




 本文详细介绍如何使用Python的requests库进行网络爬虫的基本请求操作,包括GET和POST请求的发送、响应处理、解决乱码问题的方法、设置请求头、处理超时及cookie等关键步骤。
本文详细介绍如何使用Python的requests库进行网络爬虫的基本请求操作,包括GET和POST请求的发送、响应处理、解决乱码问题的方法、设置请求头、处理超时及cookie等关键步骤。
文章目录
使用事前
- pip install requests
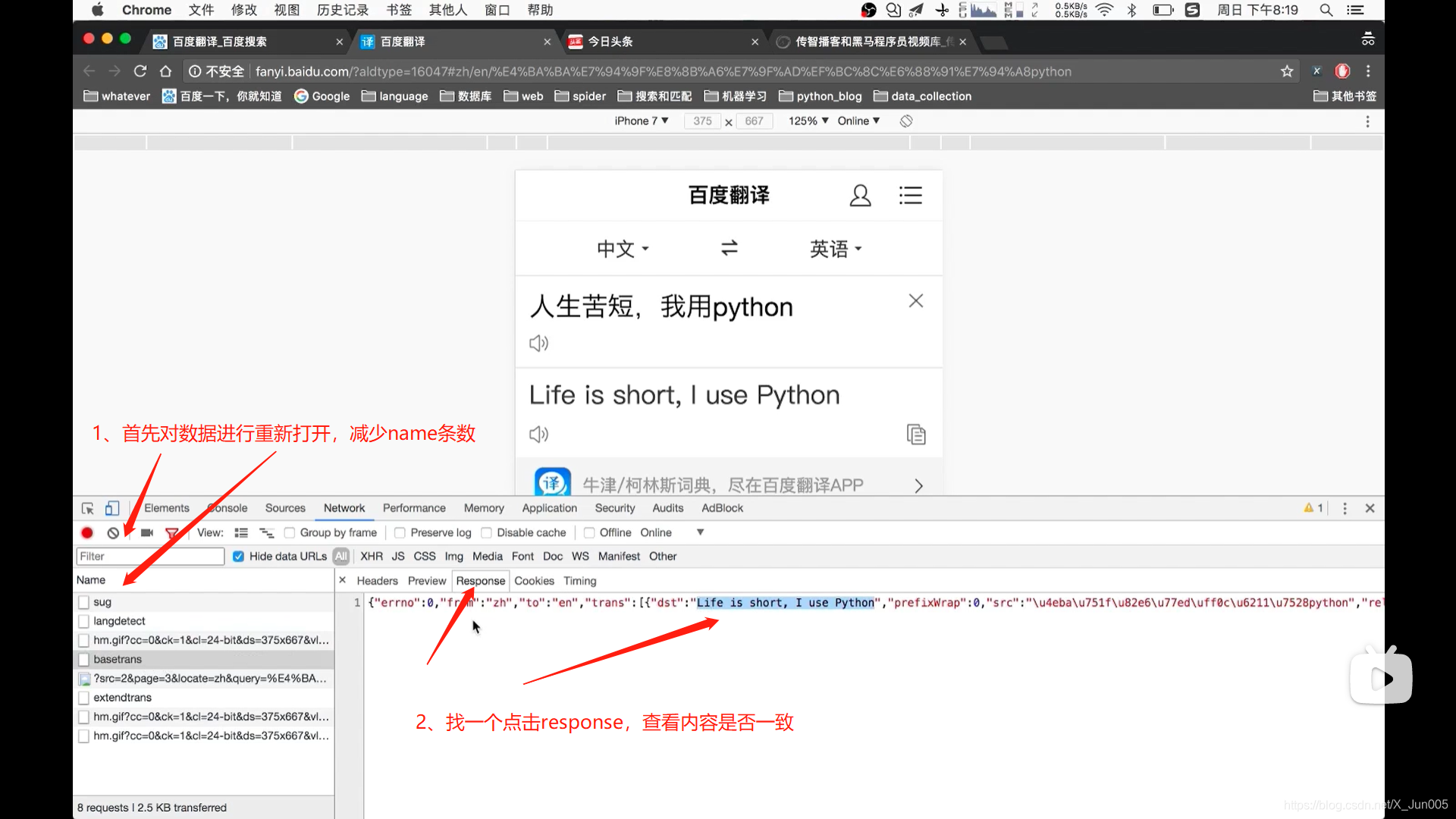
发送get请求和post请求。获取响应
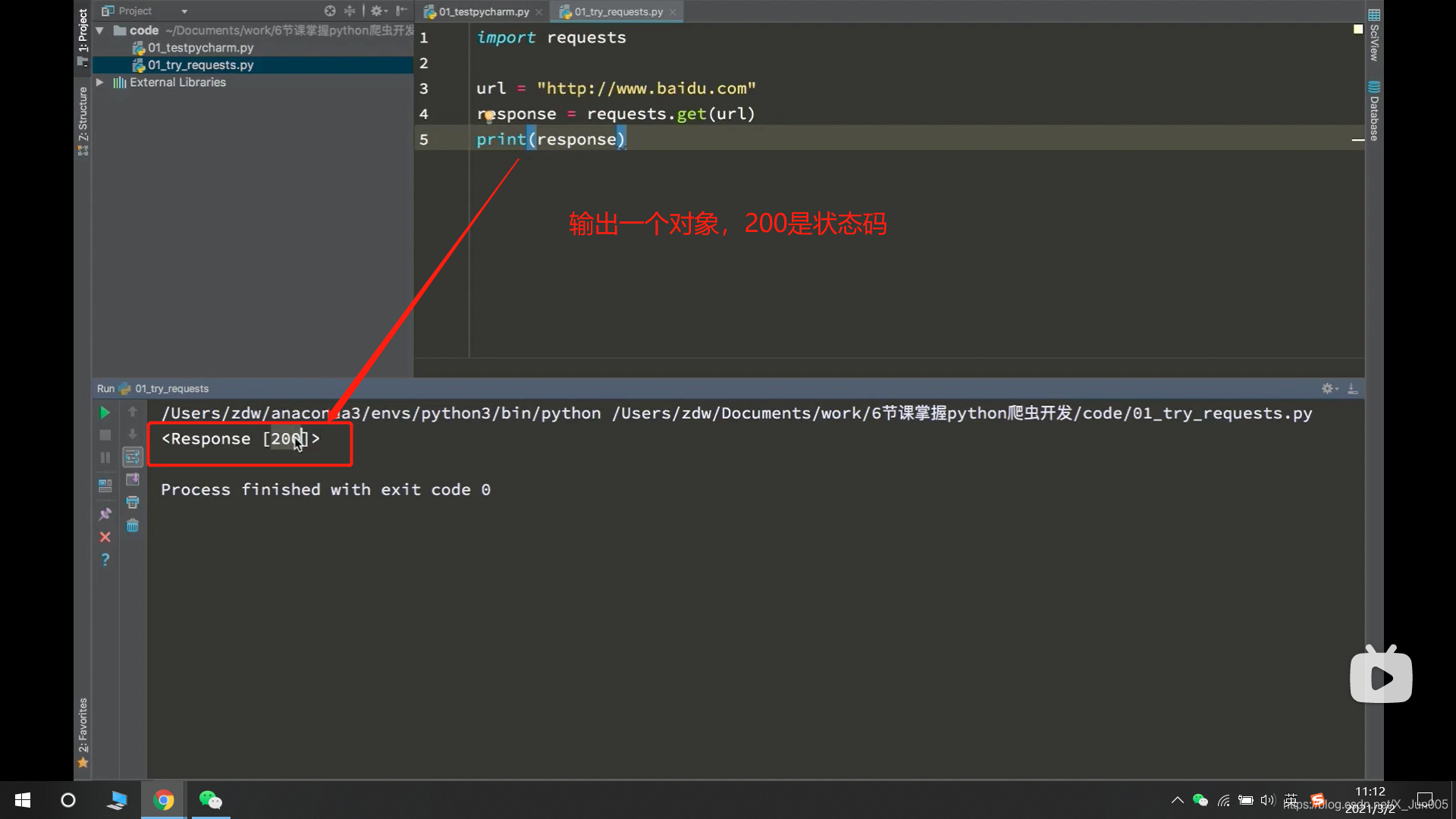
- response = requests.get(url) # 发送get请求,请求URL地址对应的响应,结果用response接收
response.get
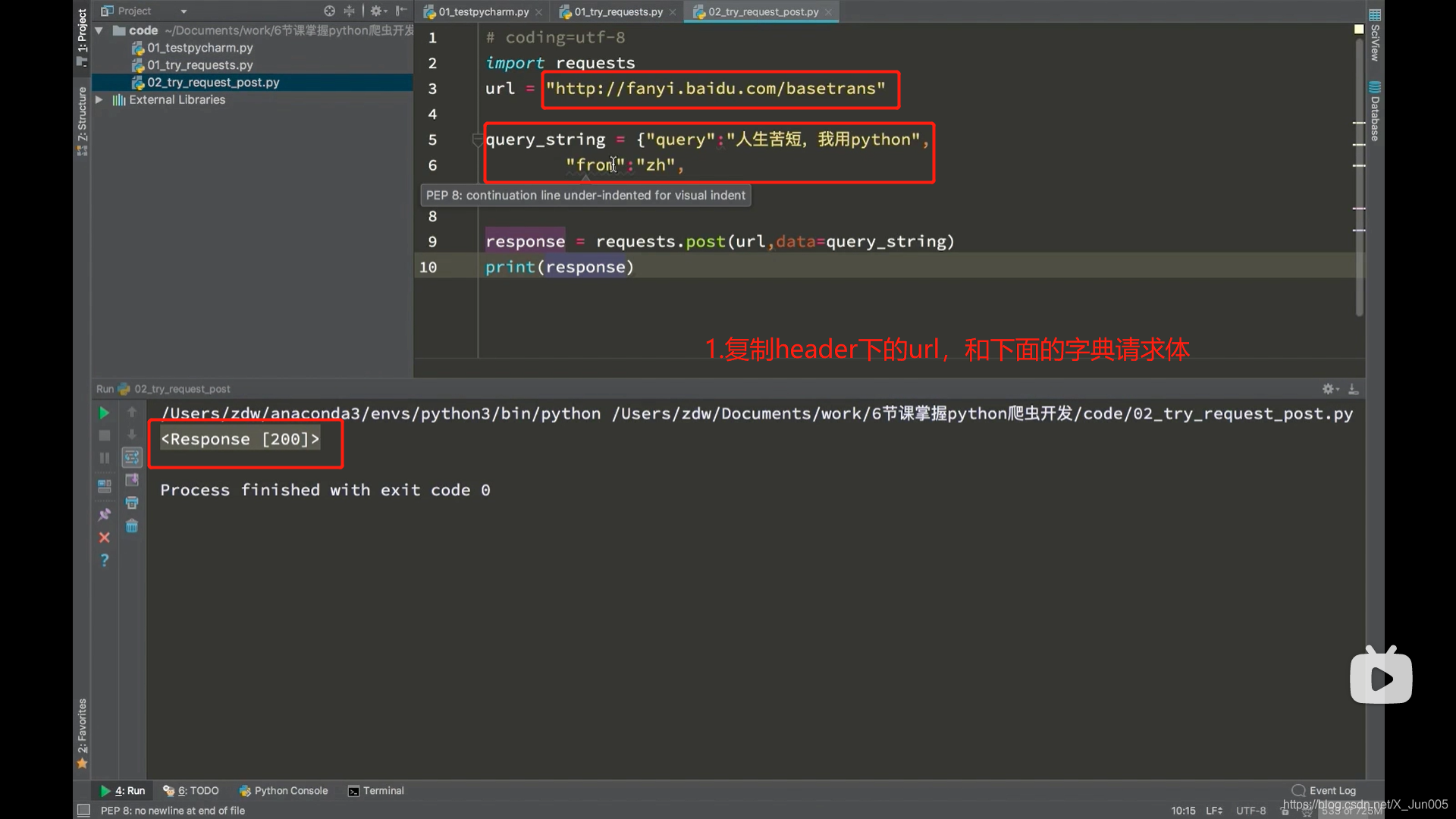
- response = requests.post(url,data={请求体的字典} # 请求post
response的方法
-
response.text
- 该方式往往会出现乱码
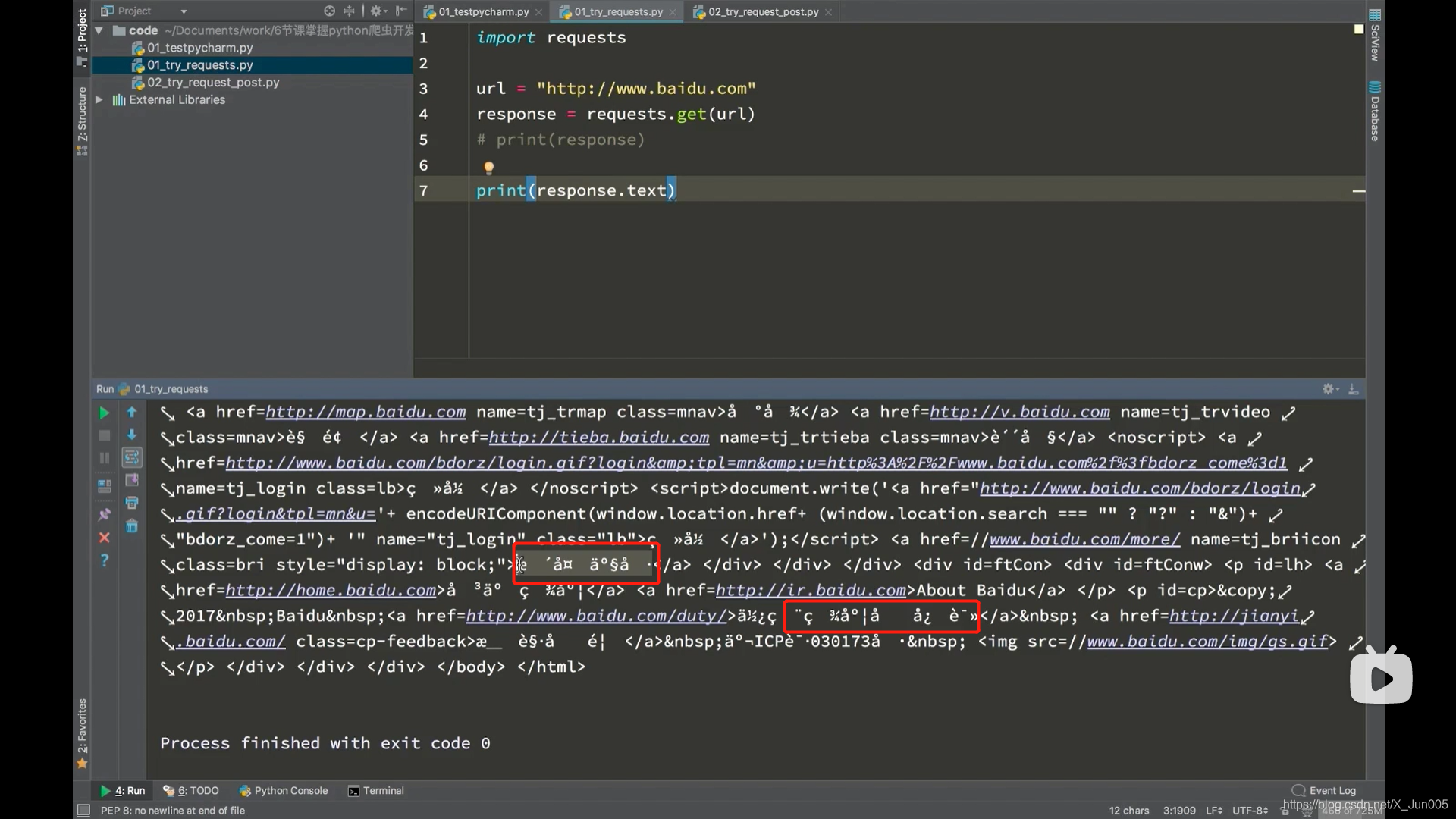
- 出现乱码使用response.encoding=“utf-8”(为什么使用utf-8?因为大部分的网页都用的utf-8编码,所以一般情况下都是)
-
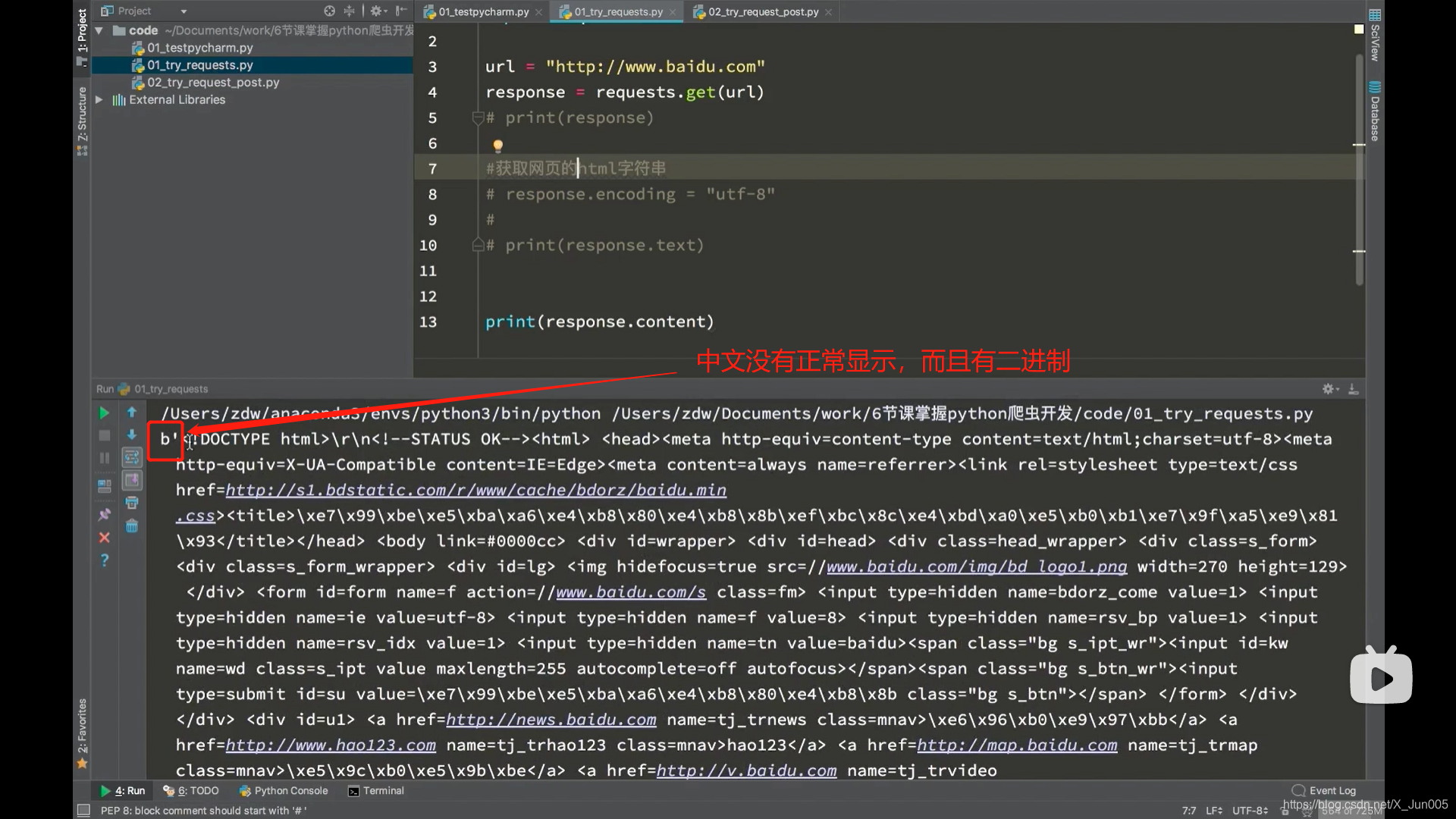
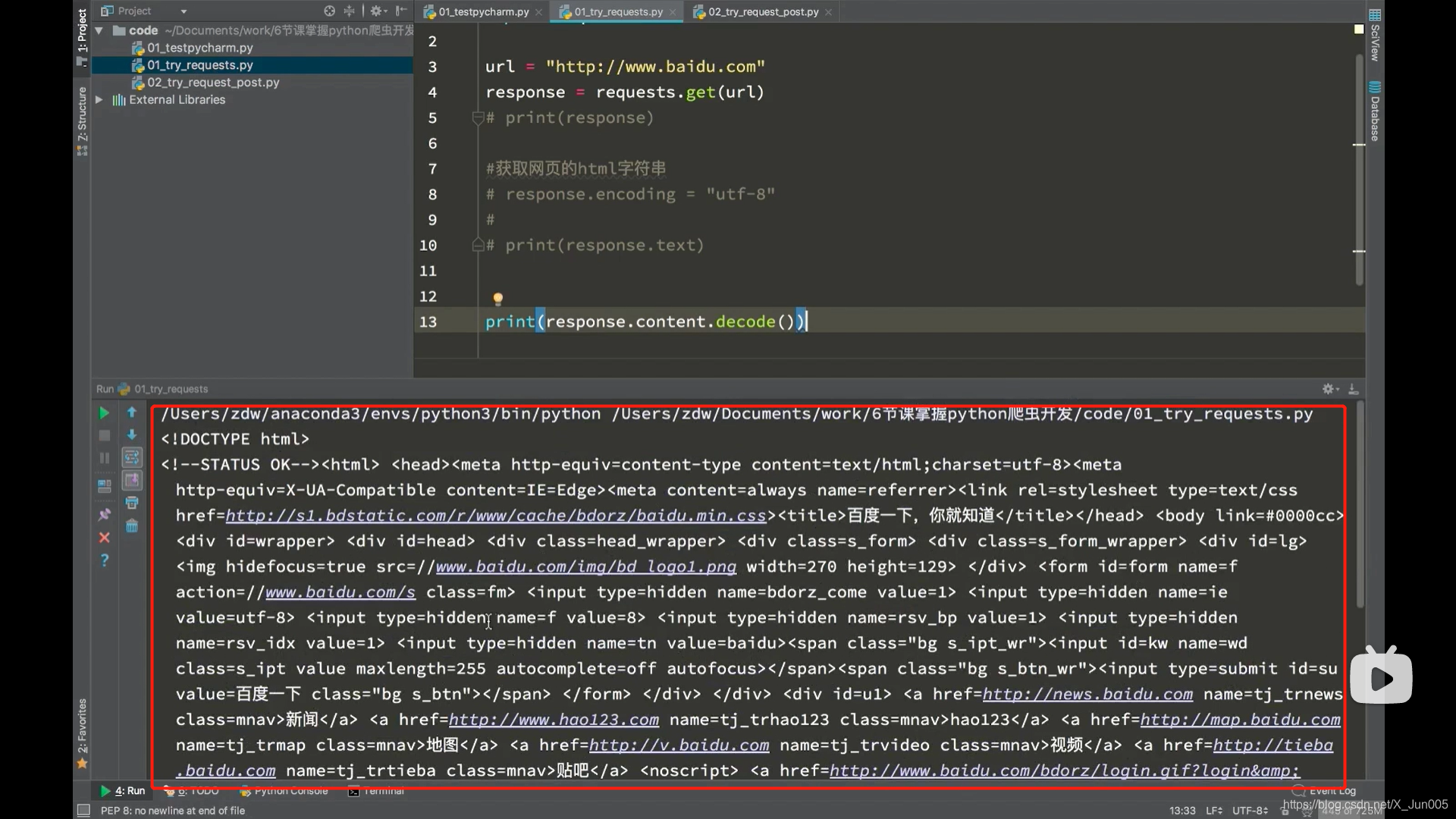
第二个方法:response.content.decode() # decode python3默认utf-8解码
- 把响应的二进制字节流转化为str类型
- response.request.url # 发送请求的url
- response.url # response响应的url地址
- response.request.headers # 请求头
- response.headers # 响应头
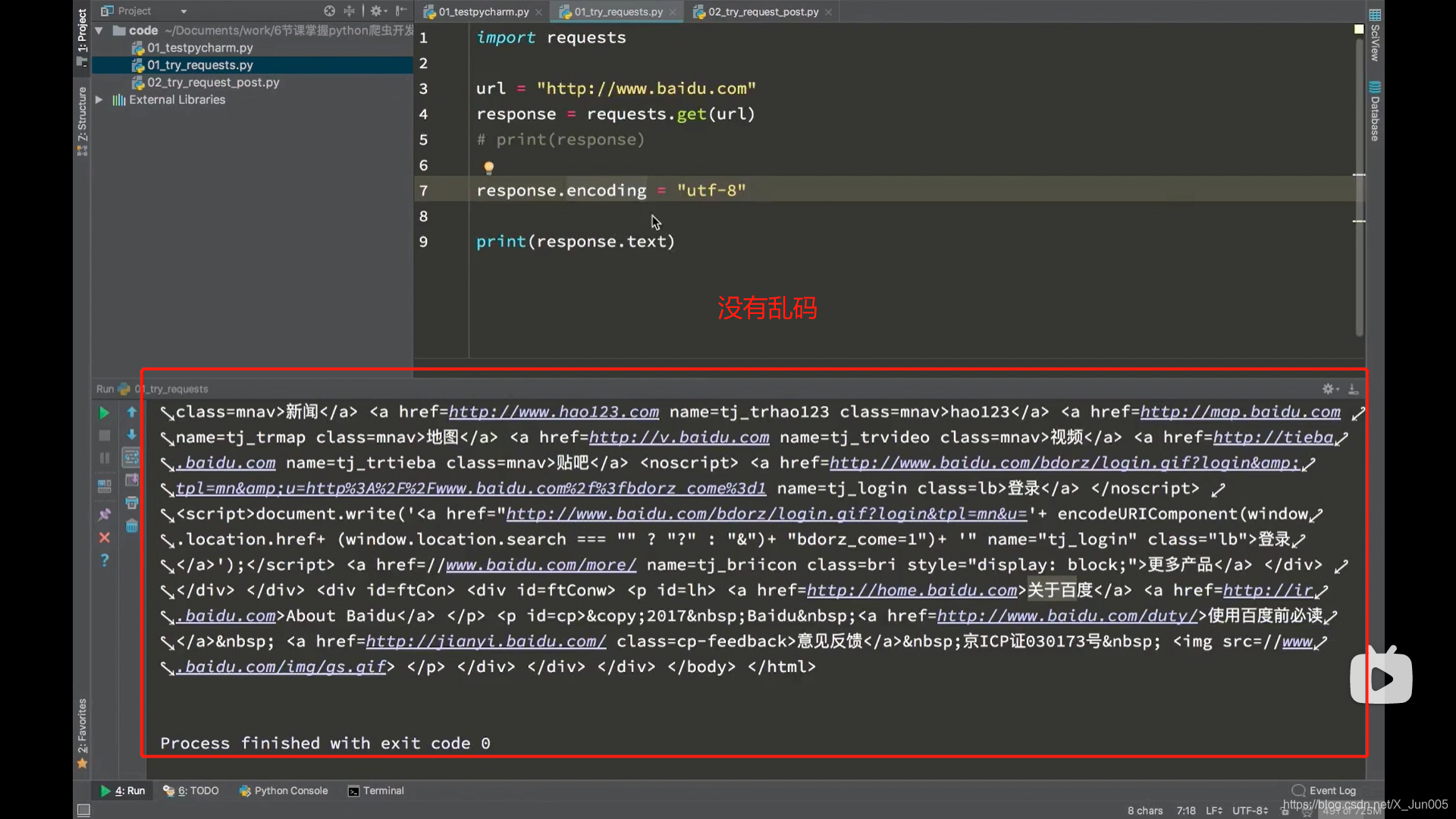
获取网页源码正确的打开方式(通过下面三种方式一定能够获取到网页的正确解码之后的字符串)(python3)
- 1、response.content.decode() # 如果不可行就要考虑第二种思路
- 2、response.content.decode(‘gbk’)
- 3、response.text
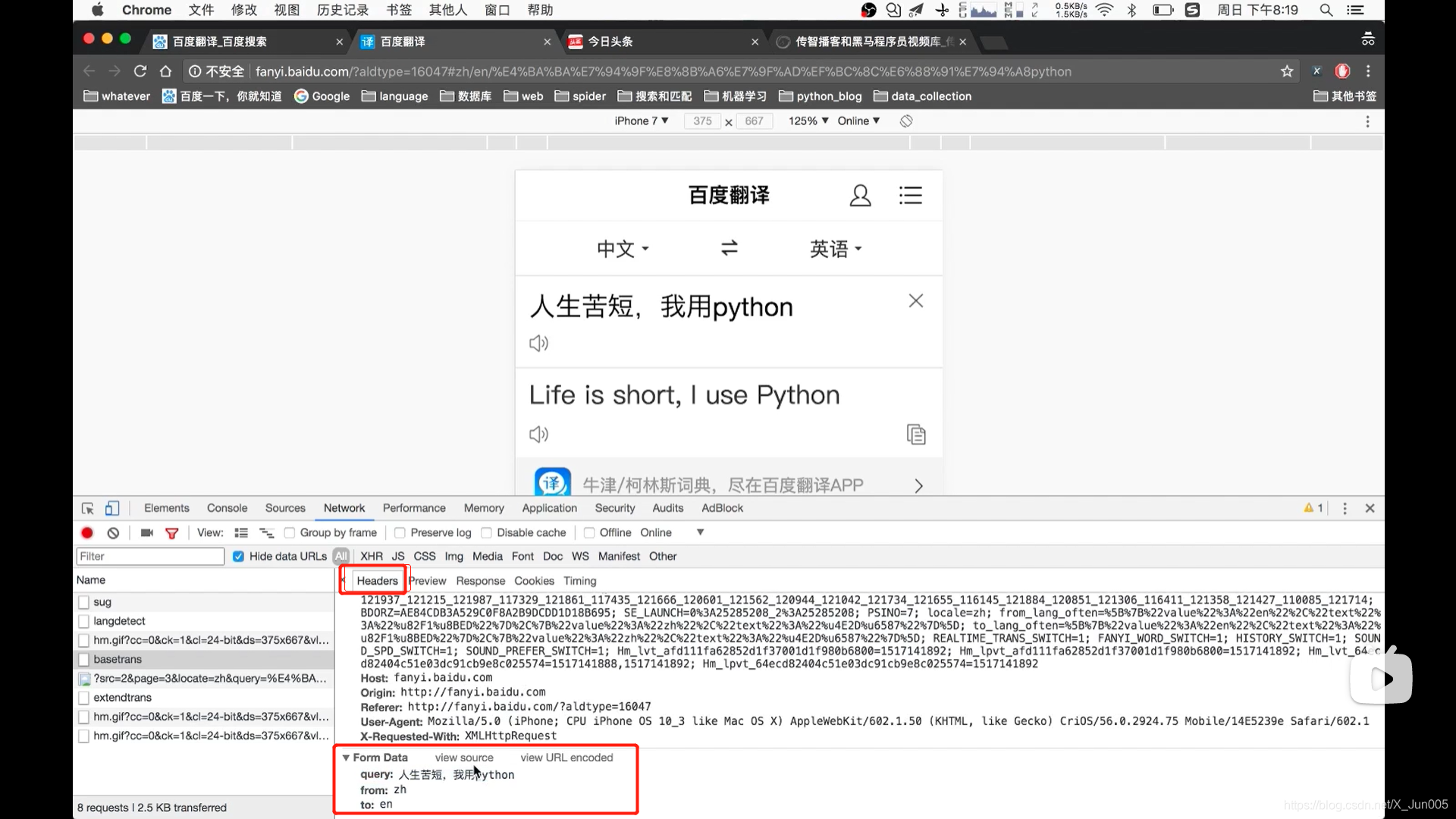
发送带header的请求
- 为了模拟浏览器,获取和浏览器一模一样的内容
- 大部分情况下,我们只需要带上user-agent就可以获取,如果不行,我们就可以考虑把除了cookie的其他参数带上,如果还不行,我们就要考虑带上cookie了
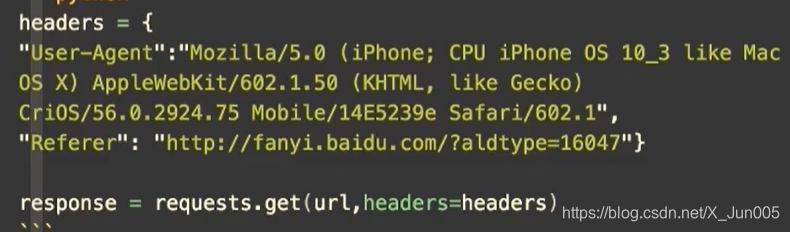
使用超时参数
request.get(url,headers= headers,timeout - 3) # 3秒内必须返回响应,否则会报错
处理cookie相关的请求

session模块(模拟登录)
当我们使用session时候,我们并没有真正去操作cookie,因为session模块已经将cookie处理的非常完善了,而且使用简单,唯一和requests区别的就是多了一个帮助我们保存cookie的功能

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









