



R绘图系列主要是带领大家绘制一些实用、好看而又不太复杂的科研常用图形,主打一个实用,该系列会持续更新,有需要的小伙伴赶紧关注起来吧。
预备知识
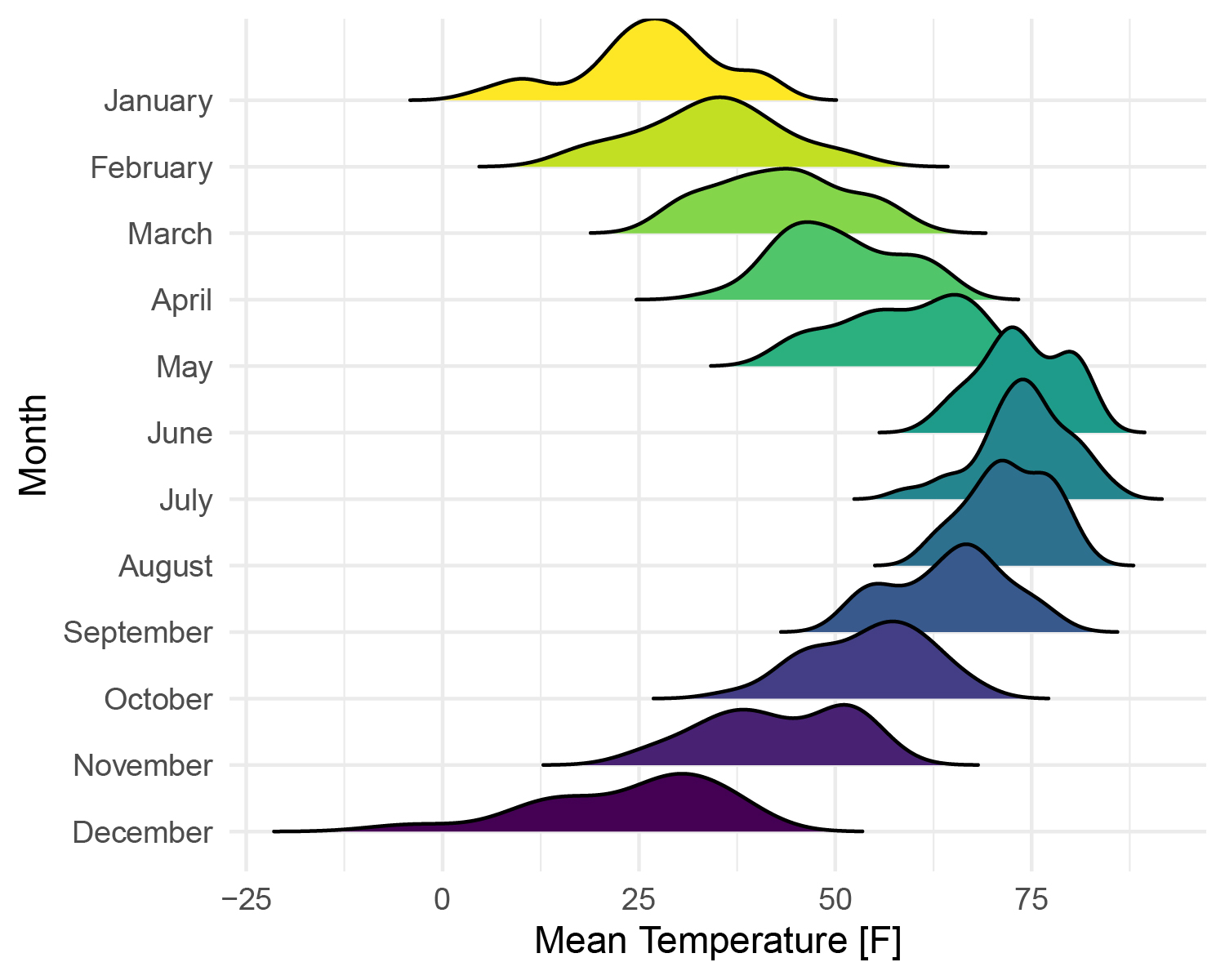
山脊图是部分重叠的线图,可产生山脉的印象。它们对于可视化分布随时间或空间的变化非常有用。
绘图
加载包和数据
# install.packages("ggridges")
# 加载包
library(ggplot2)
library(ggridges)
library(viridis)
library(tidyverse)
# 准备输入数据
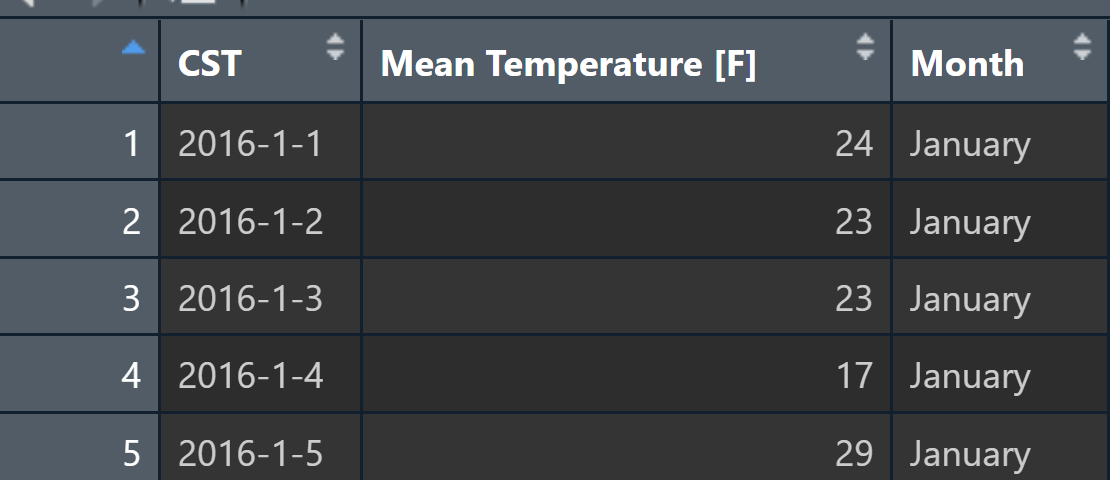
data(lincoln_weather)
pdata <- lincoln_weather[,c(1,3,24)]
colnames(pdata)
数据介绍
第二列是X年X月X天的平均气温值,第三列是月份。目标是展现每个月份的气温分布密度曲线。
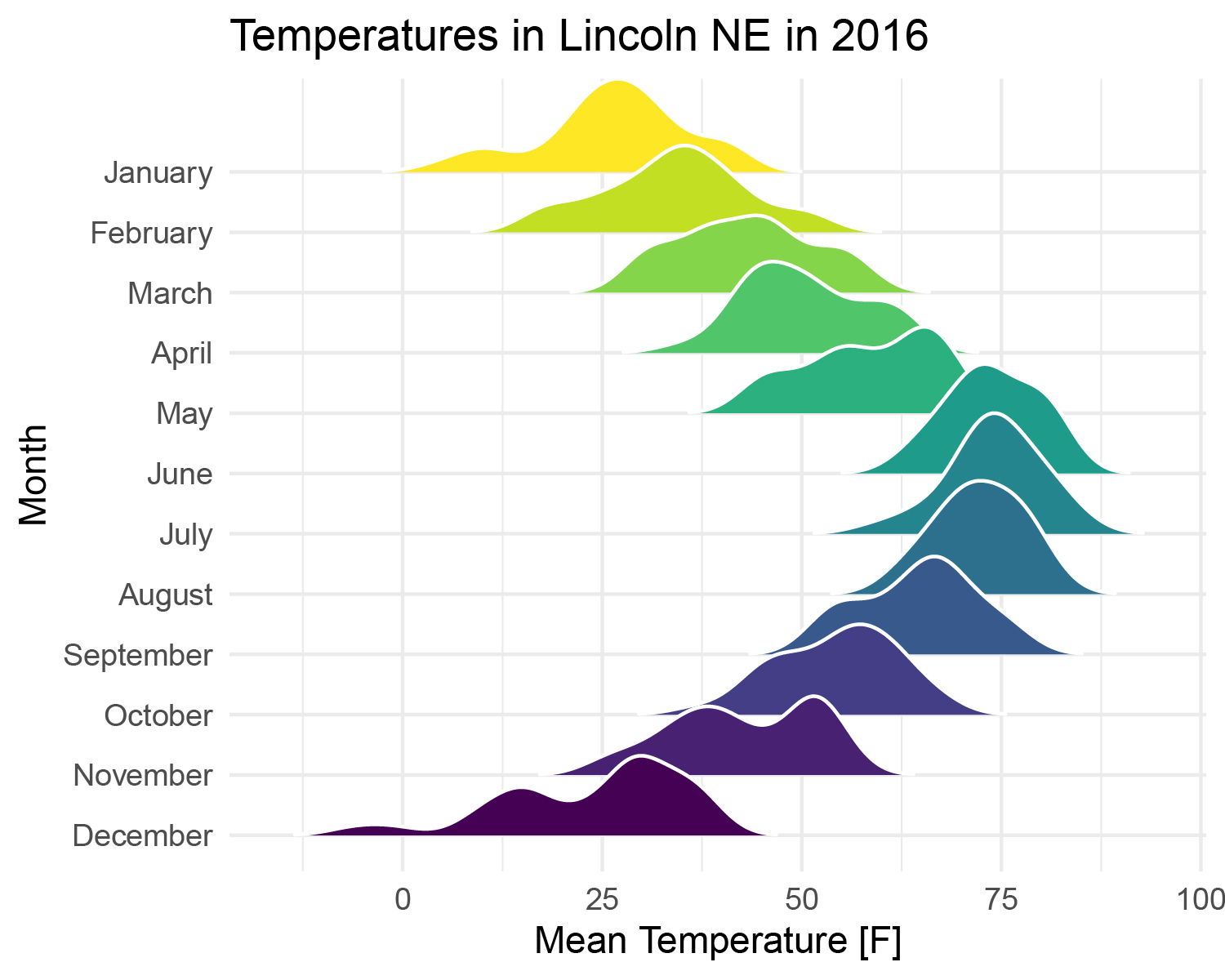
情景一
x为连续型变量,y为分类变量,按照y分类进行颜色填充。
当你拥有一个连续型变量,一个分类变量,并且要按分类变量填充颜色时,适用此种情形。
# 情景一:x为连续型变量,y为分类变量---------------------------------------------------
# 按照y分类进行颜色填充
ggplot(pdata, aes(x = `Mean Temperature [F]`, y = Month,fill=Month)) +
geom_density_ridges(color='white', #设置概率密度线的填充颜色
rel_min_height = 0.005, # 剪掉拖尾的尾巴,相对于任何密度曲线的最高点的百分比截止值
scale = 2)+ #设置山脊高度
scale_fill_viridis(option="viridis", discrete=TRUE)+ #设置颜色
theme_minimal()+ #设置主题
theme(legend.position = 'None')+ #取消图例
labs(title = 'Temperatures in Lincoln NE in 2016') #设置标题
ggsave('plot1.pdf',width = 5,height = 4)
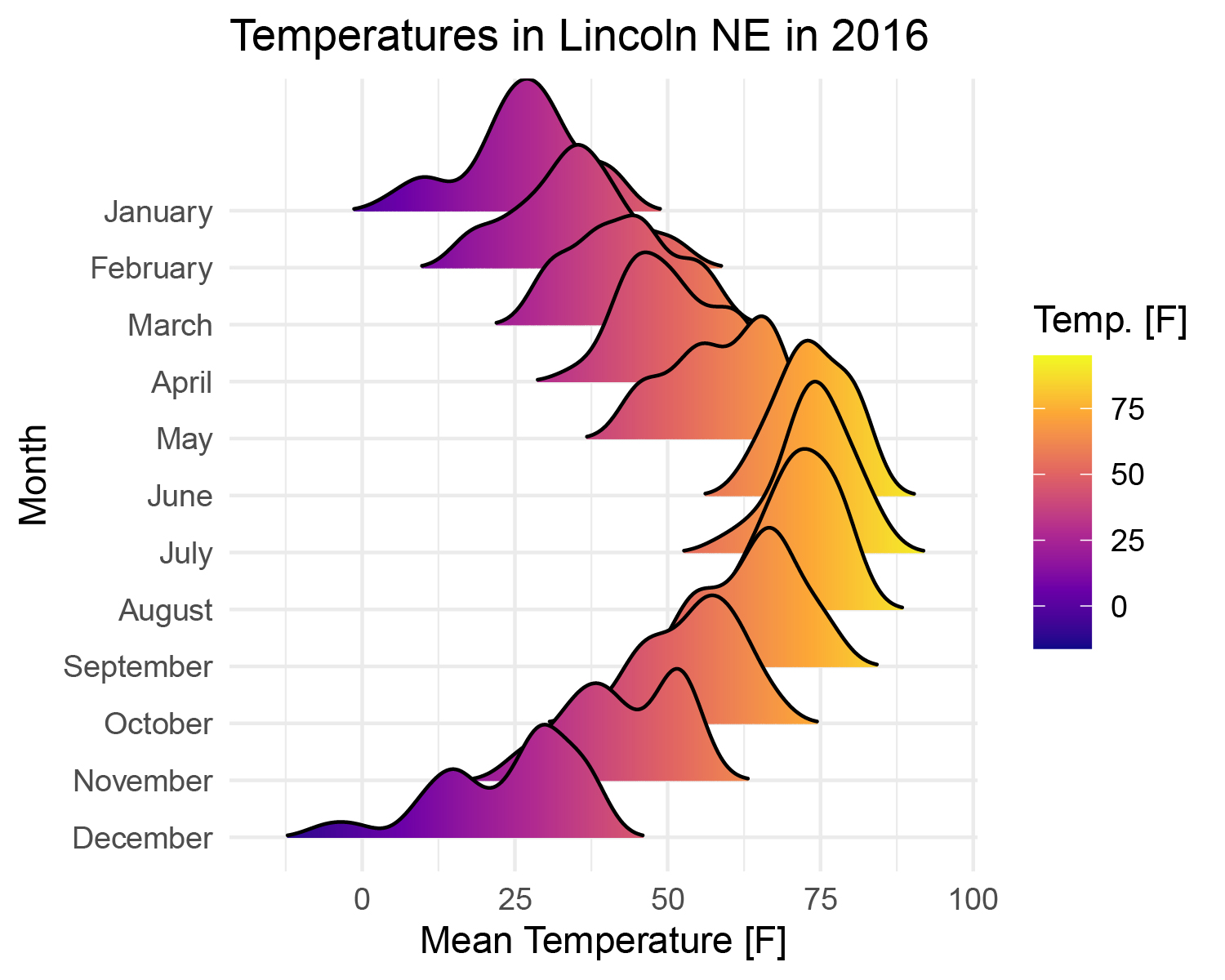
情景二
x为连续型变量,y为分类变量,按照x值进行颜色填充。
当你拥有一个连续型变量,一个分类变量,并且要按连续型变量填充颜色时,适用此种情形。
# 情景二:x为连续型变量,y为分类变量----------------------------------------------------
# 按照x值进行颜色填充
ggplot(pdata,
aes(x = `Mean Temperature [F]`, y = Month, fill = stat(x))) +
geom_density_ridges_gradient(rel_min_height = 0.01, # 剪掉拖尾的尾巴,相对于任何密度曲线的最高点的百分比截止值
scale = 3) + #设置山脊高度
scale_fill_viridis_c(name = "Temp. [F]", option = "C")+ #设置颜色
labs(title = 'Temperatures in Lincoln NE in 2016')+ #设置标题
theme_minimal() #设置主题
ggsave('plot2.pdf',width = 5,height = 4)
情景三:
x为连续型变量,y为分类变量,height为x的密度值(连续型变量),按照y分类进行颜色填充。
当你拥有一个连续型变量,一个分类变量,以及连续型变量的密度值,并且要按分类变量填充颜色时,适用此种情形。
# 情景三:x为连续型变量,y为分类变量,height为x的密度值(连续型变量)---------------------
# 按照y分类进行颜色填充
# 手动计算数值型变量的概率密度值
pdata2 <- pdata %>%
group_by(Month) %>%
group_modify(~ ggplot2:::compute_density(.x$`Mean Temperature [F]`, NULL)) %>%
rename(`Mean Temperature [F]` = x)
# 绘图
ggplot(pdata2,
aes(x = `Mean Temperature [F]`, y = Month, height = density,fill=Month)) +
geom_density_ridges(stat = "identity")+
scale_fill_viridis(option="viridis", discrete=TRUE)+
theme_minimal()+
theme(legend.position = 'None')
ggsave('plot3.pdf',width = 5,height = 4)
情景四:
概率密度图+原始数据点
# 概率密度图+原始数据点---------------------------------------------
ggplot(pdata, aes(x = `Mean Temperature [F]`, y = Month,fill=Month)) +
geom_density_ridges(color='black',
rel_min_height = 0.001,
scale = 1,
jittered_points = TRUE, #显示抖动点
alpha=0.7, #设置透明度
point_size=0.7)+ #设置点的大小
scale_fill_viridis(option="viridis", discrete=TRUE)+
theme_minimal()+
theme(legend.position = 'None')+
labs(title = 'Temperatures in Lincoln NE in 2016')
ggsave('plot4.pdf',width = 5,height = 4)
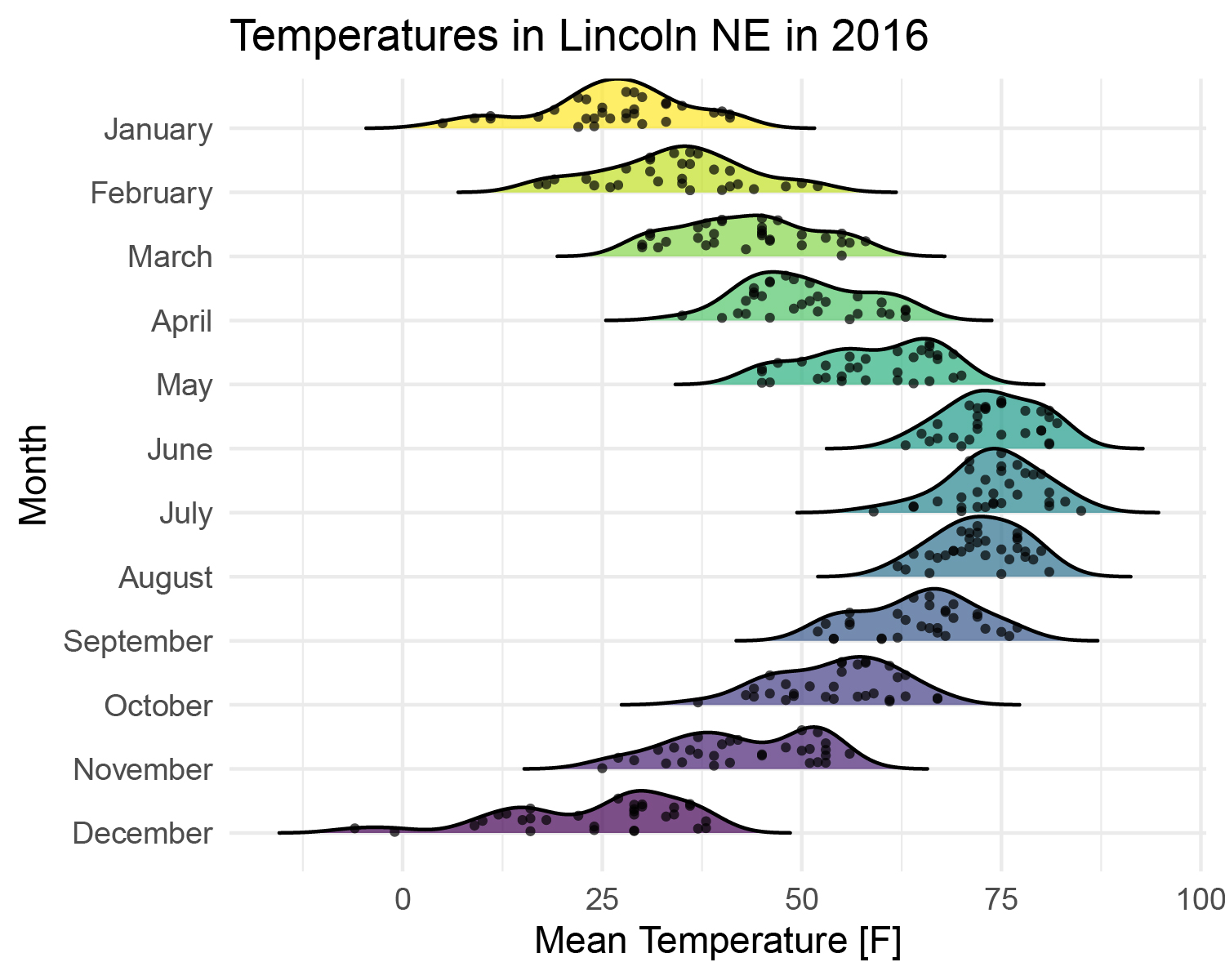
以上就是山脊图绘制概率密度曲线时的使用情景分类,总结来说情景1、情景2适用于没有计算概率密度值时使用,场景3适用于已经计算了概率密度值时使用。山脊图也不仅仅只能应用于绘制概率密度曲线,在场景三中,只要能提供相应类型的数据,就可以绘制山脊图。
示例获取
示例代码及数据获取:
方式①:转发此文至朋友圈,所有人可见,保留1h,集6个赞,文案附“推荐关注”。1h后截图发送后台,并留言“20240117山脊图”。
方式②:关注公众号,文末点击“喜欢作者”,赞赏本文,金额随意。截图发送后台,并留言“20240117山脊图”。
24h之内回复,不要着急哦。
合集文章
相关性网络热图 / linkET包 / Mantel test
R进阶绘图–散点箱线图+显著性 / 组间差异比较 / ggpubr包
本期的内容就到这里了,喜欢的小伙伴,欢迎点赞、转发、收藏、在看哦!
点击下方卡片,关注数据之帆,成为一帆的原始粉丝,和一帆一起进步吧!
参考资料
https://wilkelab.org/ggridges/articles/introduction.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









