




 本文详细介绍Hadoop集群的搭建过程,包括环境配置、软件安装、集群启动等关键步骤。
本文详细介绍Hadoop集群的搭建过程,包括环境配置、软件安装、集群启动等关键步骤。
文章目录
0、集群规划
| 环境 | 版本 | 命令 or 路径 | 备注 |
|---|---|---|---|
| CentOS | centos-release-7-5.1804.el7.centos.x86_64 | rpm -q centos-release | 开源的Linux操作系统 |
| JDK | 1.8.0_212 | /opt/ | Java软件开发工具包 |
| Hadoop | 3.1.3 | /opt/ | 分布式系统基础架构 |
| 主机名 | Hadoop100 | Hadoop101 | Hadoop102 |
|---|---|---|---|
| IP地址 | 192.168.1.100 | 192.168.1.101 | 192.168.1.102 |
| HDFS:DataNode | 1 | 1 | 1 |
| HDFS:NameNode | 1 | ||
| HDFS:SecondaryNameNode | 1 | ||
| YARN:ResourceManager | 1 | ||
| YARN:NodeManager | 1 | 1 | 1 |
先安装一些命令,以后会用。
-y指:安装过程全选为"yes"
yum -y install net-tools vim rsync tree lrzsz
1、关闭防火墙
1.1、查看防火墙状态
systemctl status firewalld
1.2、关闭防火墙自启、关闭防火墙(每台机都执行)
systemctl disable firewalld
systemctl stop firewalld
2、网络配置
2.1、编辑文件(另外两台为:
192.168.1.101、192.168.1.102)
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 静态(此项为修改,其余为添加!!)
BOOTPROTO="static"
# 网关
GATEWAY=192.168.1.2
# 域名解析器
DNS1=192.168.1.2
# IP地址
IPADDR=192.168.1.100
2.2、重启网络服务 并 检测网络(安装
ifconfig命令:yum install net-tools)
service network restart
ifconfig
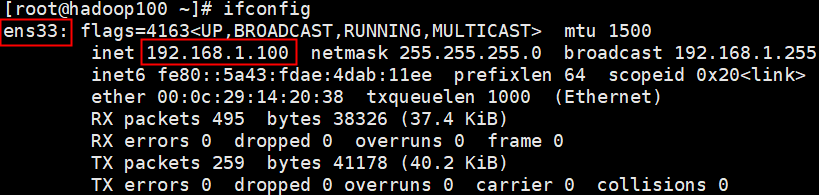
3、主机名
3.1、修改主机名(另外两台为:
hadoop101、hadoop102)
echo "hadoop100" > /etc/hostname
3.2、重启
reboot
3.3、查看主机名
hostname
3.4、修改集群网络映射
vi /etc/hosts
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
3.5、检验上一步
ping hadoop101
ping hadoop102
4、集群间免密登录
4.1、使用
ssh-keygen生成公钥和私钥(默认rsa),一路回车
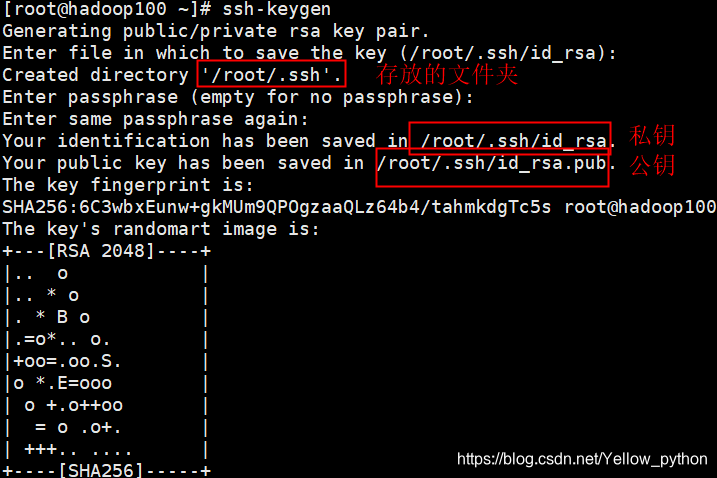
ssh-keygen -t rsa
4.2、生成
authorized_keys
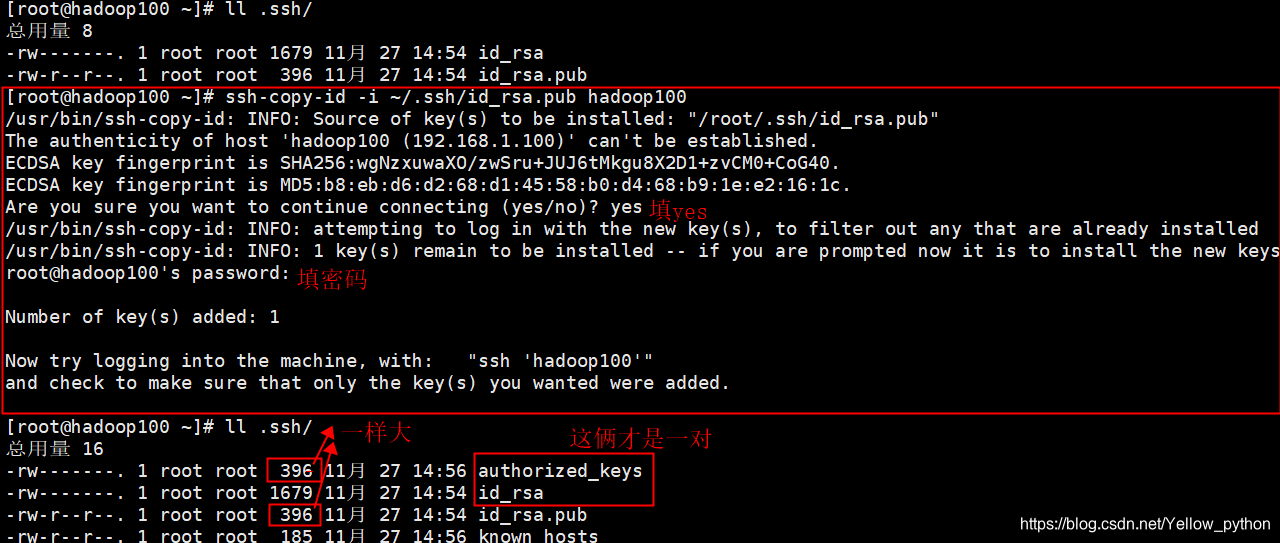
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop100
4.3、将整个文件夹发送到另外两台机,注意路径
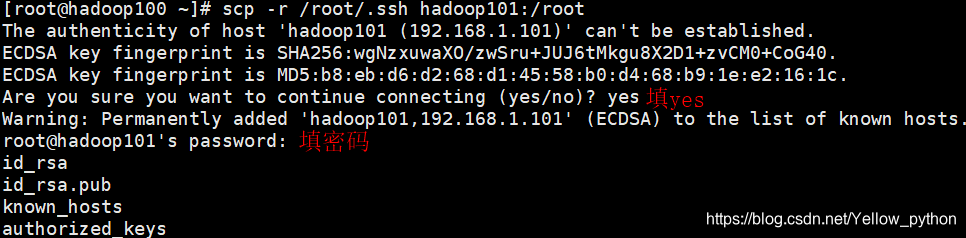
scp -r ~/.ssh hadoop101:~
scp -r ~/.ssh hadoop102:~
4.4、在每台检验相互之间的免密登录
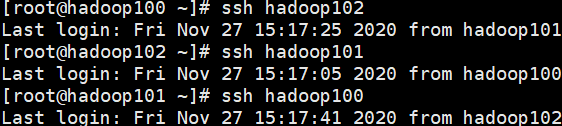
ssh hadoop101
ssh 192.168.1.102
4.5、集群时间同步 和 集群日志(暂缺)
5、安装JDK和Hadoop
下载地址:https://download.youkuaiyun.com/download/Yellow_python/13782506
用Xshell上传到服务器(可用rz -b命令)
集群免密登录配置好了,因此后述命令全在hadoop100上执行,不用切来切去
5.0、卸载原有JDK
查看原JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
卸载原JDK
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
5.1、解压、修改用户主
5.1.1、新建文件夹、解压
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/
ll /opt/
5.1.2、修改用户主
chown -R root:root /opt/jdk1.8.0_212
chown -R root:root /opt/hadoop-3.1.3
ll /opt/
5.2、环境变量
5.2.1、在
/etc/profile.d下创建文件
vim /etc/profile.d/custom.sh
# Java
export JAVA_HOME=/opt/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# Hadoop
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.2.2、
source后,检查是否成功
source /etc/profile.d/custom.sh
echo $PATH
java -version
hadoop version
5.3、配置文件
5.3.1、etc
进入配置文件夹
cd $HADOOP_HOME/etc/hadoop
Hadoop核心配置,只改configuration
vim core-site.xml
<configuration>
<!-- NameNode服务地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!--
其他临时目录的基础(Hadoop数据总目录)。
比如
【hdfs-site】的【dfs.namenode.name.dir】的
默认值【file://${hadoop.tmp.dir}/dfs/name】就有引用
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data</value>
</property>
</configuration>
HDFS配置,只改configuration
vim hdfs-site.xml
<configuration>
<!-- NameNode数据存放的目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<!-- DataNode数据存放的目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<!-- SecondaryNameNode数据存放的目录 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<!-- SecondaryNameNode服务地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop101:9868</value>
</property>
</configuration>
YARN配置,只改configuration
vim yarn-site.xml
<configuration>
<!-- 配置成 mapreduce_shuffle 才可运行 MapReduce -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!--
https://yellow520.blog.youkuaiyun.com/article/details/115724120
-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
MapReduce配置,只改configuration
vim mapred-site.xml
<configuration>
<!-- 让 MapReduce 运行在 YARN 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
从机配置,
-e指(enable interpretation of backslash escapes)启用反斜杠转义的解释
echo -e "hadoop100\nhadoop101\nhadoop102" > workers
cat workers
5.3.2、sbin
曾遇报错
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
大概是说
没定义HDFS_NAMENODE_USER等
对此可在启动脚本的文件头部(
#!/usr/bin/env bash下面)添加参数
cd $HADOOP_HOME/sbin/
在
start-dfs.sh、stop-dfs.sh文件头部添加参数
vi start-dfs.sh
vi stop-dfs.sh
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在
start-yarn.sh、stop-yarn.sh文件头部添加参数
vi start-yarn.sh
vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
6、文件分发
6.1、软件分发
scp -r /opt/ hadoop101:/opt/
scp -r /opt/ hadoop102:/opt/
6.2、环境变量分发,并且
source
scp -r /etc/profile.d/custom.sh hadoop101:/etc/profile.d/
scp -r /etc/profile.d/custom.sh hadoop102:/etc/profile.d/
source /etc/profile.d/custom.sh
ssh hadoop101 "source /etc/profile.d/custom.sh"
ssh hadoop102 "source /etc/profile.d/custom.sh"
7、集群启动
7.1、要格式化NameNode(在hadoop100),只格1次
hdfs namenode -format
7.2、启动集群:在hadoop100启动
start-dfs.sh,在hadoop102启动start-start.yarn
start-dfs.sh
ssh hadoop102 "start-yarn.sh"
7.3、停止集群
stop-dfs.sh
ssh hadoop102 "stop-yarn.sh"
8、查看
8.1、查看集群:各台机输入
jps(Java Virtual Machine Process Status Tool)
grep是文本查找,-v是invert-match反选
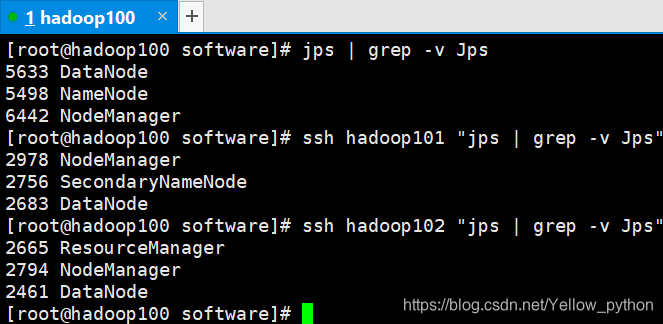
jps | grep -v Jps
ssh hadoop101 "jps | grep -v Jps"
ssh hadoop102 "jps | grep -v Jps"
8.2、查看网络端口(9870、8088)
NameNode网络端口http://hadoop100:9870
ResourceManager网络端口http://hadoop102:8088

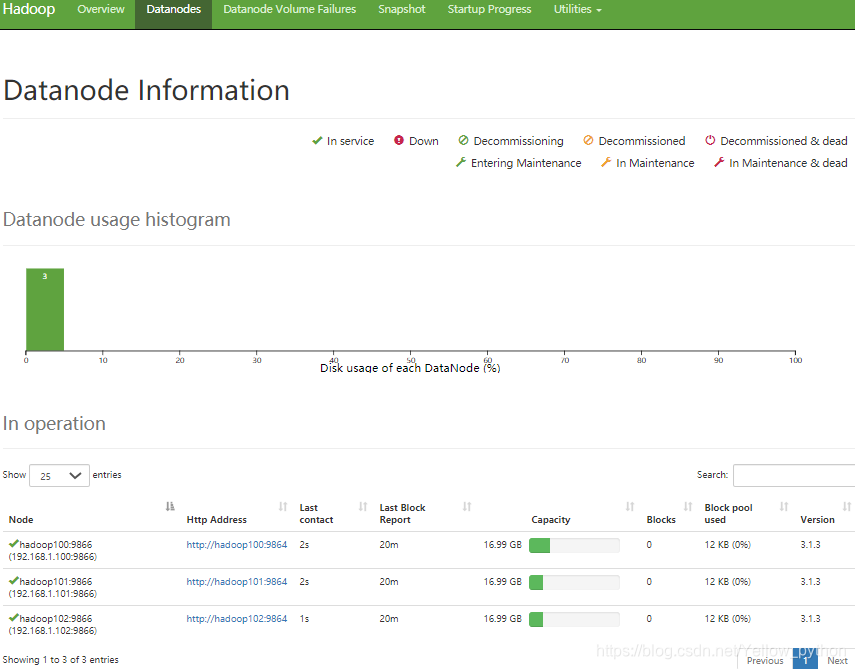
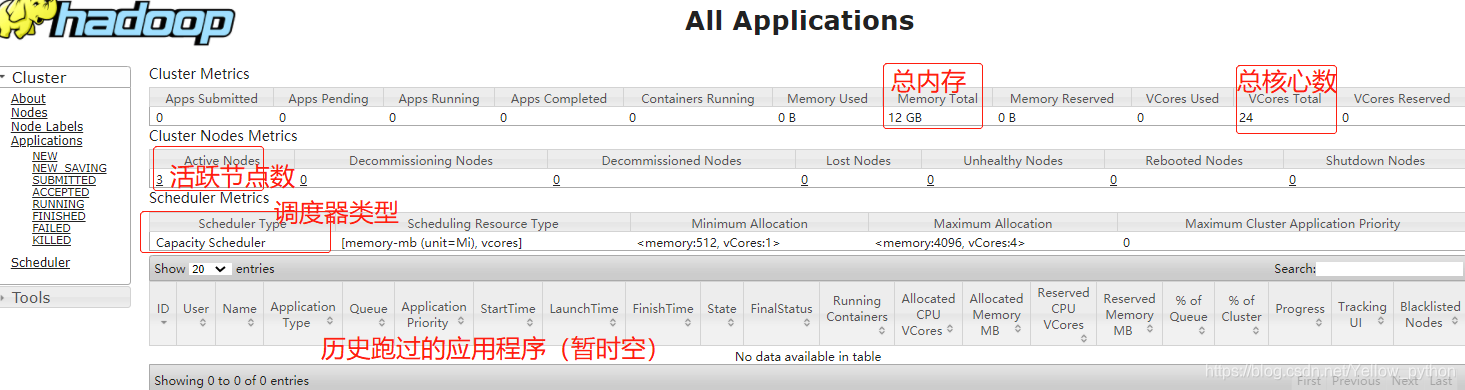
9、Hadoop基本命令
9.1、查看命令帮助
| 命令 | 说明 | 示例 |
|---|---|---|
hadoop | 查看 Hadoop总体命令 怎么用 | hadoop |
hadoop fs | 查看 文件系统相关命令 怎么用 | hadoop fs |
| help | 查看指定命令帮助 | hadoop fs -help df |
9.2、常用命令
| 常用功能 | 命令 | 示例 |
|---|---|---|
| 查看目录 | ls | hadoop fs -ls / |
| 上传文件 | put | hadoop fs -put a.txt /a.txt |
| 下载文件 | get | hadoop fs -get /a.txt a.txt |
| 查看文件 | cat | hadoop fs -cat /a.txt |
| 新建文件夹 | mkdir | hadoop fs -mkdir /aaa |
| 查看指定目录硬盘占用 | du | hadoop fs -du /aaa |
| 复制 | cp | hadoop fs -cp /aaa /bbb |
| 移动 | mv | |
| 文件权限 | chmod、chown | |
| 删除 | rm | hadoop fs -rm -r /aaa |
9.3、本地文件 上传到 HDFS
9.3.1、本地创建一个文件a.txt
9.3.2、上传(put或moveFromLocal)本地文件到HDFS
9.3.3、用命令或浏览器查看结果
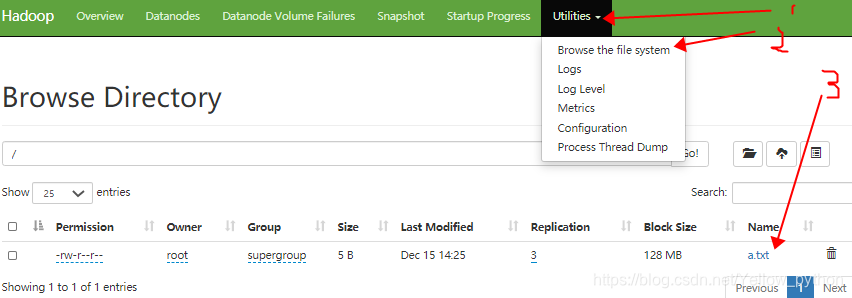
echo abcd > a.txt
hadoop fs -put a.txt /a.txt
hadoop fs -ls /
hadoop fs -cat /a.txt
9.4、HDFS 下载到 本地
hadoop fs -get /a.txt ba.txt
cat ba.txt


















 3254
3254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











