







1、安装环境介绍
1-1 节点介绍
| 操作系统版本 | IP | 主机名 | 角色类型 |
|---|---|---|---|
| Centos Stream 9 | 10.10.10.100 | master | Master |
| Centos Stream 9 | 10.10.10.101 | slave1 | Slave1 |
| Centos Stream 9 | 10.10.10.102 | slave2 | Slave2 |
1-2 组件版本介绍
| 组件名称 | 组件版本 |
|---|---|
| Hadoop | 3.3.6 |
| Java | 1.8 |
| Flume | 1.11.0 |
| Hive | 3.1.2 |
| Zookeeper | 3.6.3 |
| Flink | 1.18.1 |
| Hbase | 2.5.4 |
| Hudi | 0.15.0 |
| Kafka | 3.6.2 |
| Sqoop | 1.4.7 |
2、准备工作
2-1 主机名
Master
[root@master ~]# hostnamectl set-hostname master
[root@master ~]# bash
Slave1
[root@slave1 ~]# hostnamectl set-hostname slave1
[root@slave1 ~]# bash
Slave2
[root@slave2 ~]# hostnamectl set-hostname slave2
[root@slave2 ~]# bash
2-2 SSH免密
Master
[root@master ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa
Your public key has been saved in /root/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:rhv7ktMqKUpwQehOj/0IitXSzcXqNAbOqnLEsflT6CE root@master
The key's randomart image is:
+---[RSA 3072]----+
| .. |
|.. |
|. . . |
| o... o |
|+.=O = oS |
|.=EoB O. |
|o+.*oB.+. |
|= +.*.=+. |
|++ . o=*. |
+----[SHA256]-----+
Master
[root@master ~]# ssh-copy-id 10.10.10.101
[root@master ~]# ssh-copy-id 10.10.10.102
[root@master ~]# ssh-copy-id 10.10.10.100
这个地方需要注意,三台机器都需要做SSH免密操作,否则启动集群会出现权限不够等错误
2-3 修改Hosts文件
[root@master ~]# vim /etc/hosts
10.10.10.100 master
10.10.10.101 slave1
10.10.10.102 slave2
[root@master ~]# scp /etc/hosts root@slave1:/etc/hosts
[root@master ~]# scp /etc/hosts root@slave2:/etc/hosts
2-4 防火墙
Master
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
[root@master ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
[root@master ~]# reboot #必做操作,否则Selinux修改不生效
Slave1
[root@slave1 ~]# systemctl stop firewalld
[root@slave1 ~]# systemctl disable firewalld
[root@slave1 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
[root@slave1 ~]# reboot #必做操作,否则Selinux修改不生效
Slave2
[root@slave2 ~]# systemctl stop firewalld
[root@slave2 ~]# systemctl disable firewalld
[root@slave2 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
[root@slave2 ~]# reboot #必做操作,否则Selinux修改不生效
2-5 集群用户权限
Master
#最末尾添加
[root@master opt]# vim /etc/profile
#USER
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
[root@master opt]# source /etc/profile
[root@master opt]# scp /etc/profile root@slave1:/etc/
[root@master opt]# scp /etc/profile root@slave2:/etc/
Slave1
[root@slave1 opt]# source /etc/profile
Slave2
[root@slave2 opt]# source /etc/profile
3、部署
3-1 Java
将jdk上传至三台机器的
Master
[root@master opt]# tar -zxvf jdk-8u291-linux-x64.tar.gz
[root@master opt]# mv jdk1.8.0_291 jdk
#最末尾添加
[root@master opt]# vim /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/jdk
export PATH=$JAVA_HOME/bin:$PATH
[root@master opt]# source /etc/profile
[root@master opt]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
[root@master opt]# scp -r /opt/jdk root@slave1:/opt/jdk
[root@master opt]# scp -r /opt/jdk root@slave2:/opt/jdk
[root@master opt]# scp -r /etc/profile root@slave1:/etc/
[root@master opt]# scp -r /etc/profile root@slave2:/etc/
Slave1
[root@slave1 opt]# source /etc/profile
[root@slave1 opt]# java -version
Slave2
[root@slave2 opt]# source /etc/profile
[root@slave2 opt]# java -version
3-2 Hadoop
Master
[root@master opt]# tar -zxvf hadoop-3.3.6.tar.gz
[root@master opt]# mv hadoop-3.3.6 hadoop
[root@master opt]# vim /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@master opt]# source /etc/profile
[root@master hadoop]# cd etc/hadoop
#注意路径哦,是hadoop下的etc/hadoop
[root@master hadoop]# pwd
/opt/hadoop/etc/hadoop
3-2-1 Hadoop环境变量
Master
[root@master hadoop]# vim hadoop-env.sh
export JAVA_HOME=/opt/jdk
[root@master hadoop]# vim mapred-env.sh
export JAVA_HOME=/opt/jdk
[root@master hadoop]# vim yarn-env.sh
export JAVA_HOME=/opt/jdk
#三个文件最末尾都加入JAVA_HOME环境变量
3-2-2 HDFS
Master
[root@master hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
</property>
</configuration>
##fs.defaultFS:HDFS默认访问路径,也就是NameNode的访问地址
##hadoop.tmp.dir:Hadoop数据文件的存放目录。如果不配置这个默认指向到/tmp目录下,但是/tmp目录会在重启后自动清空,会导致Hadoop文件系统数据丢失
Master
[root@master hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
</configuration>
##dfs.replication:文件在HDFS系统中存放的副本数
##dfs.permissions.enabled:不检查用户权限
##dfs.namenode.name.dir:NameNode节点数据在本地文件系统的存放位置
##dfs.datenode.name.dir:DataNode节点数据在本地文件系统的存放位置
Master
[root@master hadoop]# vim workers
master
slave1
slave2
3-2-3 YARN
Master
[root@master hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
</configuration>
##mapreduce.framework.name:指定MapReduce应用程序主进程添加环境变量
##为MapReduce应用主进程添加环境变量
##为MapReduce Map任务添加环境变量
##为MapReduce Reduce任务添加环境变量
Master
[root@master hadoop]# vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
##yarn.nodemanager.aux-services:NodeManager上运行的附属服务,需要配成mapreduce_shuffle才可运行MapReduce程序,YARN提供了该配置项用于NodeManager上扩展自定义服务,MapReduce的Shuffle功能正是一种扩展服务
##yarn.resourcemanager.hostname:指定ResourceManager运行的节点。不添加的话,默认在执行YARN启动明亮的节点启动
3-2-4 Slave节点配置
Master
[root@master hadoop]# scp -r /opt/hadoop root@slave1:/opt/hadoop
[root@master hadoop]# scp -r /opt/hadoop root@slave2:/opt/hadoop
3-2-5 NameNode格式化
[root@master hadoop]# hdfs namenode -format
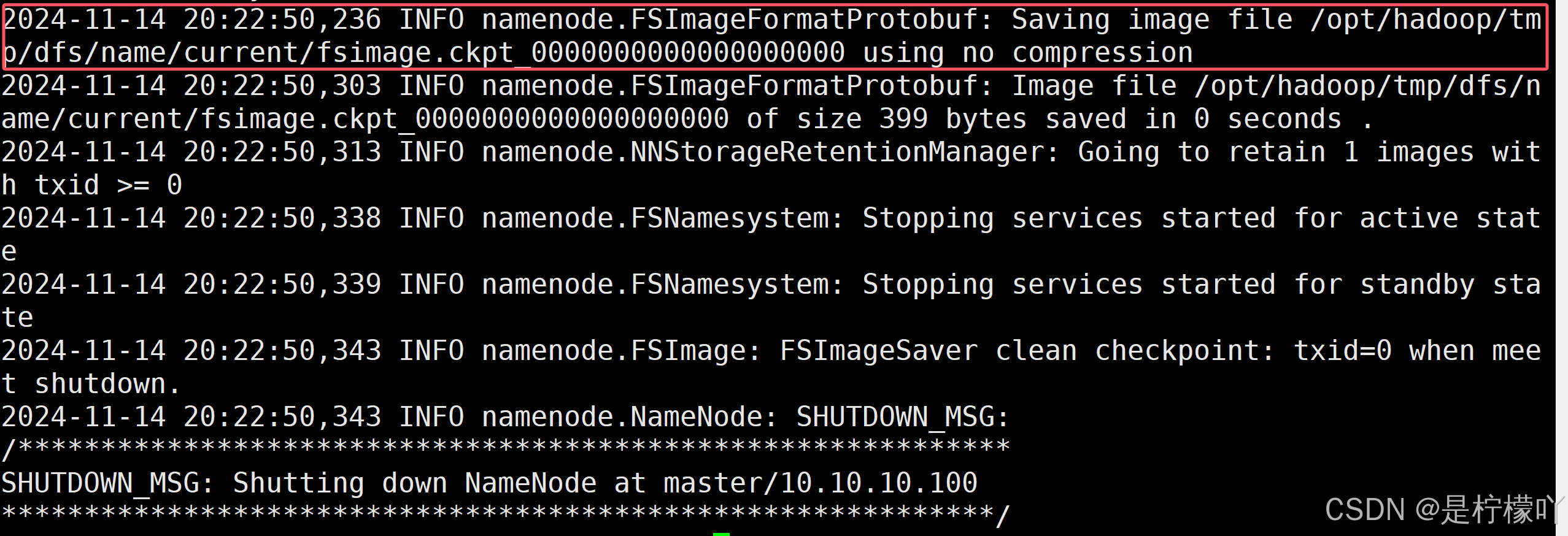
3-2-6 启动Hadoop
Master
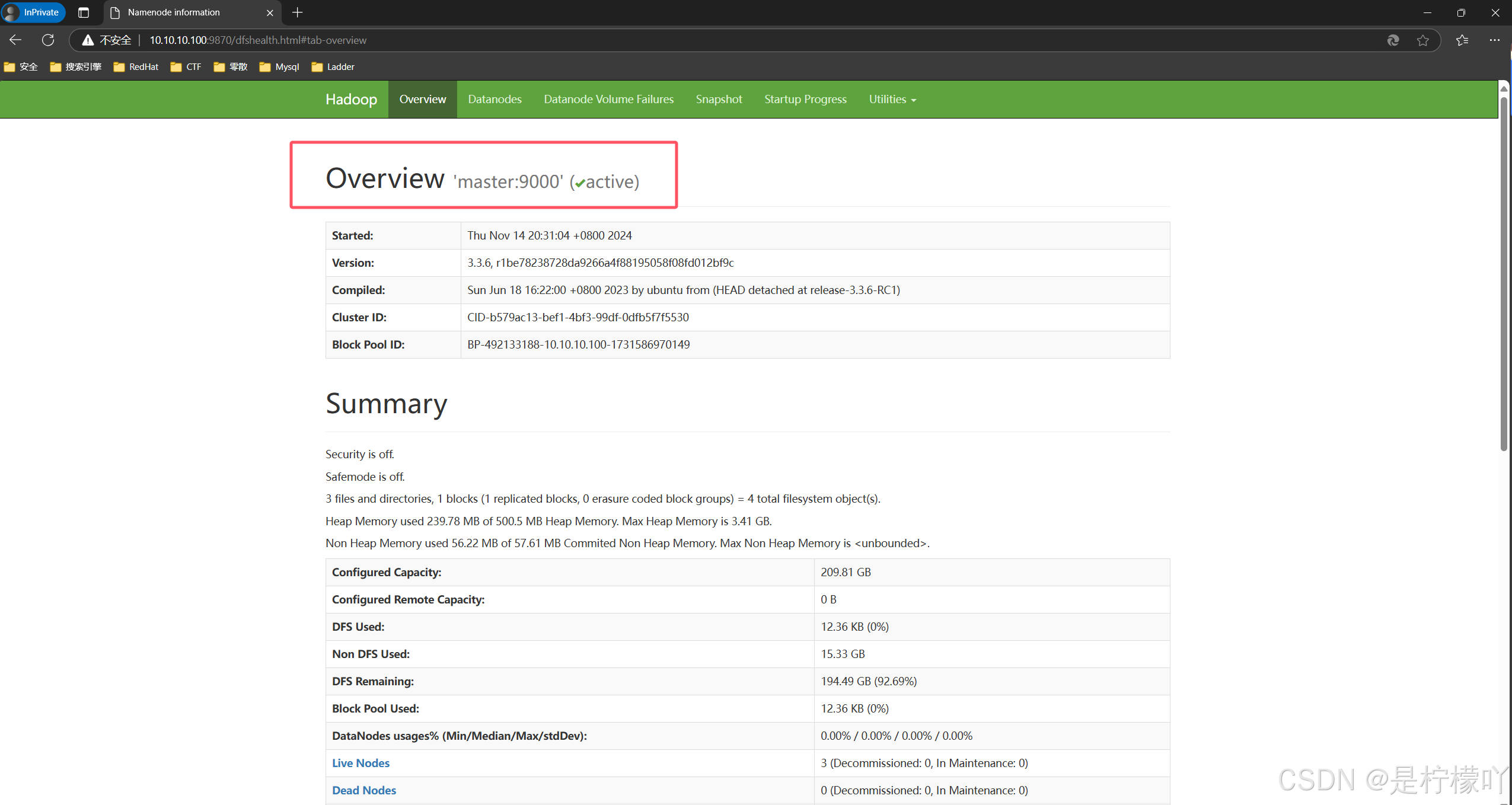
[root@master hadoop]# start-all.sh
[root@master hadoop]# jps
5684 SecondaryNameNode
5927 ResourceManager
5240 NameNode
6090 NodeManager
6476 Jps
5454 DataNode
Slave1
[root@slave1 opt]# jps
2327 NodeManager
2490 Jps
2188 DataNode
Slave2
[root@slave2 opt]# jps
2410 NodeManager
2572 Jps
2271 DataNode
3-2-7 HDFS测试
#在HDFS根目录创建一个input文件夹
[root@master hadoop]# hdfs dfs -mkdir /input
#将Hadoop安装目录下的文件README.txt上传到新建的input文件夹里面
[root@master hadoop]# hdfs dfs -put /opt/hadoop/README.txt /input
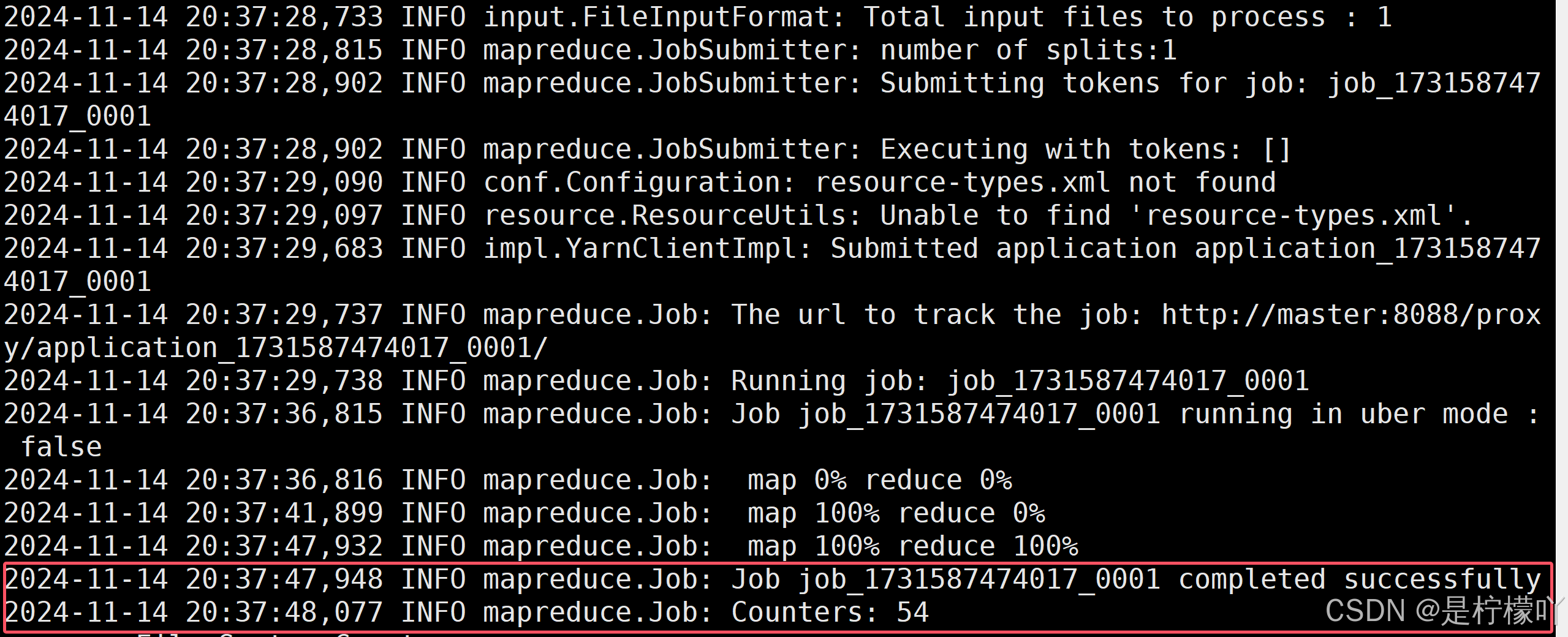
3-2-8 MapReduce测试
##注意目录
[root@master hadoop]# pwd
/opt/hadoop
[root@master hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input /output
3-3 Zookeeper
3-3-1 配置Zookeeper
Master
[root@master opt]# tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz
[root@master opt]# mv apache-zookeeper-3.6.3-bin zookeeper
#创建Zookeeper数据目录(注意目录哦)
[root@master opt]# cd zookeeper/
[root@master zookeeper]# mkdir dataDir
#编写配置文件
[root@master zookeeper]# cd conf
[root@master conf]# pwd
/opt/zookeeper/conf
[root@master conf]# vim zoo.cfg
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/opt/zookeeper/dataDir
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
##initLimit:集群中Follower服务器初始化连接等待时长(超时时间)。tickTime(毫秒)*initLimit
##syncLimit:集群中Follower与Leader服务器之间发送消息以及请求/应答等待的最多心跳数。tickTime(毫秒)*syncLimit
##server.id:标识不同的Zookeeper服务器,集群中需要唯一
##dataDir:数据目录
##clientPort:客户端连接Zookeeper服务器的端口
#配置Myid文件
[root@master dataDir]# pwd
/opt/zookeeper/dataDir
[root@master dataDir]# cat myid
1
#传输Slave节点
[root@master dataDir]# scp -r /opt/zookeeper root@slave1:/opt/
[root@master dataDir]# scp -r /opt/zookeeper root@slave2:/opt/
#修改Slave节点的myid文件
Slave1
[root@slave1 ~]# cat /opt/zookeeper/dataDir/myid
2
Slave2
[root@slave2 ~]# cat /opt/zookeeper/dataDir/myid
3
3-3-2 启动Zookeeper
#每台节点都需要运行启动命令
Master
[root@master zookeeper]# pwd
/opt/zookeeper
[root@master zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@master zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
Slave1
[root@slave1 zookeeper]# pwd
/opt/zookeeper
[root@slave1 zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave1 zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
Slave2
[root@slave2 zookeeper]# pwd
/opt/zookeeper
[root@slave2 zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave2 zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
3-3-3 测试Zookeeper
#测试Zookeeper连接,其他节点也可以
Master
[root@master zookeeper]# bin/zkCli.sh -server slave1:2181
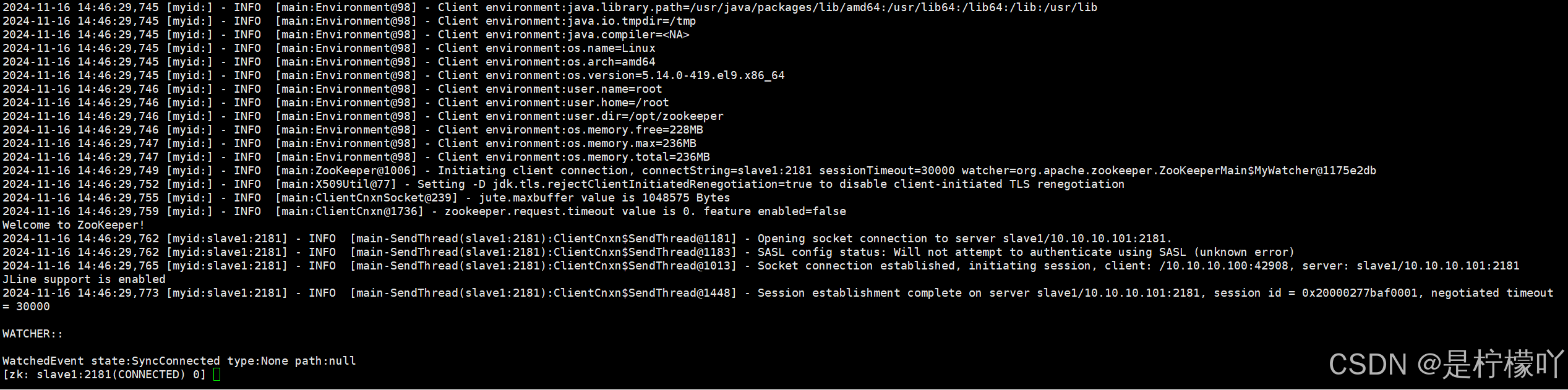
#查询节点列表
[zk: slave1:2181(CONNECTED) 0] ls /
[zookeeper]
#创建节点
[zk: slave1:2181(CONNECTED) 1] create /zk "myData"
Created /zk
#创建子节点,关联元数据
[zk: slave1:2181(CONNECTED) 2] create /zk/slave1 "childData"
Created /zk/slave1
3-4 Hbase
3-4-1 配置Hbase
Master
[root@master opt]# mv hbase-2.5.4 hbase
[root@master opt]# tar -zxvf hbase-2.5.4-bin.tar.gz
[root@master conf]# pwd
/opt/hbase/conf
[root@master conf]# vim hbase-env.sh
export JAVA_HOME=/opt/jdk
export HBASE_MANAGES_ZK=false
#禁用Hbase自带的Zookeeper
[root@master conf]# vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase/zkData</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
"hbase-site.xml" 47L, 1563B 已写入
[root@master conf]# vim regionservers
[root@master conf]# cat regionservers
master
slave1
slave2
[root@master opt]# pwd
/opt
[root@master opt]# scp -r hbase root@slave1:/opt/
[root@master opt]# scp -r hbase root@slave2:/opt/
3-4-2 启动Hbase
[root@master hbase]# bin/start-hbase.sh
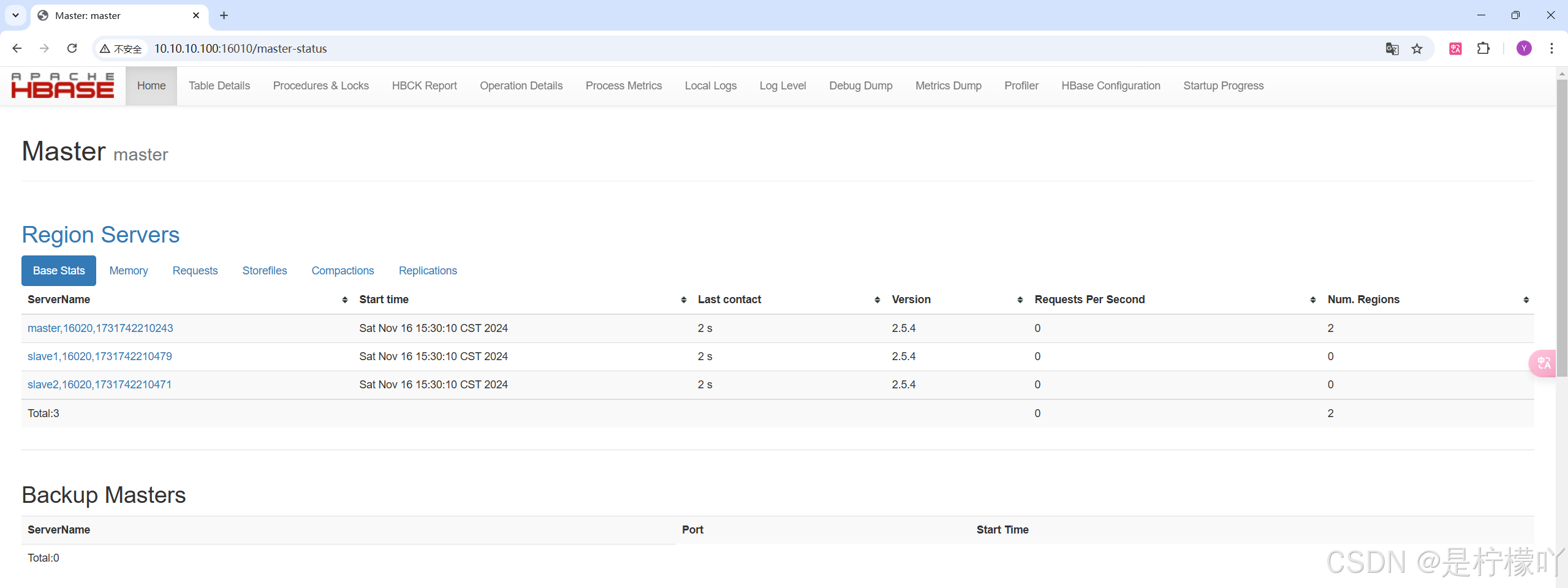
3-4-3 测试Hbase
Master
[root@master hbase]# bin/hbase shell
#创建表
hbase:002:0> create 't1','f1'
2024-11-16 15:33:44,700 INFO [main] client.HBaseAdmin (HBaseAdmin.java:postOperationResult(3591)) - Operation: CREATE, Table Name: default:t1, procId: 27 completed
Created table t1
Took 0.9622 seconds
=> Hbase::Table - t1
#添加数据
hbase:004:0> put 't1','row1','f1:name','zhangsan'
Took 0.0077 seconds
hbase:005:0> put 't1','row2','f1:age','18'
Took 0.7032 seconds
#全表扫描
hbase:009:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:name, timestamp=2024-11-16T15:35:20.903, value=zhangsan
row2 column=f1:age, timestamp=2024-11-16T15:35:54.440, value=18
2 row(s)
Took 0.0892 seconds
3-5 Hive
3-5-1 配置Hive
#Hive不需要集群形式,直接在单独节点安装即可,但是需要Mysql
Master
[root@master ~]# yum -y install mysql*
[root@master ~]# systemctl enable --now mysqld
#设置一个Root密码,Mysql8.0安装好之后默认没有密码,直接回车登陆即可
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
mysql> alter user root@'localhost' identified by '123456';
Query OK, 0 rows affected (0.01 sec)
#设置Mysql可以使用Root用户进行远程登录
mysql> update user set host='%' where user='root';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
#创建Hive的数据库
mysql> create database hive_db;
Query OK, 1 row affected (0.01 sec)
#创建Hive用户,密码也是Hive
mysql> create user hive identified by 'hive';
Query OK, 0 rows affected (0.00 sec)
#赋予Hive用户权限
mysql> grant all privileges on hive_db.* to hive@'%';
Query OK, 0 rows affected (0.00 sec)
#刷新权限
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
#配置Hive
[root@master opt]# tar -zxvf apache-hive-3.1.2-bin.tar.gz
[root@master opt]# mv apache-hive-3.1.2-bin hive
#末尾继续添加
[root@master opt]# vim /etc/profile
#HIVE_HOME
export HIVE_HOME=/opt/hive
export PATH=$HIVE_HOME/bin:$PATH
[root@master opt]# source /etc/profile
[root@master opt]# hive --version
Hive 3.1.2
Git git://HW13934/Users/gates/tmp/hive-branch-3.1/hive -r 8190d2be7b7165effa62bd21b7d60ef81fb0e4af
Compiled by gates on Thu Aug 22 15:01:18 PDT 2019
From source with checksum 0492c08f784b188c349f6afb1d8d9847
#注意路径
[root@master conf]# pwd
/opt/hive/conf
[root@master conf]# mv hive-env.sh.template hive-env.sh
export HADOOP_HOME=/opt/hadoop
#需要在HDFS创建目录,做之前确认自己的Hadoop集群是正常的
#tmp文件夹之前测试创建过,可以通过Web页面删除重新创建,也可以直接赋权
[root@master conf]# hadoop fs -mkdir /tmp
[root@master conf]# hadoop fs -mkdir -p /user/hive/warehouse
[root@master conf]# hadoop fs -chmod g+w /tmp
[root@master conf]# hadoop fs -chmod g+w /user/hive/warehouse
##/tmp:Hive任务在HDFS中的缓存目录
##/user/hive/warehouse:Hive数据仓库目录,用于存储Hive创建的数据库
[root@master conf]# pwd
/opt/hive/conf
[root@master conf]# mv hive-default.xml.template hive-site.xml
#清空里面内容即可
[root@master conf]# vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.10.10.100:3306/hive_db?createDatabaseIfNotExist=tru
e</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/src/hive</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/src/hive</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/src/hive</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/usr/local/src/hive</value>
</property>
</configuration>
##还需要将mysql-connector-java-8.0.29.jar上传到hive安装目录下面的lib目录中
[root@master conf]# ls /opt/hive/lib/ | grep mysql-conn
mysql-connector-java-8.0.29.jar
3-5-2 启动Hive
#初始化Hive
[root@master lib]# schematool -dbType mysql -initSchema
Initialization script completed
schemaTool completed
#提示这个信息代表初始化成功
#如果初始化失败了,需要清空Mysql中hive_db数据库中的所有表才可以重新初始化,否则会报错
#登录数据库可以发现生成了很多存放元数据的表
mysql> use hive_db
mysql> show tables;
| WM_MAPPING |
| WM_POOL |
| WM_POOL_TO_TRIGGER |
| WM_RESOURCEPLAN |
| WM_TRIGGER |
| WRITE_SET |
+-------------------------------+
74 rows in set (0.01 sec)
#任意目录登录Hive即可
[root@master conf]# hive
/usr/bin/which: no hbase in (/opt/hive/bin:/opt/hadoop/bin:/opt/hadoop/sbin:/opt/jdk/bin:/root/.local/bin:/root/bin:/opt/hadoop/bin:/opt/hadoop/sbin:/opt/jdk/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = b1e5e75c-343f-4b97-9ee5-c4410f0ca636
Logging initialized using configuration in jar:file:/opt/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = b7945984-7b12-4476-8703-56839862019f
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
3-5-3 测试Hive
hive> create table student(id int, name string);
OK
Time taken: 0.539 seconds
hive> show tables;
OK
student
Time taken: 0.132 seconds, Fetched: 1 row(s)

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









