 信息熵与信息论基础
信息熵与信息论基础





 本文深入探讨了信息熵的概念,它是衡量随机事件不确定性的关键指标。通过数学公式和直观的例子,文章解释了信息熵如何随事件可能性的变化而变化,以及它在不同场景中的应用,包括联合熵、条件熵、互信息和最大熵模型。
本文深入探讨了信息熵的概念,它是衡量随机事件不确定性的关键指标。通过数学公式和直观的例子,文章解释了信息熵如何随事件可能性的变化而变化,以及它在不同场景中的应用,包括联合熵、条件熵、互信息和最大熵模型。
1、简介
- 信息熵是随机事件不确定性的度量
- 信息熵越
大,不确定性越高
2、公式
H ( X ) = − ∑ i = 1 n p ( x i ) log 2 p ( x i ) = ∑ i = 1 n p ( x i ) log 2 1 p ( x i ) H(X) = - \sum_{i=1}^{n} {p(x_i) \log_2 p(x_i)} = \sum_{i=1}^{n} {p(x_i) \log_2\frac{1}{p(x_i)}} H(X)=−i=1∑np(xi)log2p(xi)=i=1∑np(xi)log2p(xi)1
先看下 − x log 2 x - x \log_2 x −xlog2x 的函数图像:
import numpy as np, matplotlib.pyplot as mp
X = np.linspace(0.001, 1, 1001)
Y = - X * np.log2(X)
mp.plot(X, Y)

如图所示,概率P取值在0~1,概率为0或1时取最小值0(
lim
x
→
0
−
x
log
2
x
=
0
\lim_{x\rightarrow0} - x \log_2 x = 0
limx→0−xlog2x=0)
3、举个栗子
栗子1
黑箱中10个球,分红白2色,随机抽取1个:
H
=
P
(
红
)
log
2
1
P
(
红
)
+
P
(
白
)
log
2
1
P
(
白
)
H=P(红) \log_2\frac{1}{P(红)} + P(白) \log_2\frac{1}{P(白)}
H=P(红)log2P(红)1+P(白)log2P(白)1
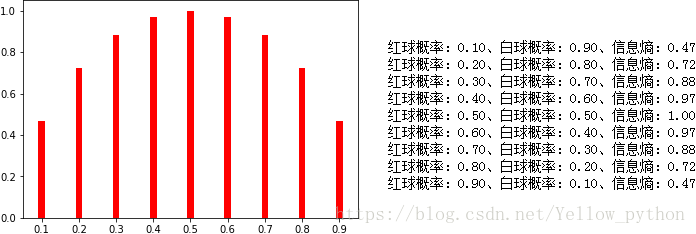
若5红5白,信息熵为1.00,难以确定会抽到的哪个颜色;
若9红1白,信息熵为0.47,有较大几率抽到红球,不确定性较小;
若全为红球,则信息熵为0,必定抽到红球,无不确定性。
from math import log2
import matplotlib.pyplot as mp
for x in range(1, 10):
p1 = x / 10
p2 = 1 - p1
X = [p1, p2]
H = - sum([p * log2(p) for p in X])
print('红球概率:%.2f、白球概率:%.2f、信息熵:%.2f' % (p1, p2, H))
mp.bar(p1, H, color='r', width=0.018)
栗子2
import numpy as np, matplotlib.pyplot as mp
X = np.arange(1, 257) # 物种数取值范围
H = []
for x in X:
P = [1 / x for _ in range(x)] # 物种数为x时,概率的集合
H.append(- sum([p * np.log2(p) for p in P]))
mp.xlabel('species')
mp.ylabel('information entropy')
mp.plot(X, H)
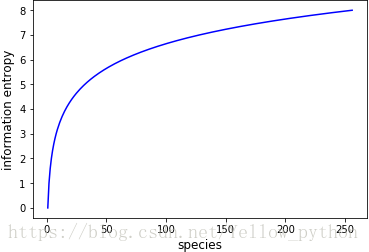
如图,横坐标表示种类,纵坐标表示信息熵
种类是1时,信息熵为0;种类是256时,信息熵为8;种类越多,信息熵越大。
4、相关补充
联合熵
- 二维随机变量X、Y的不确定性的度量
H ( X , Y ) = − ∑ i = 1 n ∑ j = 1 n P ( x i , y j ) log P ( x i , y j ) H(X,Y) = - \sum_{i=1}^{n} \sum_{j=1}^{n} {P(x_i,y_j) \log P(x_i,y_j)} H(X,Y)=−i=1∑nj=1∑nP(xi,yj)logP(xi,yj)
条件熵
- 用于衡量:随机变量X发生的条件下,随机变量Y的不确定性
H ( Y ∣ X ) = − ∑ x , y P ( x , y ) log P ( y ∣ x ) H(Y|X) = - \sum_{x,y} {P(x,y) \log P(y|x)} H(Y∣X)=−x,y∑P(x,y)logP(y∣x)
互信息
- 随机变量X、Y之间相互依赖性的量度
I ( X , Y ) = − ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log P ( x , y ) P ( x ) P ( x ) I(X,Y) = - \sum_{x \in X} \sum_{y \in Y} {P(x,y) \log \frac {P(x,y)}{P(x)P(x)}} I(X,Y)=−x∈X∑y∈Y∑P(x,y)logP(x)P(x)P(x,y)

最大熵模型
-
白话解释:
- 满足一定约束条件下,选择熵最大的模型 e.g.
-
- 对于随机变量
X
X
X,其可能的取值为
{
A
,
B
,
C
}
\{A,B,C\}
{A,B,C},没有任何约束的情况下,各个值等概率时模型的熵值最大:
P ( A ) = P ( B ) = P ( C ) = 1 3 P(A)=P(B)=P(C)=\frac{1}{3} P(A)=P(B)=P(C)=31
- 对于随机变量
X
X
X,其可能的取值为
{
A
,
B
,
C
}
\{A,B,C\}
{A,B,C},没有任何约束的情况下,各个值等概率时模型的熵值最大:
-
- 当给定一个约束
P
(
A
)
=
1
2
P(A)=\frac{1}{2}
P(A)=21时,满足该约束条件下的最大熵模型则变成:
P ( A ) = 1 2 ; P ( B ) = P ( C ) = 1 4 P(A)=\frac{1}{2};P(B)=P(C)=\frac{1}{4} P(A)=21;P(B)=P(C)=41
- 当给定一个约束
P
(
A
)
=
1
2
P(A)=\frac{1}{2}
P(A)=21时,满足该约束条件下的最大熵模型则变成:


















 4717
4717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











