




 本文深入探讨了CTC、RNA、RNN-T和NeuralTransducer等语音识别模型的工作原理及优缺点。CTC用于在线实时语音识别,RNA解决CTC独立解码问题,RNN-T能输出多个token,NeuralTransducer引入注意力机制提高效率。
本文深入探讨了CTC、RNA、RNN-T和NeuralTransducer等语音识别模型的工作原理及优缺点。CTC用于在线实时语音识别,RNA解决CTC独立解码问题,RNN-T能输出多个token,NeuralTransducer引入注意力机制提高效率。
Connectionist Temporal Classification (CTC)
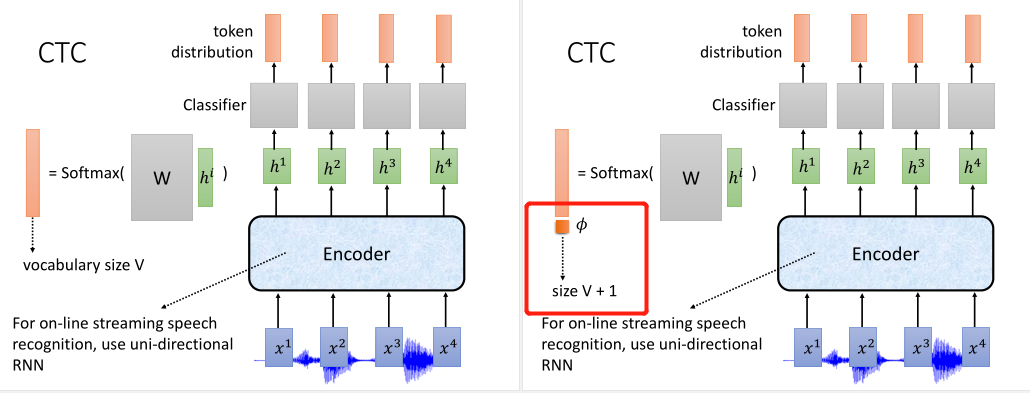
CTC可以用于线上实时地语音识别,编码器用的是单向的RNN,解码是用MLP来预测文字分布。
编码器将语音输入\(x^i\)编码成\(h^i\),MLP再对它乘上一个权重,接上Softmax,得到词表V大小的概率分布。
但有时候当前的语音输入可能并不能对应实际的文本token,所以预测要额外多一个为空的类别,表示模型不知道要输出什么。
CTC中没有使用下采样,所以输入和输出的序列长度都是T。
模型预测完后要进行后处理,一是把重复的token合并,二是把空类别去掉,得到最终的预测序列。
CTC的这种预测方式,会让它的数据标注变得很难,因为要确保刚好每个输入声音特征都对应一个正确的token。而标注语料的不足,会直接影响模型评测的表现。
此外,一个序列正确的标注方式又可以存着很多种,造成标注多标准问题。这也加大标注数据选择的困难。
由此采用的方法是穷举所有的可能的标注去训练。在数据集充足的情况下,CTC的效果还是不错的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 572
572




 到【灌水乐园】发言
到【灌水乐园】发言







