




 本文详细介绍了决策树的学习过程,包括如何选择特征分裂、何时停止分裂,以及纯度的衡量标准。讨论了信息增益在决策树构建中的作用,并讲解了一维和连续值特征的处理。此外,还涵盖了回归树、随机森林和XGBoost等增强决策树算法,以及何时选择使用决策树的场景。文章指出,决策树在结构化数据上的表现良好,且训练速度快,但不适合非结构化数据,而神经网络则更为通用。
本文详细介绍了决策树的学习过程,包括如何选择特征分裂、何时停止分裂,以及纯度的衡量标准。讨论了信息增益在决策树构建中的作用,并讲解了一维和连续值特征的处理。此外,还涵盖了回归树、随机森林和XGBoost等增强决策树算法,以及何时选择使用决策树的场景。文章指出,决策树在结构化数据上的表现良好,且训练速度快,但不适合非结构化数据,而神经网络则更为通用。
建立选择合适的决策树提高算法效果

1.学习过程(Learning Process )
关键决策:
1.How to choose what feature to split on at each node?(如何选择在每个节点上使用划分的特征)尽可能提高纯度
2.When do you stop splitting?(在什么时候停止划分)

- 限制决策树深度的一个原因可能是确保我们的树不会变得太大、太笨重,同时小巧的树不容易导致过拟合
- 另一个标准是如果优先级分数的提高,低于某个阈值,如果分裂个节点导致最小的纯度提升,实际上是提高了纯度,这也是让树小,降低过拟合的风险
- 如果一个节点的样本数低于某个阈值可能也会决定停止分裂
2.纯度(Measuring purity)
Entropy熵,熵越大越不纯洁

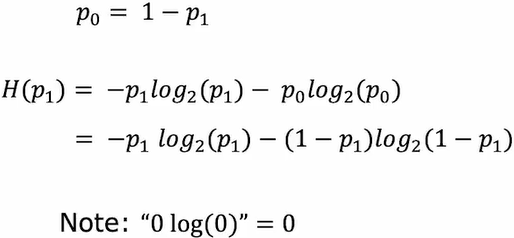
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









