







 本文详细介绍了Mysql的InnoDB存储引擎在Repeatable Read事务隔离级别下的可重复读特性和幻读问题。通过MVCC机制解释了如何在可重复读下避免幻读,同时探讨了next-key锁在当前读操作中的作用,以及在不同索引情况下锁的实现差异。
本文详细介绍了Mysql的InnoDB存储引擎在Repeatable Read事务隔离级别下的可重复读特性和幻读问题。通过MVCC机制解释了如何在可重复读下避免幻读,同时探讨了next-key锁在当前读操作中的作用,以及在不同索引情况下锁的实现差异。
一、事务的特性ACID
A原子性:事务包含的操作要么全部成功,要么全部失败回滚
C一致性:事务必须使数据库从一个一致的状态变到另外一个一致的状态(满足完整性约束)
I隔离性:多个事务之间不互相干扰
D持久性:一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的
二、事务之间的隔离
2.1、若无隔离
脏读:一个事务处理过程中读取了另一个事务中未提交的数据
不可重复读:事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据进行了修改并提交,导致事务A多次读取同一数据时,结果不一致
幻读:事务A处理全表的数据时,事务B插入一条新的数据,新加入的数据未被处理,事务A就像发生了幻觉一样
不可重复读和幻读,不可重复读针对的是数据项的修改,幻读针对的是数据库的新增or删除
2.2、事务隔离级别
读未提交 --> 脏读,不可重复读,幻读
读已提交 --> 不可重复读,幻读
可重复读 --> 幻读
串行化 -->
三、Mysql的默认级别Repeatable Read
3.1、可重复读定义
事务A中,执行同一条查询语句,得到的结果是一致的。
start transaction;
select * from user; //(1)
insert into user values(?, ?) //(2)
select * from user; //(3)
commit
事务A前后总共执行了两次SELECT语句,这两次SELECT得到的结果是一致的(事务A自己执行的insert语句,是在(3)结果中的)
3.2、破坏可重复读的情况
事务A:
start transaction;
SELECT * FROM user; //(1)
INSERT INTO user VALUES(u1); //(2)
SELECT * FROM user; //(3)
commit
事务B:
start transaction;
INSERT INTO user VALUES(u2); //(1)
commit
事务A在执行完(1)后,事务B执行了(1)且完成提交,这种情况下事务A在执行(3)的时候,应得到的是u1,这个时候是符合可重复读的性质的;如果得到的是u1、u3,这个时候就不是可重复读的;
3.3、Mysql的InnoDB如何实现可重复读?以及该级别下如何解决幻读的问题
3.3.1、基于MVCC解决幻读:使用情况快照读
SELECT * FROM user;
每一个事务,都有一个系统分配的事务id,该id是自动递增的。
Mysql给每一条记录,添加了隐藏的两列,创建时间戳,删除时间戳,记录了一条记录由哪一个事务创建,哪一个事务删除。
事务A在执行SELECT语句的时候,create <= 事务A_ID && (delete == undefine || delete > 事务A_ID):create <= 事务A_ID,保证事务A读取到的数据,是在A开始之前,或者由A创建的,同时(delete == undefine || delete > 事务A_ID),保证在A开始之前,记录未被删除(1、记录未被删除,2、记录删除于事务A之后)。
| -----------user表---------- |
| name | create | delete |
| u1 | 1 | undefine |
| u2 | 2 | undefine |
| u3 | 3 | undefine |
| u5 | 5 | 6 |
1、事务A执行
事务A,数据库分配的版本号为10
start transaction;
SELECT * FROM user; //(1)
INSERT INTO user VALUES('u10'); //(2)
INSERT INTO user VALUES('u101'); //(3)
DELETE FROM user WHERE name = '101' //(4)
SELECT * FROM user; //(5)
commit;
| -----------user表---------- |
| name | create | delete |
| u1 | 1 | undefine |
| u2 | 2 | undefine |
| u3 | 3 | undefine |
| u5 | 5 | 6 |
| u10 | 10 | undefine |
| u101 | 10 | 10 |
事务A的(5)判断条件:create <= 10 && (delete == undefine || delete > 10)
u1:1 <= 10 && (undefine == undefine) --> true
u5:5 <= 10 && (6 > 10) --> false
u10:10 <= 10 && (undefine == undefine) --> true
u101:10 <= 10 && (10 > 10) --> false
事务A的(5)结果:u1、u2、u3、u10
2、事务A过程中,事务B执行INSERT
start transaction;
SELECT * FROM user; //(1)
SELECT * FROM user; //(2)
commit;
事务B,数据库分配的版本号为11
start transaction;
INSERT INTO user VALUES('u11'); //(1)
commit
| -----------user表---------- |
| name | create | delete |
| u1 | 1 | undefine |
| u2 | 2 | undefine |
| u3 | 3 | undefine |
| u5 | 5 | 6 |
| u11 | 11 | undefine |
事务A的(2)判断条件:create <= 10 && (delete == undefine || delete > 10)
u11:11 <= 10 --> false
事务A的(2)结果:u1、u2、u3
3、事务A过程中,事务C执行DELETE
start transaction;
SELECT * FROM user; //(1)
SELECT * FROM user; //(2)
commit;
事务C,数据库分配的版本号为12
start transaction;
DELECT FROM user WHERE name = 'u2'; //(1)
commit
| -----------user表---------- |
| name | create | delete |
| u1 | 1 | undefine |
| u2 | 2 | 12 |
| u3 | 3 | undefine |
| u5 | 5 | 6 |
事务A的(2)判断条件:create <= 10 && (delete == undefine || delete > 10)
u2:2 <= 10 && (12 > 10) --> true(因为在开始A事务的时候,u2还未被删除,故应该出现在结果中)
事务A的(2)结果:u1、u2、u3
4、事务A过程中,事务D执行UPDATE
start transaction;
SELECT * FROM user; //(1)
SELECT * FROM user; //(2)
commit;
事务D,数据库分配的版本号为13
start transaction;
UPDATE user SET name = 'u11' WHERE name = 'u1'; //(1),update操作实际上是通过删除原数据,添加新数据完成的
commit
| -----------user表---------- |
| name | create | delete |
| u1 | 1 | 13 |
| u2 | 2 | undefine |
| u3 | 3 | undefine |
| u5 | 5 | 6 |
| u11 | 13 | undefine |
事务A的(5)判断条件:create <= 10 && (delete == undefine || delete > 10)
u1:1 <= 10 && (13 > 10) --> true
u11:13 <= 10 --> false
事务A的(2)结果:u1、u2、u3(因为在事务A开始的时候,u1还未被更改为u11,故事务A应当查询出u1,而非u11)
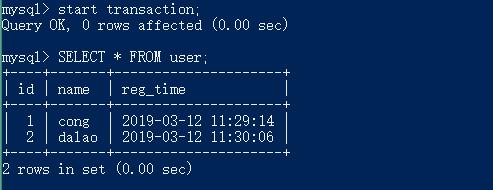
5、基于MVCC的可重复读 & 幻读验证
start transaction;
SELECT * FROM user; //(1)
SELECT * FROM user; //(2)
commit;
事务A快照读:
事务B执行INSERT:
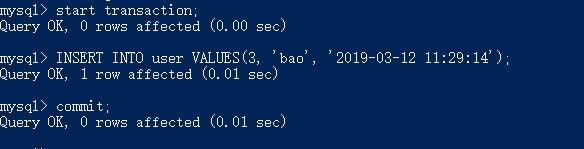
事务A快照读 --> 事务A执行INSERT --> 事务A执行快照读 --> 事务A执行当前读
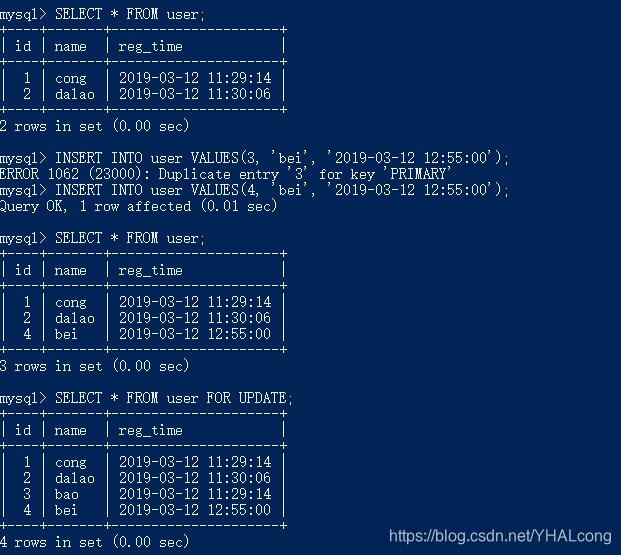
1)第一次快照读:在事务B提交之后,B中INSERT的数据不显示在事务A的快照读中
2)事务A执行INSERT语句,因为在事务B中已经INSER了主键为3的记录,故不能再次INSERT主键为3的记录失败,说明INSERT执行的是当前读
3)事务A执行INSERT语句,数据的主键为4,顺利插入
4)事务A执行快照读,事务A中INSERT的主键为4的记录读取ok,事务B中的INSERT的主键为3的记录读取不到
5)事务A执行当前读,事务B中插入的主键为3的记录读取ok
3.3.2、基于next-key解决幻读:使用情况当前读
SELECT * FROM user WHERE ? LOCK IN SHARE MODE;
SELECT * FROM user WHERE ? FOR UPDATE;
INSERT INTO user VALUES(?);
UPDATE user SET ? WHERE ?;
DELETE FROM user WHERE ?;
1、事务A过程中,如何加锁?
start transaction;
SELECT * FROM user WHERE name = 'u10' FOR UPDATE; // (1)
commit
| --------user表:name加了索引--------- |
| id | name | create | delete |
| 1 | u1 | 1 | undefine |
| 2 | u3 | 3 | undefine |
| 3 | u10 | 10 | undefine |
| 5 | u11 | 11 | undefine |
事务A的(1)语句,使用name = 'u10’作为检索条件,故向左取得最靠近u10的值u5作为左区间,向右取得最靠近u10的值u11作为右区间,因此next-key锁范围(u3-u10间隙锁) + u10记录锁 + (u10 - u11间隙锁)
| --------user表:name未加索引--------- |
| id | name | create | delete |
| 1 | u1 | 1 | undefine |
| 2 | u3 | 3 | undefine |
| 3 | u10 | 10 | undefine |
| 5 | u11 | 11 | undefine |
事务A的(1)语句,使用name = 'u10’作为检索条件,然后name列未加索引,此时对整个表加锁
思考:为何为name建立索引的时候,加的是范围锁?而未建立索引时,需要锁住整张表?
| --------user表:name未加索引--------- |
| id | name | create | delete |
| 1 | u1 | 1 | undefine |
| 2 | u3 | 3 | undefine |
| 3 | u10 | 10 | undefine |
| 5 | u11 | 11 | undefine |
| 8 | u10 | 11 | undefine |
| 9 | u5 | 11 | undefine |
1)name建立索引的情况下:当需要插入一条u10的数据时,需要将新数据的索引列name的值u10,添加进索引的正确位置,结合下图,其正确的位置为(u5, u11)之间,只需要保证索引的(u5, u11)之间不能INSERT数据即可(有关索引的详细解析见下篇博客)
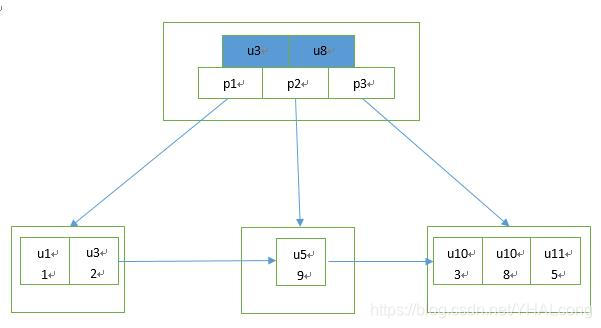
2)name未建索引的情况下:当需要插入一条u10的数据时,可放入数据表中的任意位置。如:开始位置、中间的任意位置,最后位置
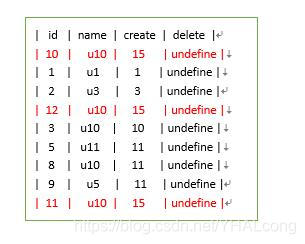
2、next-key锁验证
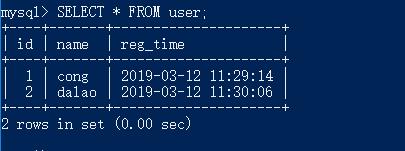
表结构:
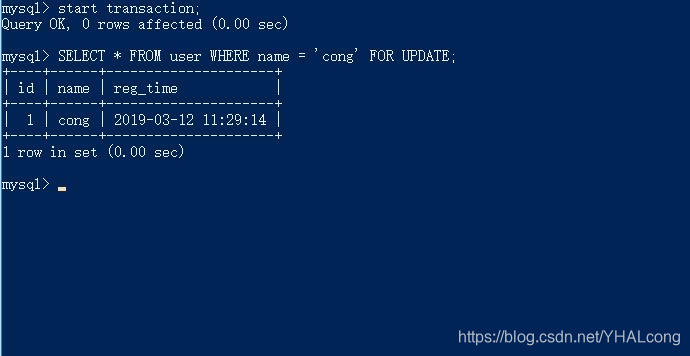
1)事务1执行当前读:
2)事务2执行INSERT语句,发现一直未返回成功,直至一段时间后失败
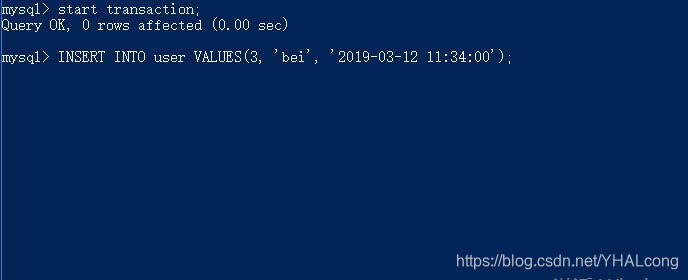
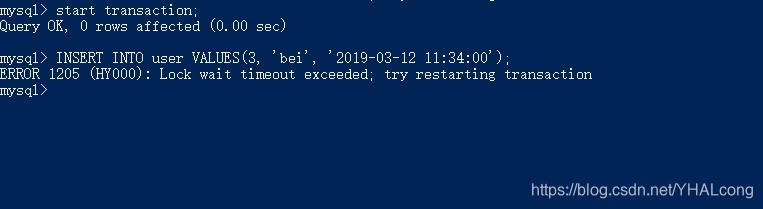
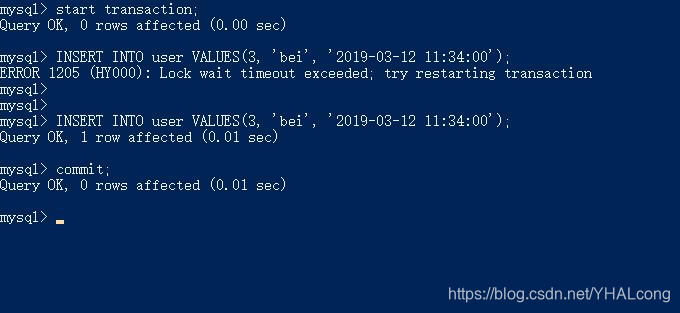
3)现在提交事务1,再次执行事务2,INSERT很快取得成功
如有不当之处,欢迎指正不胜感激

















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









