



点击上方“AI派”,选择“设为星标”
最新分享,第一时间送达!

![]()
作者:Tango,目前就职在一家对日开发的的IT服务公司。不是科班出身的我,出于对编程的热爱,自学了软件开发。从此深深陷入在代码的世界而无法自拔。
编辑:王老湿
我们的《从零开始学爬虫》专栏发布后,目前已经更新了两篇:
今天我们正式开始介绍一个爬虫示例,这篇文章主要包含以下内容:
Python第三方库的安装方法
学会使用Requests库的使用方法
BeautifulSoup库的使用方法
Requests库和BeautifulSoup库的组合使用
Python的第三方库
Python之所以如此火热和流行,有很大的原因是因为它有很多很强大的第三方库。这样“程序猿”们就不用太了解底层的实现,用最少的代码写出最多的功能。就像我们之前说的购买车票一样,需要:
打印车票的纸和墨
一台可以打印的机器
查询座位等操作。
如果没有使用第三方库的话,恐怕我们买一张车票要一步一步的把上面需要的东西都实现一遍。这样购买一张车票是不是要很久啊。如今有了自动售票机这个“第三方库”,我们只需几十秒就可以拿到车票。这种拿来即用的在Python中就是第三方库。
如何安装第三方库呢
纯原生的安装方法
python pip install 第三方库的名称在anaconda环境中安装
python conda install 第三方库的名称当然还可以通过源码安装
我们将源码下载到本地,解压后会看到一个文件夹目录,里面有一个setup.py的文件,然后我们在该文件的同级目录下,执行如下代码即可:
python setup.py install
以上这些方法都是在你的电脑上只有一个python环境的前提下。如果同时存在Python2 和python3的情况下,恐怕要小心一下了。看看你默认的环境是哪个。具体大家遇到问题可以在群里面@我一下。什么?! 还没加群,那快快扫描文章下面的二维码加入进来。会有很多福利的。
安装好后如何使用
其实使用Python的第三方库很简单,只需要在你的代码开头将它导入进来就可以了。
import time # 这个库是Python自带的。可以直接这样引入 from BS4 import BeautifulSoup # 从我们安装的第三方库中引入进来
Requests库
Requests库的作用就是请求网站获取网页数据的,让我们从简单的实例开始,讲解Requests的使用方法。
我们这里的示例网站是,爱站的ICP备案查询https://icp.aizhan.com。我们查询的网站是www.youkuaiyun.com
这里的目标url为:https://icp.aizhan.com/www.youkuaiyun.com/
我们新建一个main.py的文件。将如下代码写在里面。
我建议大家在一个固定的地方建一个文件夹,用来保存我们专栏的所有的代码,等专栏结束后看看你的成就,也许会很吃惊的哦。
import requests
# 这里想查的优快云的备案信息
res = requests.get('https://icp.aizhan.com/www.youkuaiyun.com/')
print(res)
print(res.text)
然后在控制台(cmd)中输入:
python main.py
得到如下画面,表示你已经成功的爬取了这个网站的代码信息,恭喜你,你已经成功的入了爬虫的坑。
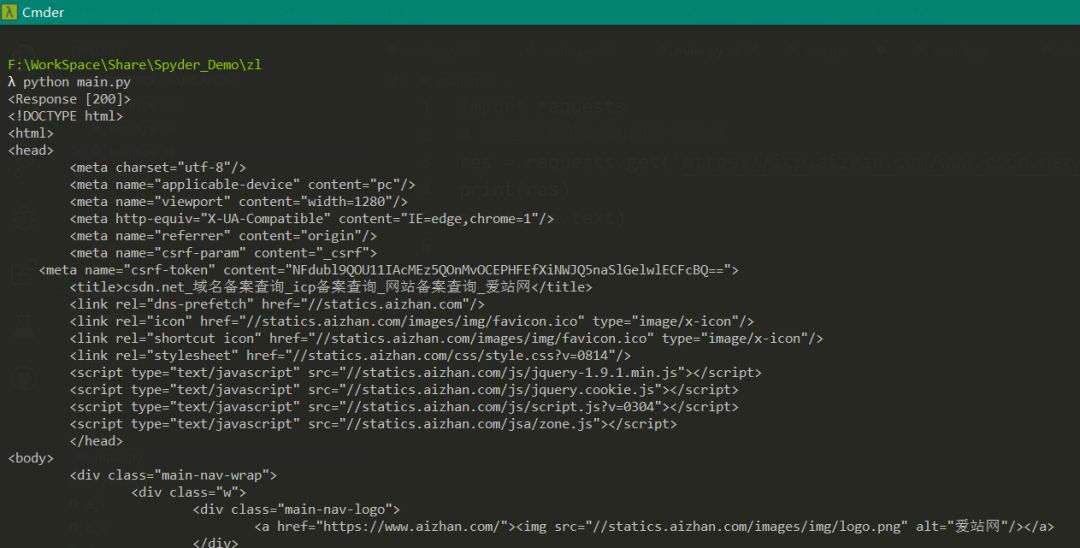
我们看到有一个,代表的意思请求网站成功,若为404,400则表示请求失败,具体的原因有很多。比如:网站地址输错,当然也有可能触发了反爬机制。
上面的一堆HTML代码就是我们爬取的内容,我们可以通过在浏览器中F12来比较一下我们获取的内容和目标网站的代码是否一致。
大部分时候,我们都要在爬虫中添加请求头,让服务器误以为我们是通过浏览器访问的,这样可以减少触发反爬机制的几率。
那么如何伪装成浏览器呢?我只需要在get方法里面添加一个headers的参数即可。
如何获取header的内容呢?
我们在浏览器中按F12打开开发者工具。刷新页面,然后找到User-Agent,这就是我们的请求头。
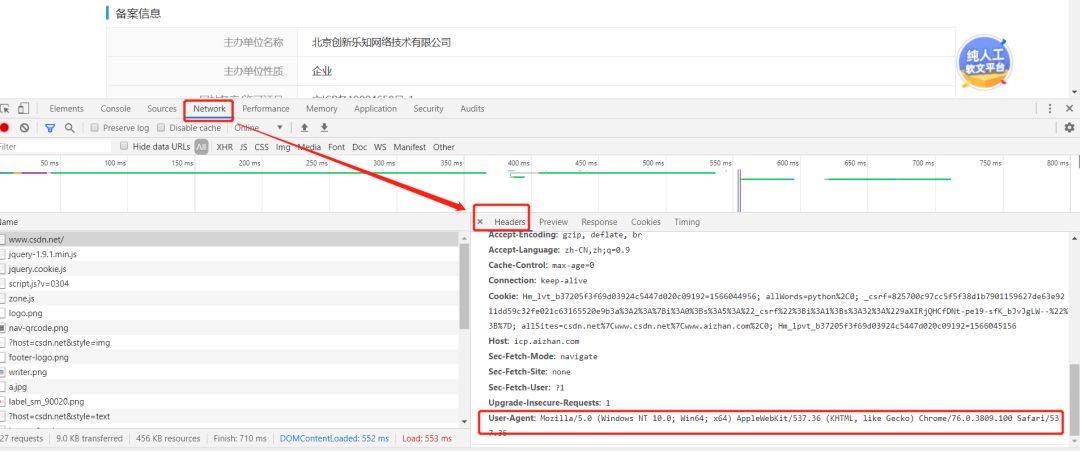
然后修改代码:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/76.0.3809.100 Safari/537.36'
}
# 这里想查的优快云的备案信息
res = requests.get('https://icp.aizhan.com/www.youkuaiyun.com/', headers = headers)
print(res)
print(res.text)
这里的headers是一个字典。这里的value会很长,我们可以在合适的地方添加一个\来让它换行。
Requests库不仅有get方法,还有post方法,通常是用来登录的,我们在后面的实战中会用到,这里暂时就不多说了。
我们用这个库来访问网站,有时会出现问题,常见的如下:
ConnectionError:通常是网络问题(如DNS查询失败,拒绝连接等)
HTTPError:原因为请求返回了一个不成功的状态码,比如404等。
Timeout异常:请求超时
TooManyRedirects异常,原因为超过了设定的最大重定向次数。
我们在实际代码的中通常是需要做异常处理的
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/76.0.3809.100 Safari/537.36'
}
# 这里想查的优快云的备案信息
res = requests.get('https://icp.aizhan.com/www.youkuaiyun.com/', headers = headers)
# 异常处理
try:
print(res.text)
except ConnectionError:
print("连接失败")
当出现连接失败的时候,就会在控制台打印一个信息告诉开发者连接失败了。
BeautifulSoup库
我们在上面通过requests库获取到了页面代码,但是如何能准确的提取出我们需要的信息呢?
我们在之前的代码中引入我们的BeautifulSoup库。
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/76.0.3809.100 Safari/537.36'
}
# 这里想查的优快云的备案信息
res = requests.get('https://icp.aizhan.com/www.youkuaiyun.com/', headers = headers)
# 异常处理
try:
# 对返回结果尽心解析
soup = BeautifulSoup(res.text, 'html.parser')
print(soup.prettify())
except ConnectionError:
print("连接失败")
同样通过在命令行中运行
python main.py
会得到页面代码,这时的代码和之前其实是一样的,只不过BS4(我们后面都将BeautifulSoup库简称为BS4)对它进行了标准的缩进格式化。
BS4除了支持Python标准库的HTML解析器外,还支持一些第三方的解析器。如下:
| 解析器 | 使用方法 | 有点 | 缺点 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(res.text, 'html.parser') | 内置库执行速度适中,文档容错能力强 | 旧版本(3.2.2)前的容错性差 |
| lxml HTML解析器 | BeautifulSoup(res.text, 'lxml') | 速度快,文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(res.text, 'lxml') 或者BeautifulSoup(res.text, ['lxml', 'xml']) | 速度快,唯一支持XML的解析器 | 同上 |
| html5lib | BeautifulSoup(res.text, 'html5lib') | 最好的容错性,以浏览器的方式解析文档生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
BS4官方推荐使用lxml作为解析器,因为效率高。
解析得到的Soup文档可以使用find(), find_all()以及selector()方法定位到需要的元素。
find和find_all的用法类似
soup.find_all('div', 'item')
soup.find_all('div', class = 'item')
soup.find_all('div', attrs = {'class':'item'})
以上这三行代码的功能是一样的,都是通过class来获取div元素。
find_all和find的返回类型不一样,前者返回所有符合条件的元素列表,而后知只返回一个元素。
soup.selector(#icp-table > table > tbody > tr:nth-child(1) > td:nth-child(2))
这个是通过标签的层级关系来获取指定的内容的。可以在谷歌浏览器中在指定元素上面右键,然后有一个copy里面可以选择selector就可以得到括号里面的内容了。
tr:nth-child(1) 需要修改的,在Python中需要改成tr:nth-of-type(1)
接下来演示一下如何获取到主办单位名称和备案号
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/76.0.3809.100 Safari/537.36'
}
# 这里想查的优快云的备案信息
res = requests.get('https://icp.aizhan.com/www.youkuaiyun.com/', headers = headers)
# 异常处理
try:
# 对返回结果尽心解析
soup = BeautifulSoup(res.text, 'html.parser')
# 通过find_all()获取主办单位名称
div = soup.find('div', attrs = {'id':'icp-table'})
td_list = div.find_all('td')
name_info = td_list[0].text + ":" + td_list[1].text
print(name_info)
# 通过selector获取备案号
icp_no = soup.select('#icp-table > table > tr:nth-of-type(3) > td:nth-of-type(2) > span')[0].get_text()
print(icp_no)
except ConnectionError:
print("连接失败")
运行后得到:
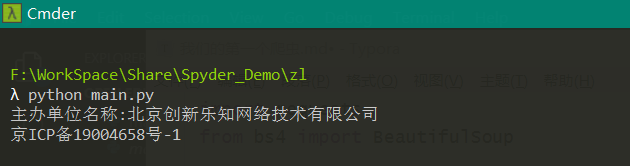
这里有几点需要注意一下
我们在使用selector的时候,用的方法是select()
我们在复制了selector内容后需要修改,不能直接使用
我们复制的内容:
icp-table > table > tbody > tr:nth-child(3) > td:nth-child(2) > span
实际写入代码的内容:
icp-table > table > tr:nth-of-type(3) > td:nth-of-type(2) > span
我们要获取的是文本,所以需要在获取对象后,在调用一些方法类获信息,如:get_text()等
好了,今天的内容就是这些。大家下去把其他的信息也取一下。
我们成立了这个爬虫专栏的读者交流群,如果有问题欢迎大家在群里积极讨论。还没有加入的同学可以扫描下方的微信二维码,添加微信好友,之后统一邀请你加入交流群。添加好友时一定要备注:爬虫。

/ 每日赠书专区 /
为了回馈一直以来支持我们的读者,“每日赠书专区”会每天从留言支持我们的读者中选择一名最脸熟的读者来赠予实体书籍(包邮),当前通过这种方式我们已赠送出 9 本书籍。
脸熟的评判标准是根据通过留言的次数来决定的
留言时需要按照今日留言主题来用心留言,否则不计入总数
每日赠书专区会出现在AI派当天发布文章的头条或次条。
如果不理解头条/次条的含义的读者可看下面的图。

今天我们的每日赠书专区出现在“头条”的位置上,书籍为《从零开始学Python网络爬虫》。

本书简介:
Python是数据分析的首要语言,而网络中的数据和信息很多,如何从中获取需要的数据和信息呢?最简单、直接的方法就是用爬虫技术来解决。
本书是一本教初学者学习如何爬取网络数据和信息的入门读物。书中不仅有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容非常实用,讲解时穿插了22个爬虫实战案例,可以大大提高读者的实际动手能力。
?↑↑点击上方链接即可购买
恭喜上期通过留言成功混脸熟的读者:popo,赠送一本《利用Python进行数据分析》
请该同学联系小编:wanglaoshi201907

/ 今日留言主题 /
你写爬虫时遇到最坑的事情是什么?
近期专栏推荐
1. 算法原理稳如狗,工程落地慌得很!AI炼丹炉实践指南来啦~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









