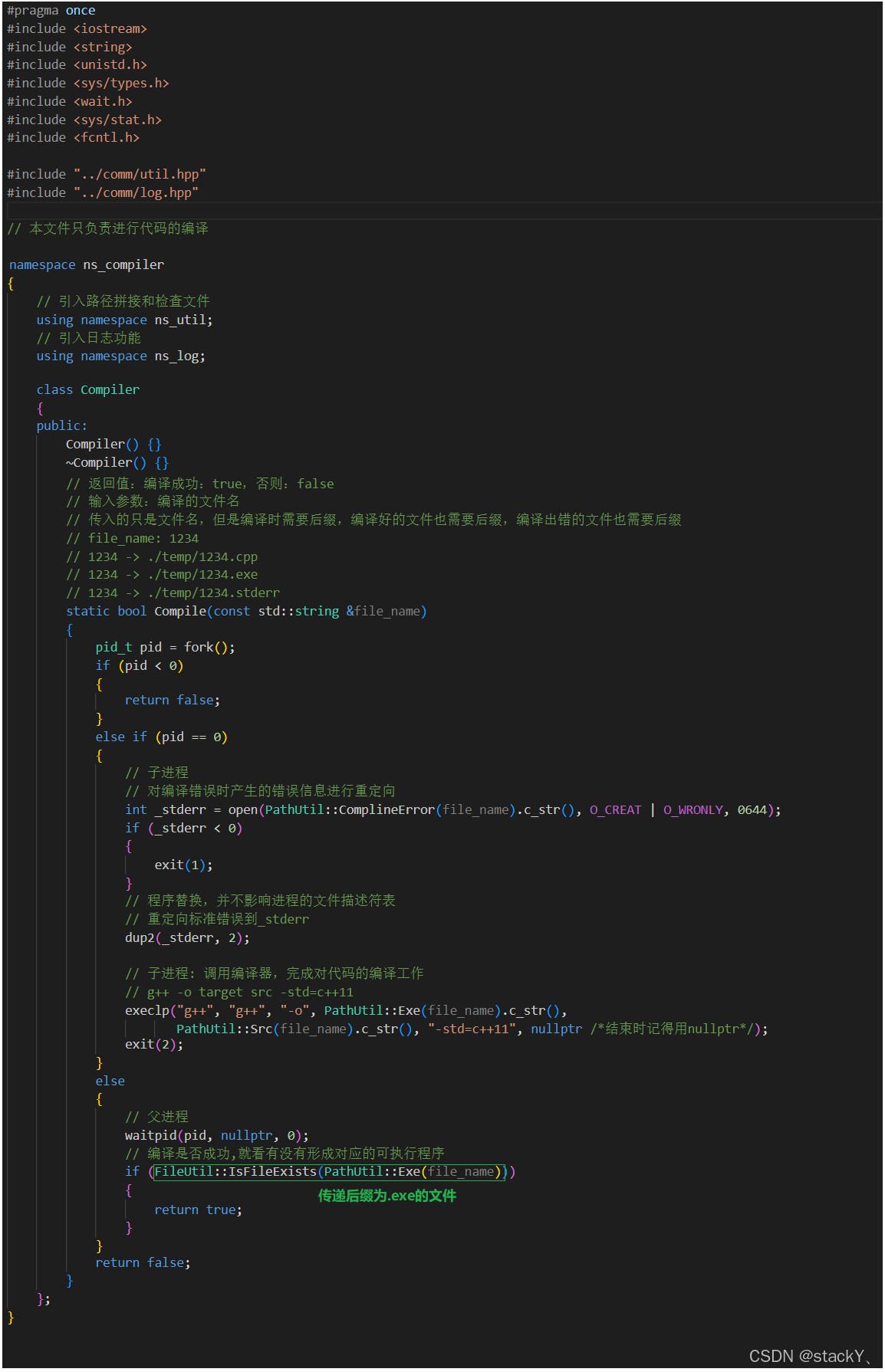
写到这里,compiler.hpp的基本功能就实现的差不多了,后面有需要我们再进行补充。
1.2 日志功能
可以看到我们上面的程序中的代码只是实现的逻辑,但是各种细节都没有处理,比如子进程创建失败、打开文件失败、编译的成功与失败等等这些逻辑直接返回了,没有一些提示的信息,所以我们实现一个日志功能来将这些错误信息、成功信息显示出来。
我们期望实现的日志是这样子使用的:
LOG(日志等级) << "message" << "\n";所以在在实现的日志里面需要包含对应的日志等级,并且我们需要有文件名,该文件中的哪一行,时间戳等信息,并且我们实现的日志使用起来要类似与cout;
我们将日志写进comm模块,新创建一个log.hpp文件,里面使用命名空间限定,实现一个Log日志接口;
首先要枚举日志的等级(正常、测试、告警、错误、系统崩溃),当我们打日志时为了更清楚,我们要有哪种等级,哪个文件,文件中的哪一行,并且还要有时间戳,前三个当我们调用Log时直接传入并且拼接即可,时间戳我们用系统调用接口获取一下然后拼接在后面。
要注意,我们实现的Log是一种类似于cout标准输出用法的,返回值设置为ostream;
还需要注意的一点就是,cout本质内部是有缓冲区的,在返回前要将拼接好的字符串写入cout的缓冲区;
这样子写已经可以了,但是可以发现每次调用时都要传入三个参数,是比较麻烦的,所以我们可以使用宏替换,用__FILE__来获取当前源文件名称,用__LINE__来获取当前程序所在行数,这样子就不用在调用的时候传递这两个参数了,但是我们设置的日志等级是枚举的,其实就是一个整数,但是我们原函数的level是一个string类型的,所以在宏替换的时候给level前面加上#当做string来用即可。
#pragma once #include <iostream> #include <string> #include "util.hpp" namespace ns_log { // 引入获取时间戳 using namespace ns_util; // 日志等级 enum { INFO, // 正常 DEBUG, // 测试 WARNING, // 警告但不影响运行 ERROR, // 当前机器发生错误 FATAL // 整个系统崩溃 }; // LOG(level) << "message" << "\n"; inline std::ostream &Log(const std::string &level, const std::string &file_name, int line) { // 添加日志等级 std::string message = "["; message += level; message += "]"; // 添加报错文件名称 message += "["; message += file_name; message += "]"; // 添加报错行 message += "["; message += std::to_string(line); message += "]"; // 获取时间戳 message += "["; message += TimeUtil::GetTimeStamp(); message += "]"; // cout 内部也是有缓冲区的,现将拼接好的message写入cout std::cout << message; // 切记!!!不要使用endl进行刷新 return std::cout; } // 未来在调用日志时,一直传递三个参数太麻烦 // 所以进行宏替换,实现开放式的日志 // 日志等级本质上是整数,在前面添加#可以转为字符串形式 // __FILE__ 和 __LINE__ 可以直接获取当前源文件名以及当前程序的行号 #define LOG(level) Log(#level, __FILE__, __LINE__) // 不要加; 切记!!! }
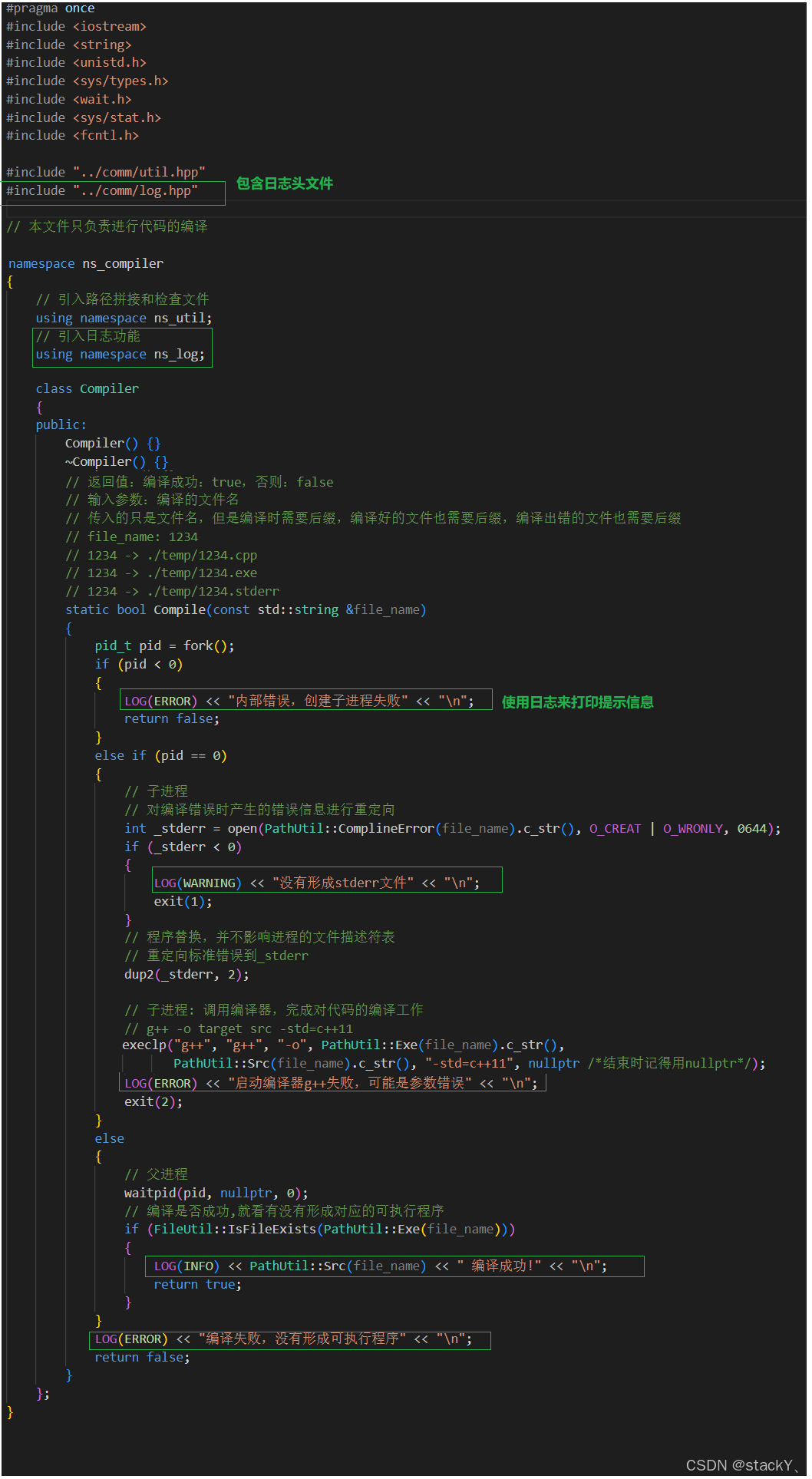
1.2.1 完善compiler.hpp
现在有了日志,我们就可以使用日志来对我们的程序做一些完善了:
1.3 runner.hpp
在compiler.hpp中我们实现了代码的编译功能,那么编译好的代码就完了吗?不是,我们还需要将编译好的程序运行起来,查看结果,所以在runner.hpp中我们实现程序的运行操作;
在编写之前我们需要知道,程序编译和程序运行都是不能在主进程上执行,都是需要创建子进程,让子进程通过程序替换来完成编译和运行的工作的,基本的逻辑和程序编译时一样,另外,我们要知道,程序执行的结果有三种:
- ① 代码跑完,结果正确
- ② 代码跑完,结果不正确
- ③ 代码没跑完,异常了
那么,在runner.hpp中我们需要对这三种情况全部处理吗?答案是不需要的,因为runner.hpp只进行程序的运行情况,我们只需要关注程序能否正常运行即可,不需要考虑运行的结果。
我们顺便也把日志引入进去,我们先来实现一个主框架:
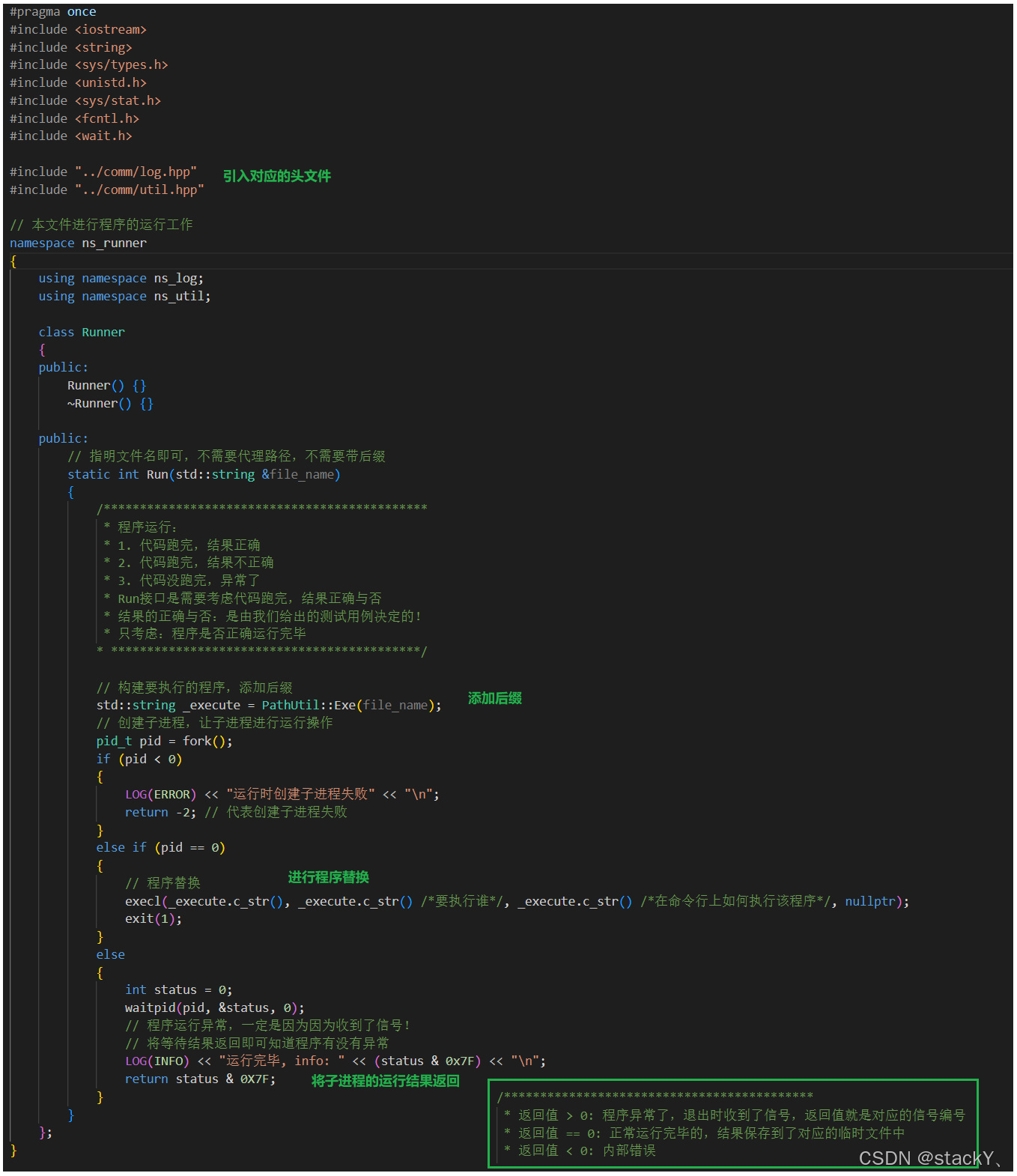
实现出主的框架之后我们再来增添一些细节的东西:
一个程序在运行时会默认打开三个流:
① 标准输入 ② 标准输出 ③ 标准错误
那么我们想和编译模块里面对于编译文件存放的方式一样,将输入,输出,错误这三个文件信息也放进temp临时文件中,所以我们就需要三个单独的临时文件,然后通过重定向功能将这些信息写进这些文件中,所以我们先增添三个添加文件后缀的接口(在comm模块中的util.hpp中实现)。
util.hpp:
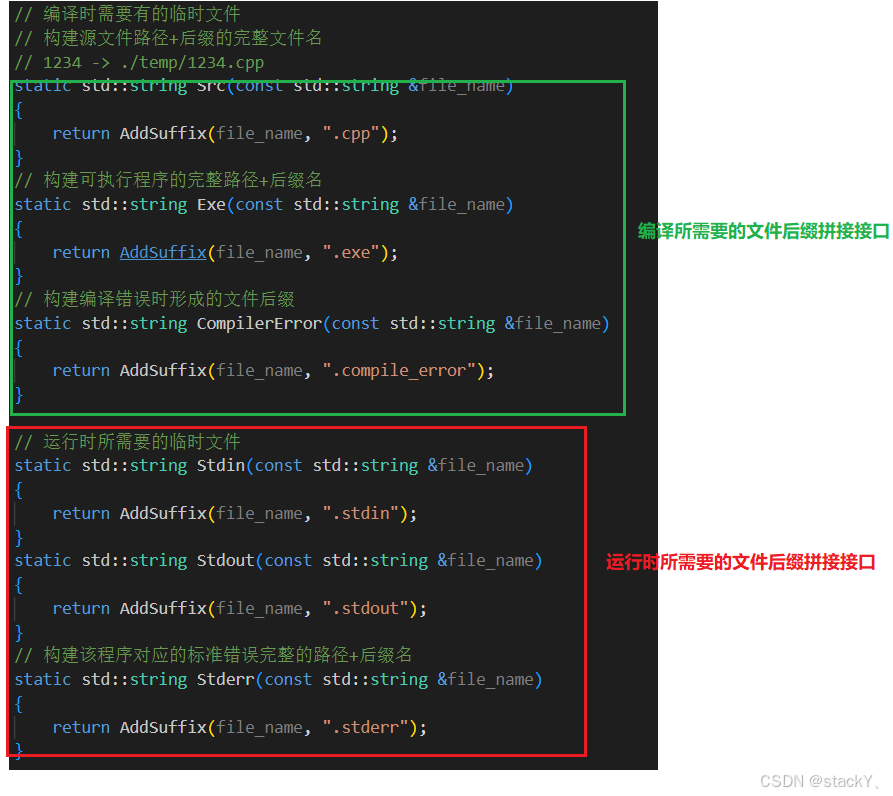
我们的文件后缀拼接的接口实现好了,那么要实现重定向,先需要将这些文件名先构造出来,然后用open打开,分配文件描述符,通过dup2进行重定向功能(我们对于输入功能进行重定向时,向文件读取的意义就是不想让用户进行自测功能):
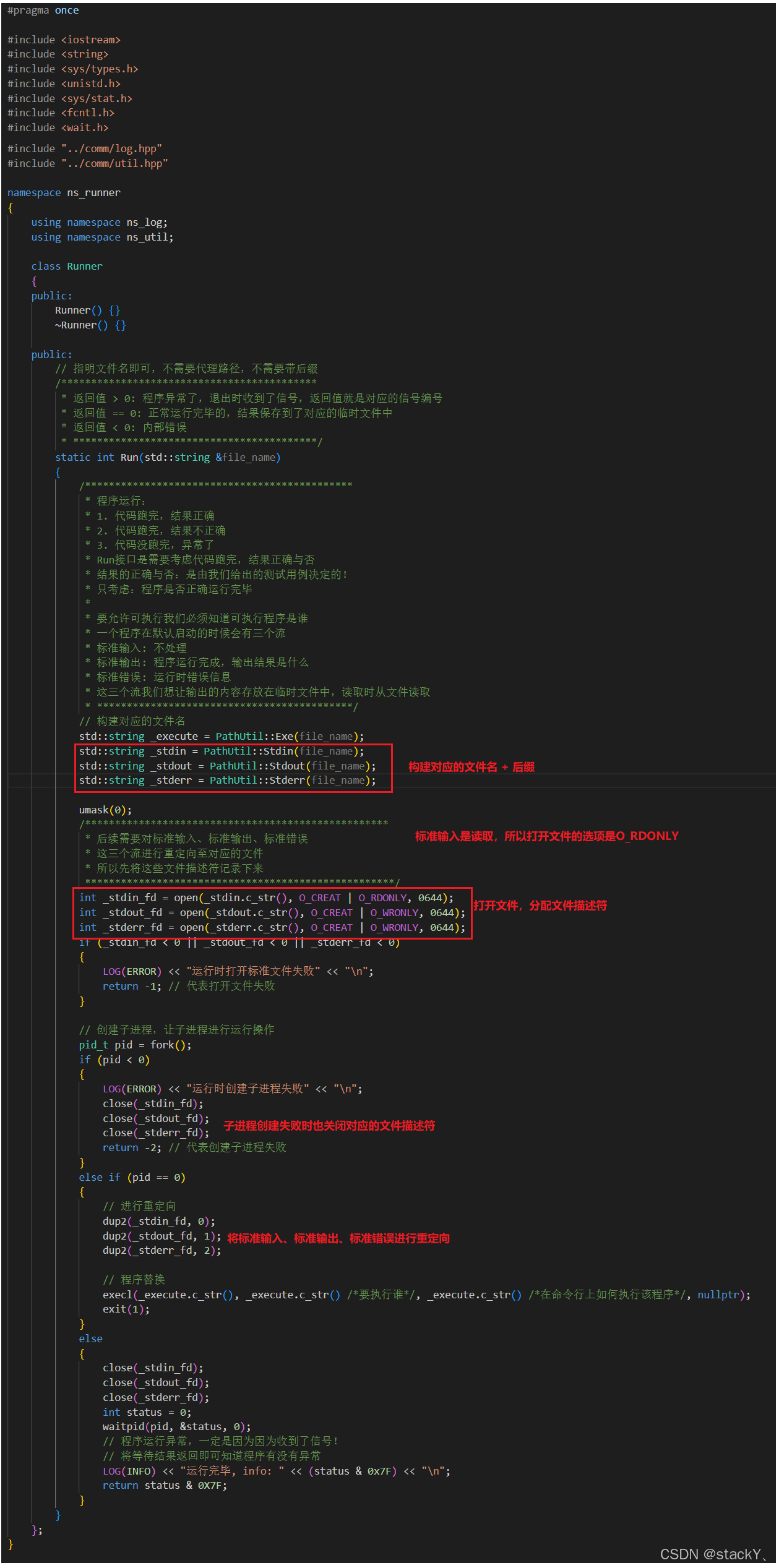
写到这里对于程序运行就快要结束了,但是我们需要想一下,提交代码的用户很多,避免不了一些恶意用户提交一些恶意代码,一直占用我们的计算机资源,所以,最后一步还需要进行资源的限制,我们需要用到的接口是setrlimit:
那么,这个限制是由做测试用例的人进行限制的,我们的Run并不知道,所以在调用Run时我们需要将内存限制和CPU限制传递进来,关于这个对资源进行限制的操作我们肯定是要在程序替换之前就要完成的:
runner.hpp:
#pragma once #include <iostream> #include <string> #include <sys/types.h> #include <unistd.h> #include <sys/stat.h> #include <fcntl.h> #include <wait.h> #include <time.h> #include <sys/resource.h> #include "../comm/log.hpp" #include "../comm/util.hpp" namespace ns_runner { using namespace ns_log; using namespace ns_util; class Runner { public: Runner() {} ~Runner() {} public: //提供设置进程占用资源大小的接口 static void SetProcLimit(int _cpu_limit, int _mem_limit) { // 设置CPU时长 struct rlimit cpu_limit; cpu_limit.rlim_max = RLIM_INFINITY; cpu_limit.rlim_cur = _cpu_limit; setrlimit(RLIMIT_CPU, &cpu_limit); // 设置内存大小 struct rlimit mem_limit; mem_limit.rlim_max = RLIM_INFINITY; mem_limit.rlim_cur = _mem_limit * 1024; // 转化为KB setrlimit(RLIMIT_AS, &mem_limit); } // 指明文件名即可,不需要代理路径,不需要带后缀 /******************************************* * 返回值 > 0: 程序异常了,退出时收到了信号,返回值就是对应的信号编号 * 返回值 == 0: 正常运行完毕的,结果保存到了对应的临时文件中 * 返回值 < 0: 内部错误 * * cpu_limit: 程序运行的时候,可以使用的最大cpu资源上限 * mem_limit: 程序运行的时候,可以使用的最大的内存大小(KB) * * *****************************************/ static int Run(std::string &file_name, int cpu_limit, int mem_limit) { /********************************************* * 程序运行: * 1. 代码跑完,结果正确 * 2. 代码跑完,结果不正确 * 3. 代码没跑完,异常了 * Run接口是需要考虑代码跑完,结果正确与否 * 结果的正确与否:是由我们给出的测试用例决定的! * 只考虑:程序是否正确运行完毕 * * 要允许可执行我们必须知道可执行程序是谁 * 一个程序在默认启动的时候会有三个流 * 标准输入: 不处理 * 标准输出: 程序运行完成,输出结果是什么 * 标准错误: 运行时错误信息 * 这三个流我们想让输出的内容存放在临时文件中,读取时从文件读取 * *******************************************/ std::string _execute = PathUtil::Exe(file_name); std::string _stdin = PathUtil::Stdin(file_name); std::string _stdout = PathUtil::Stdout(file_name); std::string _stderr = PathUtil::Stderr(file_name); umask(0); /*************************************************** * 后续需要对标准输入、标准输出、标准错误 * 这三个流进行重定向至对应的文件 * 所以先将这些文件描述符记录下来 ****************************************************/ int _stdin_fd = open(_stdin.c_str(), O_CREAT | O_RDONLY, 0644); int _stdout_fd = open(_stdout.c_str(), O_CREAT | O_WRONLY, 0644); int _stderr_fd = open(_stderr.c_str(), O_CREAT | O_WRONLY, 0644); if (_stdin_fd < 0 || _stdout_fd < 0 || _stderr_fd < 0) { LOG(ERROR) << "运行时打开标准文件失败" << "\n"; return -1; // 代表打开文件失败 } // 创建子进程,让子进程进行运行操作 pid_t pid = fork(); if (pid < 0) { LOG(ERROR) << "运行时创建子进程失败" << "\n"; close(_stdin_fd); close(_stdout_fd); close(_stderr_fd); return -2; // 代表创建子进程失败 } else if (pid == 0) { // 进行重定向 dup2(_stdin_fd, 0); dup2(_stdout_fd, 1); dup2(_stderr_fd, 2); // 防止恶意用户上传占用资源的代码,在执行程序前先进行资源限制 SetProcLimit(cpu_limit, mem_limit); // 程序替换 execl(_execute.c_str(), _execute.c_str() /*要执行谁*/, _execute.c_str() /*在命令行上如何执行该程序*/, nullptr); exit(1); } else { close(_stdin_fd); close(_stdout_fd); close(_stderr_fd); int status = 0; waitpid(pid, &status, 0); // 程序运行异常,一定是因为因为收到了信号! // 将等待结果返回即可知道程序有没有异常 LOG(INFO) << "运行完毕, info: " << (status & 0x7F) << "\n"; return status & 0X7F; } } }; }
1.4 compile_run.hpp
通过compiler.hpp实现了编译功能,并通过runner.hpp实现了运行功能,那么在compile_run.hpp中我们来将这两个功能进行合并,实现一个编译 + 运行的功能;
首先我们需要知道,我们将来上传的代码是通过网络服务传递的,那么我们就需要统一进行约定,我们想通过json串的方式来进行输入,通过json串的方式将编译运行结果返回;
// 安装json Ubuntu 22.04 sudo apt-get install libjsoncpp-dev // 查看是否安装成功 ls /usr/include/jsoncpp/json/关于json的使用大家可以搜一些博客,也可以移步至C++ 之 C++ 操作 json 文件(C++读写json文件)
了解了json之后,我们来对编译运行接口进行设计,我们需要一个接口,包含有输入型参数和一个输出型参数,首先我们需要对输入的参数进行一个反序列化的操作对输入的数据进行解析;
我们规定输入的json串包含的kv结构有四种:
- ① code:传入的代码
- ② input:对提交的代码进行输入的数据(不做处理)
- ③ cpu_limit:时间要求
- ④ mem_limit:空间要求
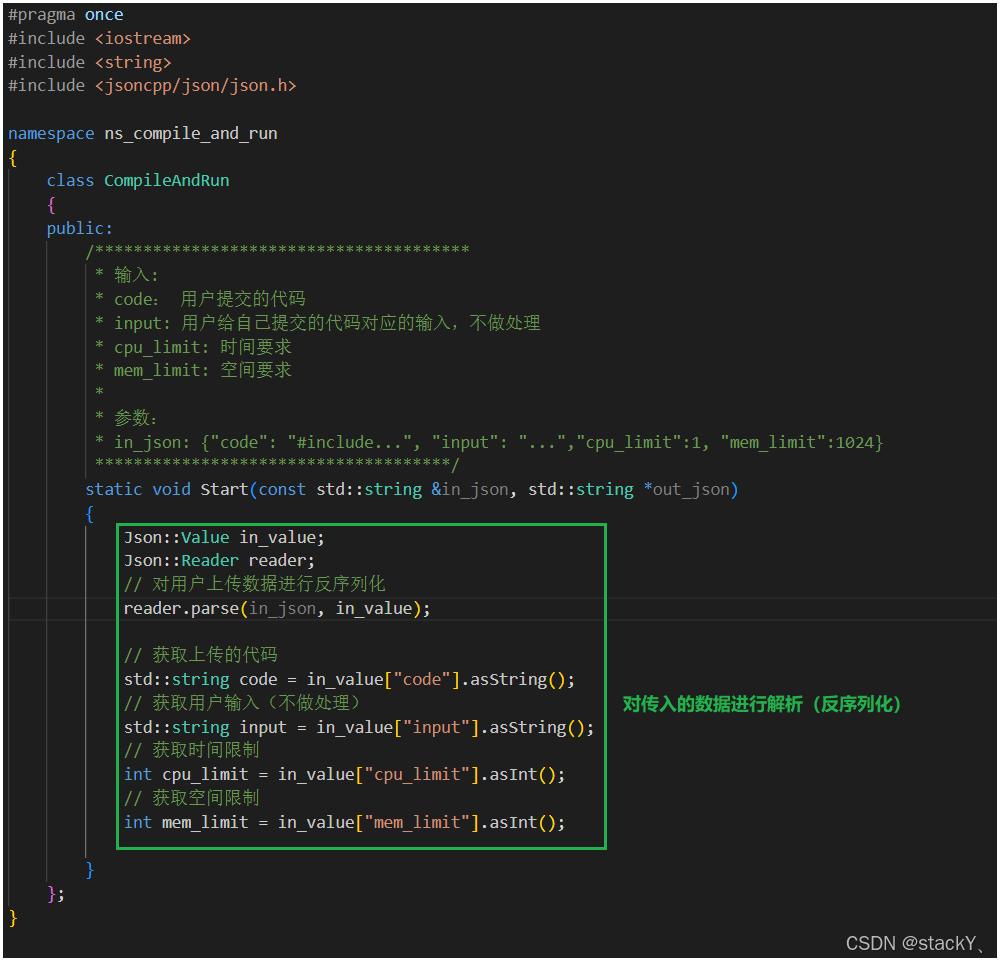
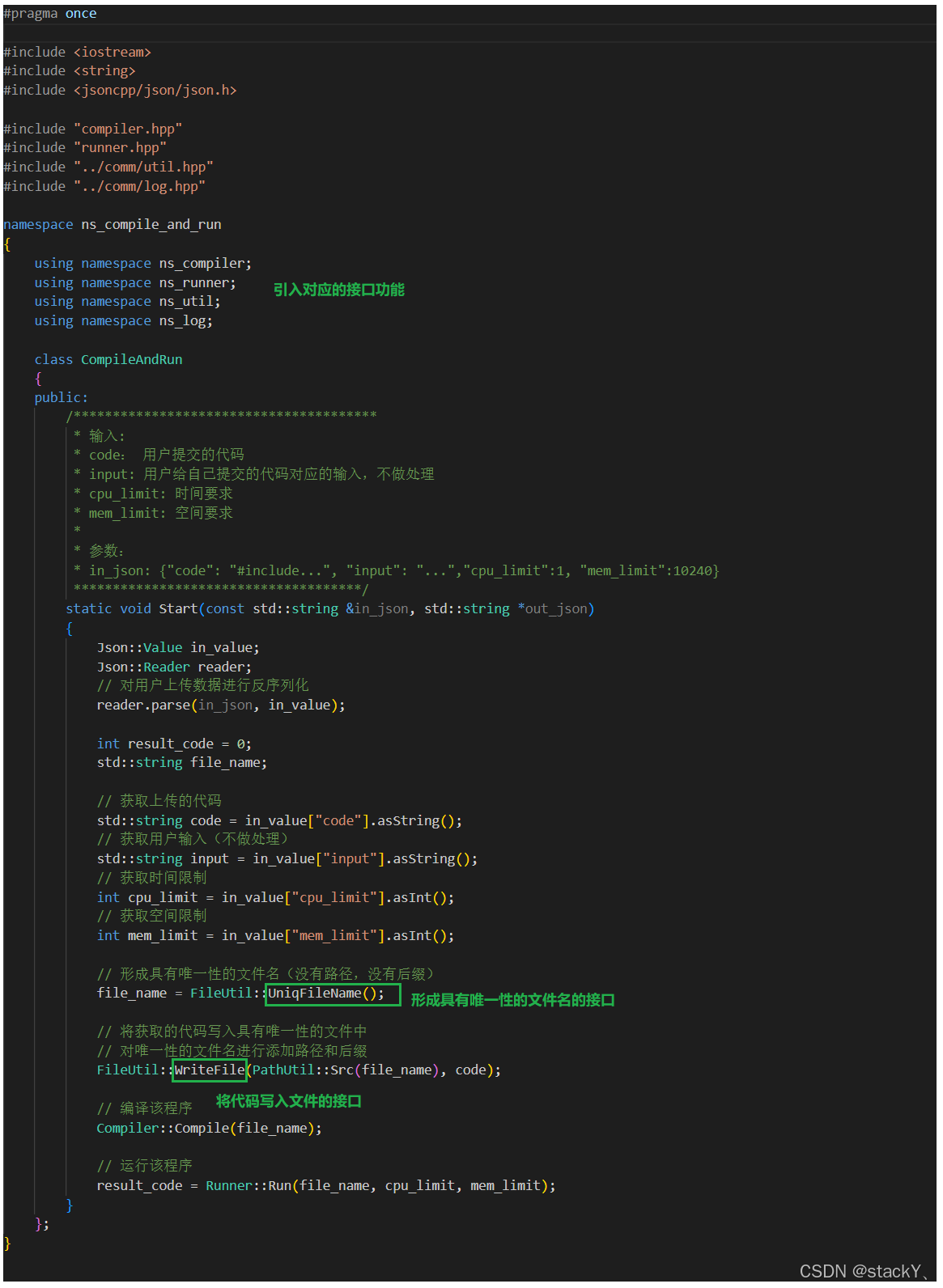
对传入的数据进行反序列化之后,我们就得到了对应的四个参数,一个是传入的代码,一个是传入的输入数据(不处理),一个是时间限制,一个是空间限制,那么当我们获取到了传入的代码,下一步就需要对代码进行编译,所以需要形成一个具有唯一性的文件名,然后我们添加上后缀,将代码写入这个文件中,然后调用compile进行编译,编译完成之后执行该程序,所以在这一步我们需要做的工作:
- ① 形成具有唯一性的文件名
- ② 给该文件名添加后缀
- ③ 将代码写入该源文件中(对唯一文件名添加源文件后缀)
- ④ 调用编译接口进行编译
- ⑤ 编译完成之后调用运行接口执行该程序
我们需要新增的函数接口有:
- ① 形成具有唯一性的文件名
- ② 将代码写入文件
所以我们将这两个接口继续实现在comm模块里面的util.hpp中,具体的实现思路我们后面再说,先把主框架构建出来:
1.4.1 差错处理
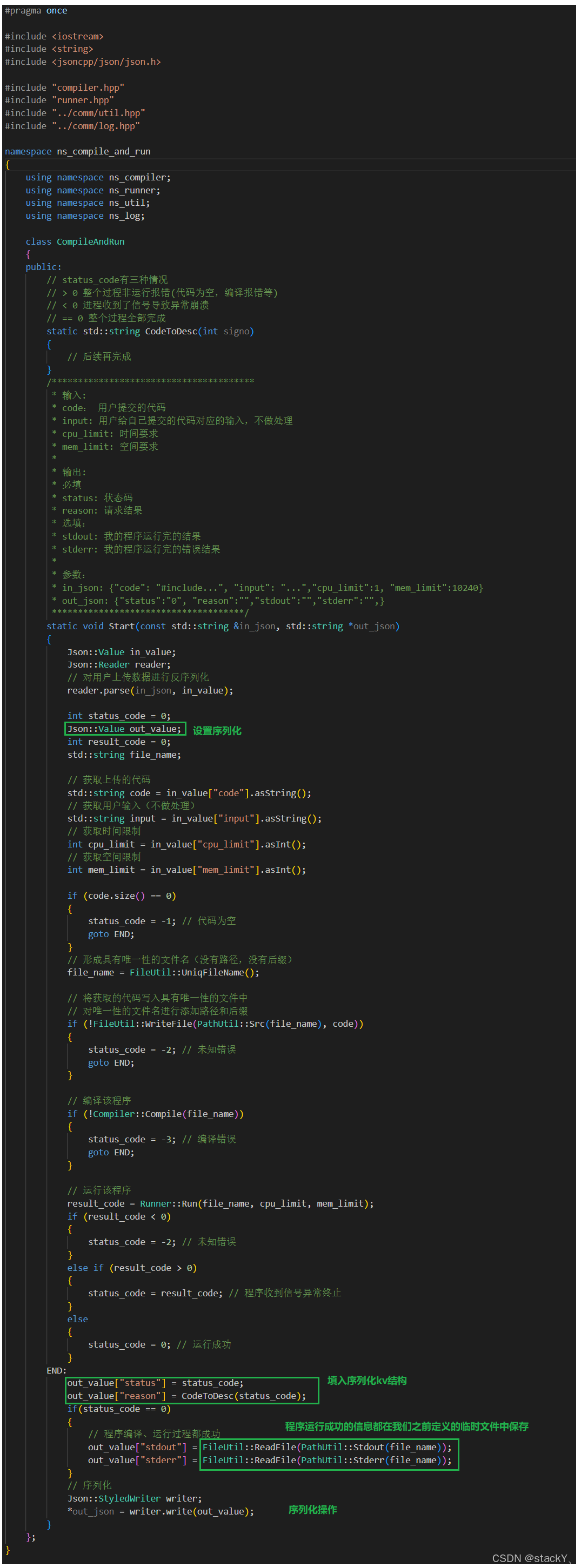
当主体框架写出来之后,需要进行一些差错处理,比如:传递的是空代码,写入文件失败、编译失败、运行失败等等这些错误信息我们该如何处理呢?另外,这些错误信息上层也是需要看到的,那么我们怎么将错误信息序列化返回给上层呢?
我们当然可以在每一个可能会出错的位置都写一套对应的处理逻辑,然后序列化通过输出型参数返回给上层,差不多要写6套逻辑,这样子实现让我们的代码看起来太臃肿了,那么我们要实现的简便一点还不能失去实用性,所以我们可以这样子实现:
- 我们可以设置一个status_code状态码,在出现错误的地方需要对状态码进行修改;
- 比如传递空代码状态码设为-1,出现一些系统错误时设置为-2,编译错误设为-3,由信号终止的就设置为该信号值,如果运行没有问题就设置为0;
- 如果出现错误时,先修改状态码,然后后面的工作也不需要做了,直接goto语句跳转到解析出错问题的地方;
- 当出现错误时,上层也需要知道错误码和错误原因,所以我们通过序列化操作将错误码和错误原因通过输出型参数返回给上层;
- 另外,还需要一个可以解析我们状态码出错的出错原因的一个函数(这个函数后面再实现);
- 如果程序编译、运行都成功,我们需要将程序的运行结果和程序运行完的错误结果也通过序列化返回给上层;
- 程序运行成功的结果和运行完错误的结果在temp临时文件中,我们只需要实现一个ReadFile文件读取的接口将信息读取写入序列化的kv结构中。
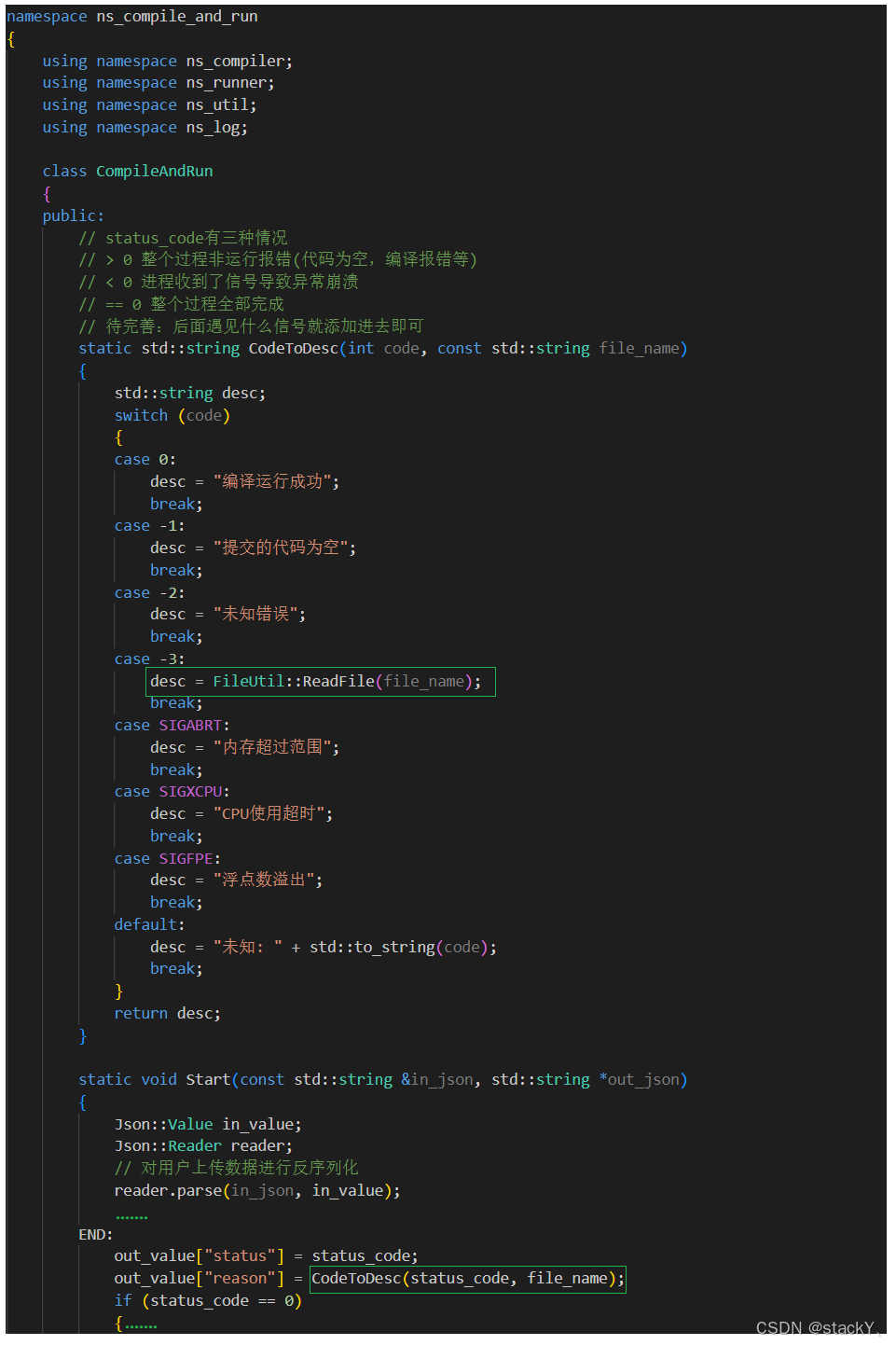
1.4.2 状态码解析
我们通过switch case语句对依次对各种状态码进行分别解析,这里需要注意的是,当状态码是-3时,代表的是编译报错,那么我们想知道编译报错的具体信息,所以我们依旧读取指定错误文件中的错误信息,所以在调用状态码解析的接口时我们还要传递文件名:
1.4.3 生成唯一文件名
生成唯一文件名的这些接口我们都实现在comm模块的util.hpp中;
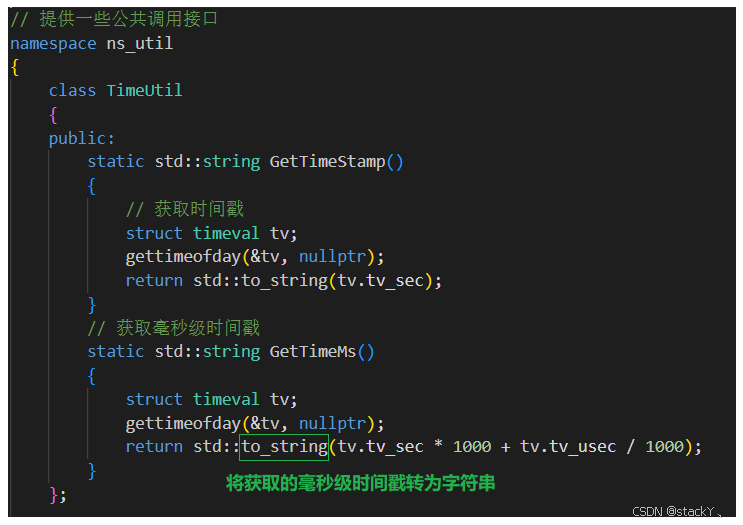
在这里我们采用毫秒级时间戳 + 原子性递增唯一值来实现一个唯一的文件名;
所以我们在TimeUtil类中实现一个获取毫秒级时间戳的接口,用到的接口和获取时间戳的接口一样:
我们在FileUtil类中实现生成唯一文件名的接口(comm模块的util.hpp中):
还存在一个原子性递增的唯一值的问题,我们不再使用定义变量再加锁的功能了,我们直接使用C++11中的原子变量(atomic):
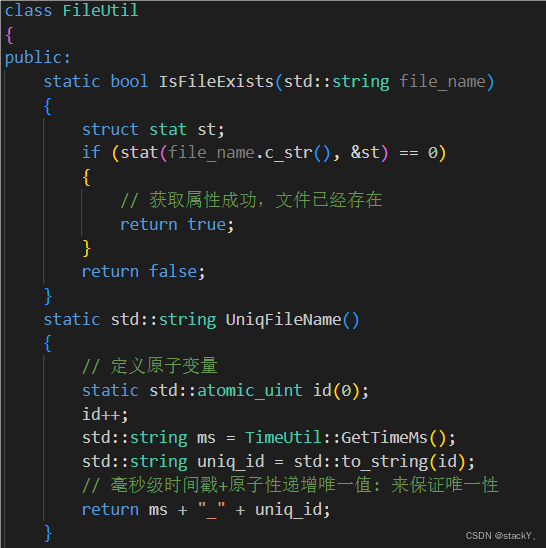
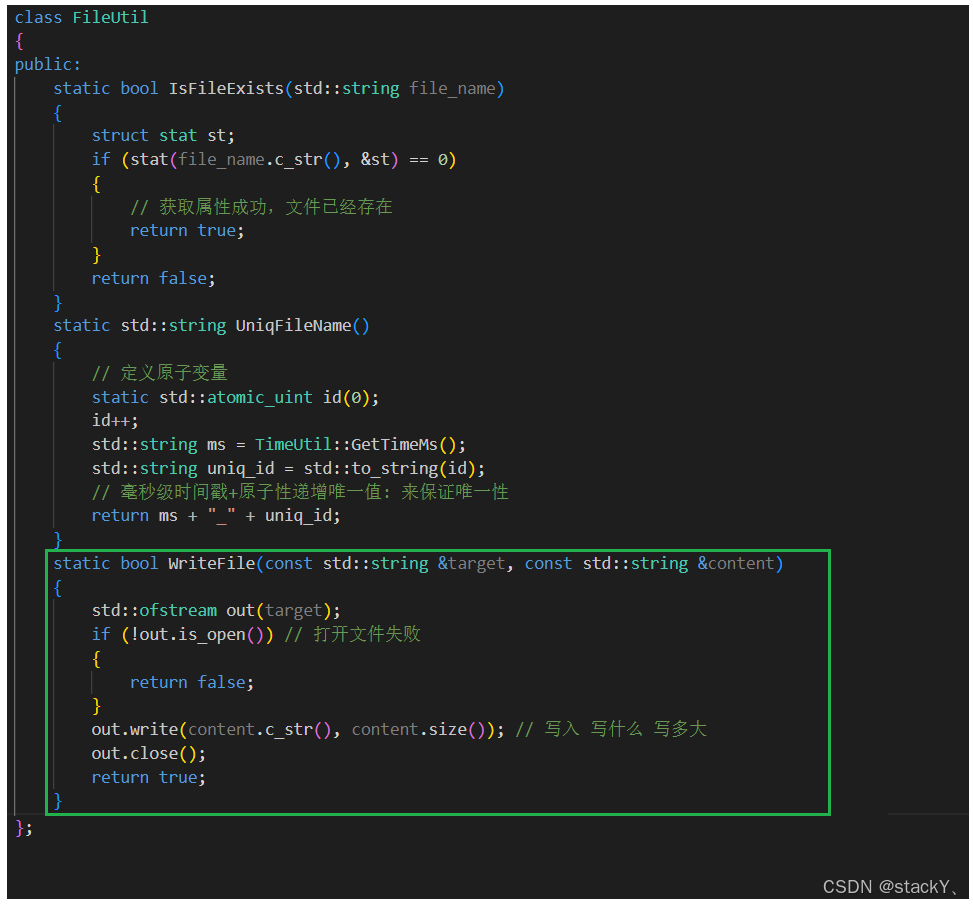
1.4.4 写文件与读文件
WriteFile接口:
读取文件的这些接口我们用C++的文件读取实现,这里就不做过多介绍了:
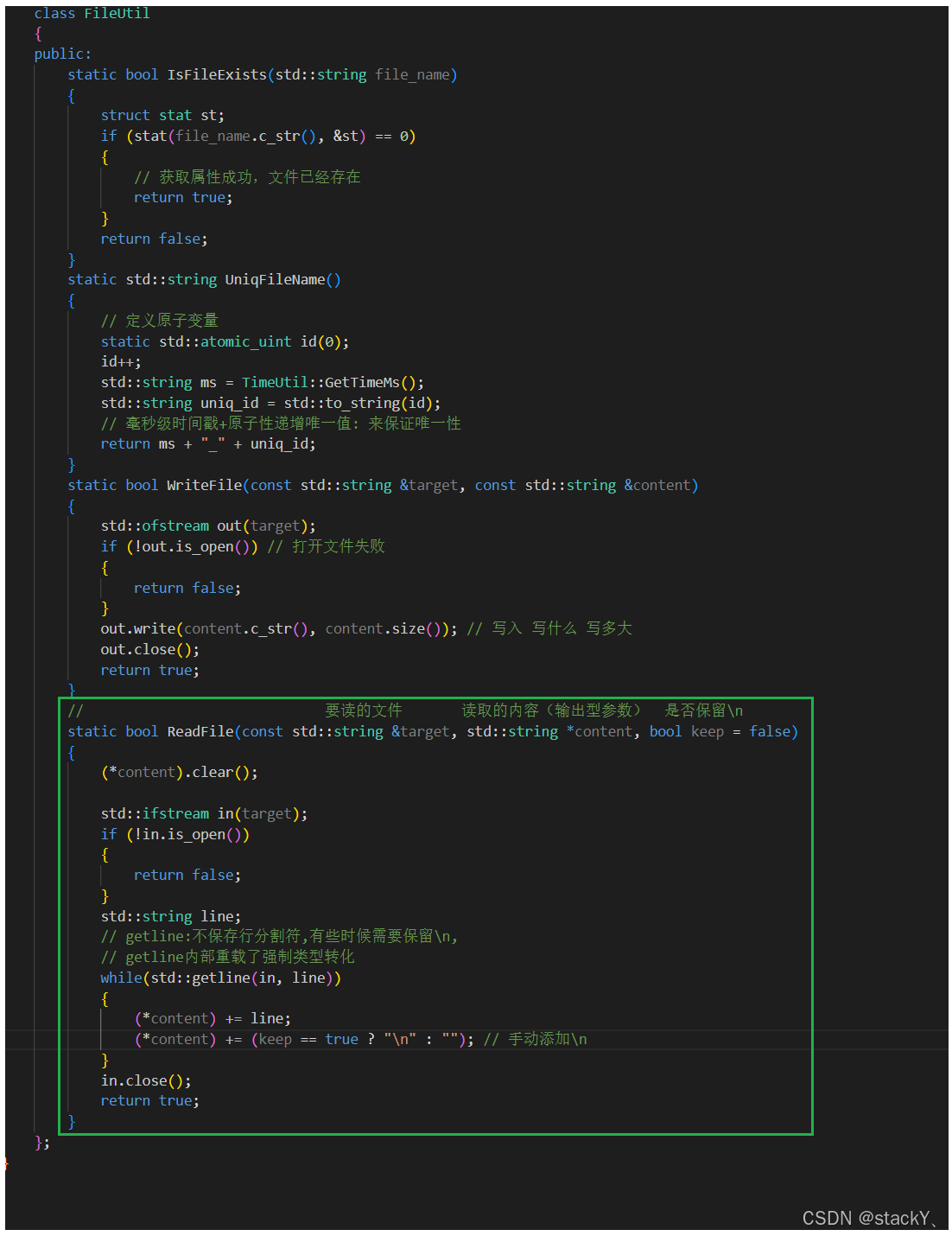
ReadFile接口:
读取文件的接口我们在设计的时候需要注意,从哪个文件中读取,读到的内容是需要返回给上层的,我们使用getline读取的时候他是不会保存\n的,所以我们要将ReadFile的返回值设为bool类型,提供一个输入型参数用来获取要读取的文件名,一个输出型参数将读取到的内容返回给上层,还需要提供一个标志位,是否保存\n;
当这个接口这样子实现之后,我们之前写的代码就需要进行调整了:

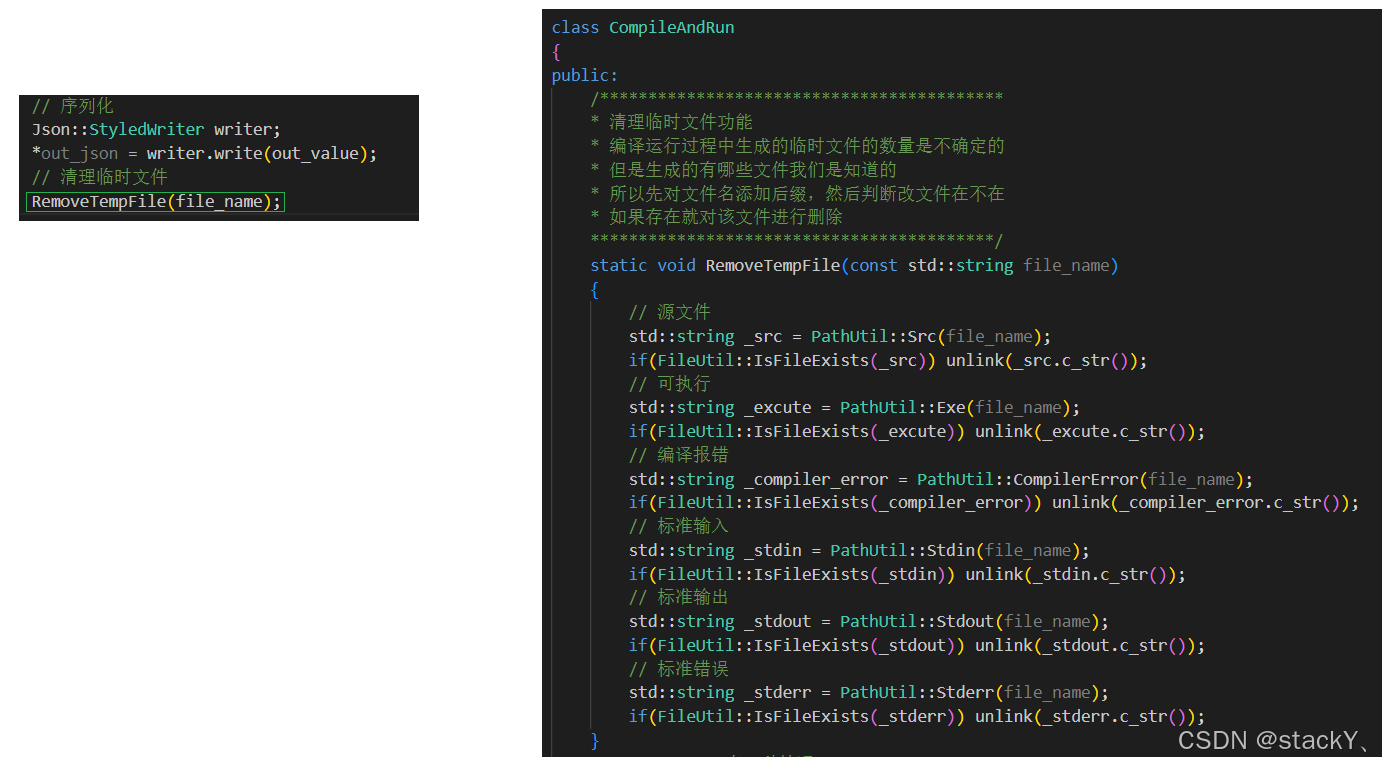
1.4.5 删除临时文件
程序在编译运行之后最多会生成6个临时文件,那么如果这些文件不及时清理,就会堆积的越来越多,对我们的服务器造成负担,所以我们可以在compile_run.hpp的最后面添加一个删除临时文件的接口:
要删除临时文件我们需要用到的系统调用接口是unlink:
但是有一个问题:我们不清楚到底会生成多少个临时文件,但是我们清楚都会生成哪些临时文件,所以我们可以通过文件名添加后缀的方式再调用之前写的判断一个文件是否存在的接口用来删除临时文件:
后面如果我们想要观察这些临时文件,直接将RemoveTempFile接口注释掉即可。

1.5 compile_server.cc
在compile_server.cc文件中我们主要进行网络服务,通过网络来将我们的编译运行的代码结合在一起,实现网络化的功能;
1.5.1 手动模拟实现网络服务
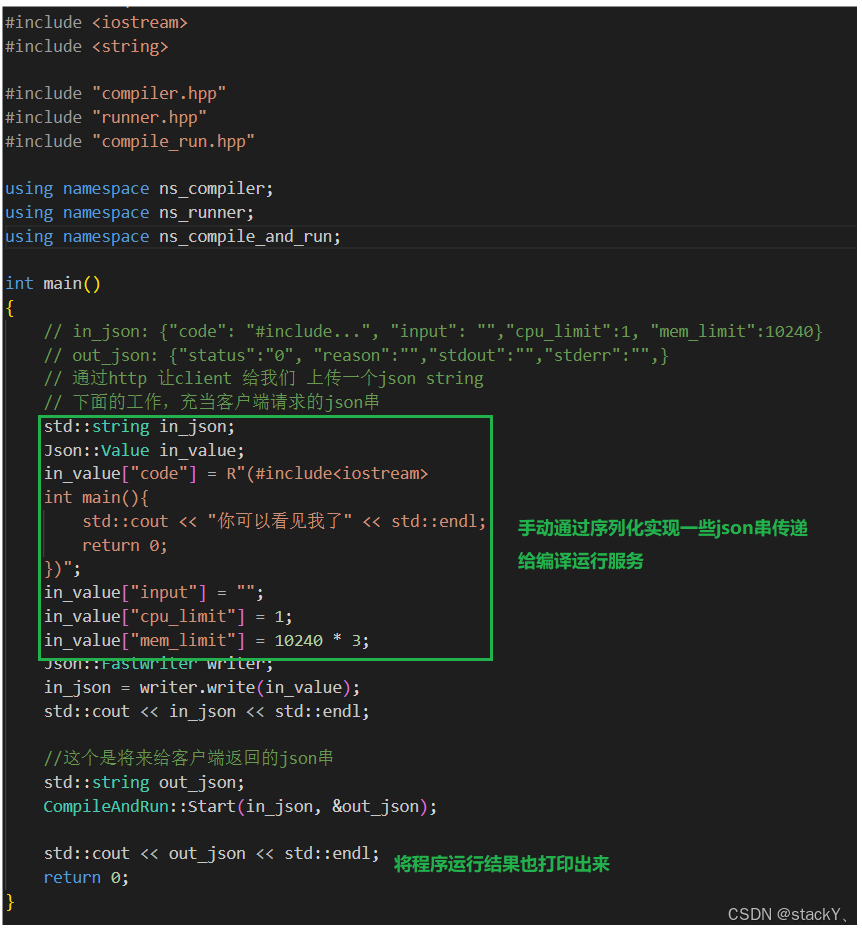
基于上面的内容,我们实现了对代码的编译功能,对编译好的程序运行的功能,那么写了这么多,到底能不能正常运行呢?我们可以在compile_server.cc中进行一些测试代码的编写:
我们可以手动的通过序列化传递一些json串,模拟实现一下网络服务传递的json串,然后我们将我们的程序执行的结果也打印出来:
同时我们来编写一下Makefile;因为我们使用了jsoncpp,所以需要在编译选项中用-l选项引入jsoncpp库:
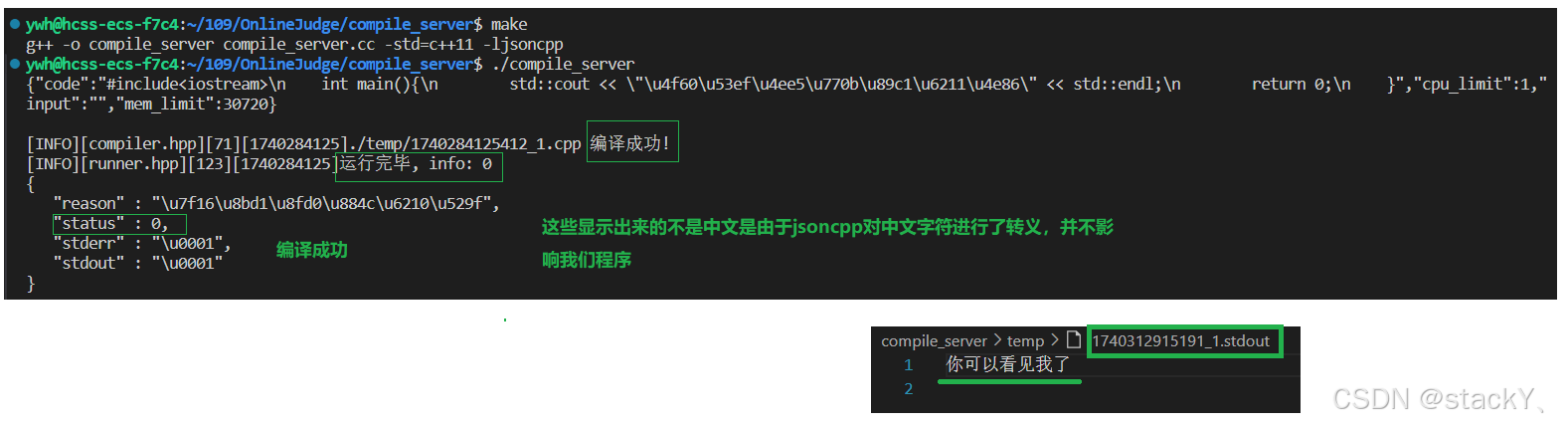
compile_server:compile_server.cc g++ -o $@ $^ -std=c++11 -ljsoncpp .PHONY:clean clean: rm -f compile_server此时我们来编译运行一下:
1.5.2 网络服务编写
上面我们手动模拟了一下从网络上请求过来的json string,那么现在我们来实现网络请求服务,当然我们的网络服务我们也可以自己实现一个TCP请求,但是我们可以直接使用现成的cpp-httplib来进行网络请求;
这里建议下载cpp-httplib 0.7.15 版本的(比较稳定)
cpp-httplib gitee链接:https://gitee.com/yuanfeng1897/cpp-httplib? _from=gitee_search
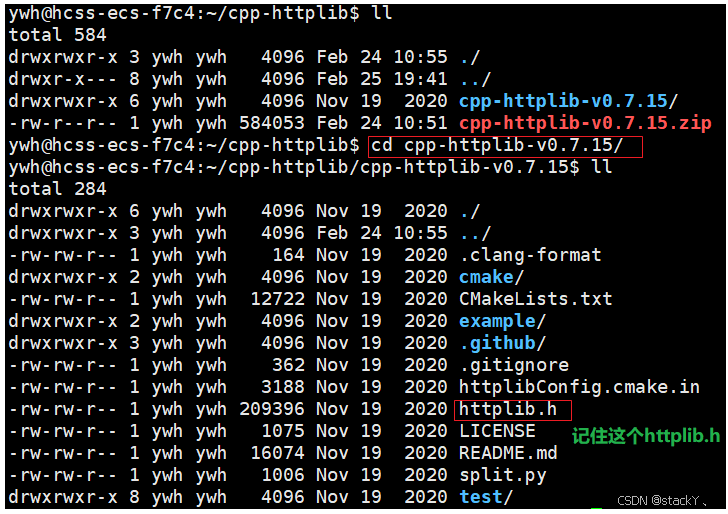
- 我们下载好压缩包之后直接上传到我们的服务器然后解压到一个任意的路径下面(比较好找的路径下面);
- 要使用httplib只需要把这个头文件拷贝至我们自己的文件下然后包含这个头文件就可以使用了;
- 所以我们直接把这个httplib.h文件直接拷贝到我们的comm模块下;
- 包含对应的头文件即可
- 搭建服务端的教程(httplib使用)可以移步至这个博客:https://blog.youkuaiyun.com/weixin_55582891/article/details/141139338
- 由于这个网络服务使用了原生线程库,所以我们的Makefile文件也需要引入pthread库
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











