



 本文介绍了如何使用moltemplate工具高效地生成LAMMPS所需的数据和in文件。通过结合基本绘图、数据转换、packmol的空间排布以及moltemplate的系统操作,可以方便地构建和操纵不同格式的数据文件。文章详细讲解了moltemplate的文件结构、语法特性和使用技巧,并提供了forcefield.lt、unit.lt和system.lt等关键文件的示例。
本文介绍了如何使用moltemplate工具高效地生成LAMMPS所需的数据和in文件。通过结合基本绘图、数据转换、packmol的空间排布以及moltemplate的系统操作,可以方便地构建和操纵不同格式的数据文件。文章详细讲解了moltemplate的文件结构、语法特性和使用技巧,并提供了forcefield.lt、unit.lt和system.lt等关键文件的示例。
一 介绍长久以来,lammps的数据文件构建就是一个大问题(对我来说)。一方面,LAMMPS的数据格式比较特殊,很多软件不能直接导出; 另一方面小分子到大分子的变换,大分子在系统中的排布和大分子中的拓扑结构都需要牵扯很多的精力。经过长时间的试错,我算是终于找到一个比较合理且简约的技术栈,可以直接生成lammps所需的in文件和data文件。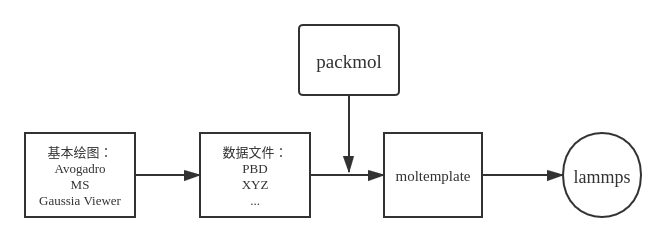
如图所示,整个技术栈分为:基本绘图:绘制基本的单元,如高分子结构单元,单个水分子或者甲烷分子等; 数据文件:导出成常见格式的数据文件,如PDB,XYZ; [空间排布]:packmol可以自动地根据所设置的限制向系统中填放单元。比如想向C60笼中填放原子,只需要一行命令将允许范围限制在球内即可; 生成工具:moltemplate可以操作已有的数据文件,在系统中复制,变换和随机,同时根据已有的拓扑结构补充生成键角二面角等信息,最后生成lammps所需的in文件和data文件。由此,得到的所有文件都可以直接使用lammps运行。此套技术栈的好处是,可以接受各种格式的数据文件并且可以轻松地操纵它们,而且都是开源的,安装方便快捷占地小。开发moltemplate的人同样也是lammps的主程,在手册中他成这款软件是lammps的前端(front-end)唯一的缺点是,moltemplate(包括packmol)手册有如16年以前的lammps手册,比较 ……随意洒脱。
二 文件结构moltemplate本身具有导入(import)和继承(inherit)功能,因此我们可以尽量地把文件区分按照功能区分开。当然文件名都是可以自定义的,这里只是介绍一个思路,告诉各位应该怎样上手。第一部分是forcefield.lt 这个文件中储存着lammps的系统和力场参数。# – ForceField – #
ForceField{
write_once("In Init"){
units lj
boundary p p p
atom_style full
pair_style lj/cut 10.5
bond_style hybrid fene harmonic
angle_style harmonic
}
write_once("Data Boundary") {
0 100.0 xlo xhi
0 100.0 ylo yhi
0 100.0 zlo zhi
}
write_once("Data Masses"){
@atom:M 1
@atom:G 1
@atom:R 1
}
write_once("In Settings"){
pair_coeff @atom:M @atom:M 1 1 2.5
pair_coeff @atom:M @atom:G 1 1 2.5
pair_coeff @atom:M @atom:R 1 1 2.5
pair_coeff @atom:G @atom:G 1 1 2.5
pair_coeff @atom:G @atom:R 1 1 2.5
pair_coeff @atom:R @atom:R 1 1 2.5
}
write_once("In Settings"){
bond_coeff @bond:MM fene 30 1.5
bond_coeff @bond:GR fene 30 1.5
bond_coeff @bond:RR harmonic 1000 0.66
}
write_once("In Settings"){
angle_coeff @angle:RRR 200 180
}
# write_once("Data Dihedrals By Type"){
# @dihedral: @atom:
# }
# write_once("Data Angles By Type"){
# @angle: @atom:
# }
}
第二部分是基本单元数据 这里面存储这一个片段的信息# – file matrix.lt –
import “forcefield.lt”
Matrix inherits ForceField{
write("Data Atoms"){
$atom:1 $mol:. @atom:M 0 1 1 1
$atom:2 $mol:. @atom:M 0 2 1 1
$atom:3 $mol:. @atom:M 0 3 1 1
$atom:4 $mol:. @atom:M 0 4 1 1
$atom:5 $mol:. @atom:M 0 5 1 1
}
write("Data Bonds"){
$bond:1 @bond:MM $atom:1 $atom:2
$bond:2 @bond:MM $atom:2 $atom:3
$bond:3 @bond:MM $atom:3 $atom:4
$bond:4 @bond:MM $atom:4 $atom:5
}
第三部分是操作部分 在这个文件中我们可以对基本单元进行操作,同时也是程序执行的入口# – file system.lt – #
import “forcefield.lt”
import “matrix.lt”
m1 = new Matrix [3].move(0,0,3)
在最简单的情况下,我们仅需要这三个文件就可以描述一个系统的初始化状态,然后执行命令行使用moltemplate生成实际文件:
moltemplate.sh system.lt
得到:
system.data
system.in
system.in.init
system.in.settings
如果出了bug还会出现生成树output_ttree
三 语法教程1 forcefield.lt# – example of a forcefield.lt inscript – #
ForceField{
write_once("In Init"){
units lj
boundary p p p
atom_style full
pair_style lj/cut 10.5
bond_style hybrid fene harmonic
angle_style harmonic
}
# write_once("Data Angles By Type"){
# @angle: @atom:
# }
}1.1 write_once() 和 write()
write_once(“file_name”){
text_content
}
每出现一次write_once(),就会新生成一个文件,整个程序执行过程中此命令仅仅执行一次。注意,In 和 Data 开头是系统保留关键词,将会被合并到in文件和data文件中,而特别离谱的才会被单独创立。比如,In Init就是个保留文件名,如果你输入In init就会被强制要求改成大写。接下来会有专门的专题来介绍保留文件名的特殊之处。还有一些文件名会被合并,比如Data Mass、Data boundary。花括号内的文本将会被转移到文件内,同时计数器都会被替换。write则是可以在一个文本块内出现多次,可以被重复执行的单元(通过new)
1.2 import 和 inheritsimport
关键字要求系统去查找需要引用的文件的位置inherits 表示本结构单元中的变量名称(比如bond type名MM来自于继承的单元)
1.3 forcefield 和 By Type
write_once(“Data Angles By Type”){
@angle: type @atom:atom1 @atom:atom2 @atom:atom3 @bond:b1 @bond:b2
}
这里介绍moltemplate最终要的功能之一。众所周知我们的逻辑结构不单单包括2-body的键接,还有3-body,4-body的angle和dihedral甚至还有improper。如果自己写程序去搜索拓扑结构的话会非常费事。因此这里给出了一个功能,只要你给出了结构的键接信息,那么就可以自动去查找所有的angle和dihedral和improper。其中语法也十分清晰明了,第一,指明这个angle的三个原子类型,第二,指明两个键接类型,仅此就可以遍历所有原子,标记出所有的角。
2 unit.lt# – example of a unit.lt inscript – #
import “forcefield.lt”
Matrix inherits ForceField{
write("Data Atoms"){
# atom id mol id type charge coordinate
$atom:1 $mol:. @atom:M 0 1 1 1
$atom:2 $mol:. @atom:M 0 2 1 1
$atom:3 $mol:. @atom:M 0 3 1 1
$atom:4 $mol:. @atom:M 0 4 1 1
$atom:5 $mol:. @atom:M 0 5 1 1
}
write("Data Bonds"){
$bond:1 @bond:MM $atom:1 $atom:2
$bond:2 @bond:MM $atom:2 $atom:3
$bond:3 @bond:MM $atom:3 $atom:4
$bond:4 @bond:MM $atom:4 $atom:5
}
}2.2 和@计数器如上面的和@计数器如上面的和@计数器如上面的atom:1和@atom:1,都被成为变量。前面的符号是计数器,后面叫做类名(category),冒号后则是变量名,我们很快就会知道这个为什么要这么写。计数器分为两种,$是动态计数器,每增加一个,在生成的时候都会赋给一个唯一的id,@是静态计数器,每一个类名在全局只会唯一给一个type。简单说,就是静态计数器和系统复杂度有关,动态计数器和系统规模有关。2.3 变量作用域上面提到的变量有两种形式,一种是全名,另一种是简名。简名通常是在一个结构对象(molecule-object)内,不会产生歧义。而全名就厉害了:@cpath/catname:lpath
cpath:category的作用域,通常省略以表示全局。除了有极为特殊的要求之外不需要管
catname:类名
lpath:包括变量名和可选的指明那个分子的index
这样可以从一个结构对象内引用其他结构对象中的原子或者结构片段。但为了清晰起见,按照编程的基本原则,请不要交叉引用。2.4 $mol:. 和 mol:...你所看到的点,斜线的用法和unix操作系统文件路径表示方法一样,既可以用来表示相对路径,又可以表示绝对路径。所谓路径就是指的是不同的结构对象之间的关系(molecule−object)。类似的,一个点意为“这个”,就是代指本结构,如果一个结构单元中所有的原子都是mol:...你所看到的点,斜线的用法和unix操作系统文件路径表示方法一样,既可以用来表示相对路径,又可以表示绝对路径。所谓路径就是指的是不同的结构对象之间的关系(molecule-object)。类似的,一个点意为“这个”,就是代指本结构,如果一个结构单元中所有的原子都是mol:...你所看到的点,斜线的用法和unix操作系统文件路径表示方法一样,既可以用来表示相对路径,又可以表示绝对路径。所谓路径就是指的是不同的结构对象之间的关系(molecule−object)。类似的,一个点意为“这个”,就是代指本结构,如果一个结构单元中所有的原子都是mol:.,那每new一次,同一个结构片段内mol id相同,不同结构片段mol id递增而三个点则是告诉系统,我这个片段从属于一个大分子,那么这个片段在大分子的结构片段内不管new几次,new一次大分子得到的所有原子从属于一个mol id,不同大分子的mol id才不同。3 system.lt这一部分就是对之前已构建的所有单元片段的操纵了,不论是旋转,平移还是随机都是一行搞定。这些命令都在手册的一开头。关于Debug每次文件生成结束,都会给出一个名为output_ttree的文件夹,里面有各种文件。其中最终要的是就是ttree_assignments,这里面储存了计数器被替换的数和该计数器第一次出现的位置。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









