




14 Leader 选举:如何保证分布式数据的一致性?
我们知道在 ZooKeeper 集群中,服务器分为 Leader 服务器、 Follower 服务器以及 Observer 服务器。
可以这样认为,Leader 选举是一个过程,在这个过程中 ZooKeeper 主要做了两个重要工作,一个是数据同步,另一个是选举出新的 Leader 服务器。今天我们主要先介绍第一个工作,ZooKeeper 集群中的数据同步问题。
Leader 的协调过程
在分布式系统中有一个著名的 CAP 定理,是说一个分布式系统不能同时满足一致性、可用性,以及分区容错性。今天我们要讲的就是一致性。其实 ZooKeeper 中实现的一致性也不是强一致性,即集群中各个服务器上的数据每时每刻都是保持一致的特性。在 ZooKeeper 中,采用的是最终一致的特性,即经过一段时间后,ZooKeeper 集群服务器上的数据最终保持一致的特性。
在 ZooKeeper 集群中,Leader 服务器主要负责处理事物性的请求,而在接收到一个客户端的事务性请求操作时,Leader 服务器会先向集群中的各个机器针对该条会话发起投票询问。
要想实现 ZooKeeper 集群中的最终一致性,我们先要确定什么情况下会对 ZooKeeper 集群服务产生不一致的情况。如下图所示:
在集群初始化启动的时候,首先要同步集群中各个服务器上的数据。而在集群中 Leader 服务器崩溃时,需要选举出新的 Leader 而在这一过程中会导致各个服务器上数据的不一致,所以当选举出新的 Leader 服务器后需要进行数据的同步操作。
底层实现
与上面介绍的一样,我们的底层实现讲解主要围绕 ZooKeeper 集群中数据一致性的底层实现。ZooKeeper 在集群中采用的是多数原则方式,即当一个事务性的请求导致服务器上的数据发生改变时,ZooKeeper 只要保证集群上的多数机器的数据都正确变更了,就可以保证系统数据的一致性。 这是因为在一个 ZooKeeper 集群中,每一个 Follower 服务器都可以看作是 Leader 服务器的数据副本,需要保证集群中大多数机器数据是一致的,这样在集群中出现个别机器故障的时候,ZooKeeper 集群依然能够保证稳定运行。
在 ZooKeeper 集群服务的运行过程中,数据同步的过程如下图所示。当执行完数据变更的会话请求时,需要对集群中的服务器进行数据同步。
广播模式
ZooKeeper 在代码层的实现中定义了一个 HashSet 类型的变量,用来管理在集群中的 Follower 服务器,之后调用getForwardingFollowers 函数获取在集群中的 Follower 服务器,如下面这段代码所示:
public class Leader() {
HashSet<LearnerHandler> forwardingFollowers;
public List<LearnerHandler> getForwardingFollowers() {
synchronized (forwardingFollowers) {
return new ArrayList<LearnerHandler>(forwardingFollowers);
}
}
在 ZooKeeper 集群服务器对一个事物性的请求操作进行投票并通过后,Leader 服务器执行 isQuorumSynced 方法判断该 ZooKeeper 集群中的 Follower 节点的连接状态,由于 isQuorumSynced 方法可以被多个线程进行调用,所以在进行操作的时候要通过forwardingFollowers 字段进行加锁操作。之后遍历集群中的 Follower 服务器,根据服务器 zxid、以及数据同步状态等条件判断服务器的执行逻辑是否成功。之后统计 Follower 服务器的 sid 并返回。
public boolean isQuorumSynced(QuorumVerifier qv) {
synchronized (forwardingFollowers) {
for (LearnerHandler learnerHandler: forwardingFollowers) {
if (learnerHandler.synced()) {
ids.add(learnerHandler.getSid());
}
}
}
}
通过上面的介绍,Leader 服务器在集群中已经完成确定 Follower 服务器状态等同步数据前的准备工作,接下来 Leader 服务器会通过 request.setTxn 方法向集群中的 Follower 服务器发送数据变更的会话请求。这个过程中,我们可以把 Leader 服务器看作是 ZooKeeper 服务中的客户端,而其向集群中 Follower 服务器发送数据更新请求,集群中的 Follower 服务器收到请求后会处理该会话,之后进行数据变更操作。如下面的代码所示,在底层实现中,通过调用 request 请求对象的 setTxn 方法向 Follower 服务器发送请求,在 setTxn 函数中我们传入的参数有操作类型字段 CONFIG_NODE,表明该操作是数据同步操作。
request.setTxn(new SetDataTxn(ZooDefs.CONFIG_NODE, request.qv.toString().getBytes(), -1));
恢复模式
介绍完 Leader 节点如何管理 Follower 服务器进行数据同步后,接下来我们看一下当 Leader 服务器崩溃后 ZooKeeper 集群又是如何进行数据的恢复和同步的。
在前面的课程中我们介绍过,当 ZooKeeper 集群中一个 Leader 服务器失效时,会重新在 Follower 服务器中选举出一个新的服务器作为 Leader 服务器。而 ZooKeeper 服务往往处在高并发的使用场景中,如果在这个过程中有新的事务性请求操作,应该如何处理呢? 由于此时集群中不存在 Leader 服务器了,理论上 ZooKeeper 会直接丢失该条请求,会话不进行处理,但是这样做在实际的生产中显然是不行的,那么 ZooKeeper 具体是怎么做的呢?
在 ZooKeeper 中,重新选举 Leader 服务器会经历一段时间,因此理论上在 ZooKeeper 集群中会短暂的没有 Leader 服务器,在这种情况下接收到事务性请求操作的时候,ZooKeeper 服务会先将这个会话进行挂起操作,挂起的会话不会计算会话的超时时间,之后在 Leader 服务器产生后系统会同步执行这些会话操作。
到这里我们就对 ZooKeeper 中数据一致性的解决原理和底层实现都做了较为详细的介绍。我们总结一下,ZooKeeper 集群在处理一致性问题的时候基本采用了两种方式来协调集群中的服务器工作,分别是恢复模式和广播模式。
- 恢复模式:当 ZooKeeper 集群中的 Leader 服务器崩溃后,ZooKeeper 集群就采用恢复模式的方式进行工作,在这个工程中,ZooKeeper 集群会首先进行 Leader 节点服务器的重新选择,之后在选举出 Leader 服务器后对系统中所有的服务器进行数据同步进而保证集群中服务器上的数据的一致性。
- 广播模式:当 ZooKeeper 集群中具有 Leader 服务器,并且可以正常工作时,集群中又有新的 Follower 服务器加入 ZooKeeper 中参与工作,这种情况常常发生在系统性能到达瓶颈,进而对系统进行动态扩容的使用场景。在这种情况下,如果不做任何操作,那么新加入的服务器作为 Follower 服务器,其上的数据与 ZooKeeper 集群中其他服务器上的数据不一致。当有新的查询会话请求发送到 ZooKeeper 集群进行处理,而恰巧该请求实际被分发给这台新加入的 Follower 机器进行处理,就会导致明明在集群中存在的数据,在这台服务器上却查询不到,导致数据查询不一致的情况。因此,在当有新的 Follower 服务器加入 ZooKeeper 集群中的时候,该台服务器会在恢复模式下启动,并找到集群中的 Leader 节点服务器,并同该 Leader 服务器进行数据同步。
LearnerHandler
介绍完 ZooKeeper 集群中数据同步的理论方法,我们再来分析一下在代码层面是如何实现的。记得在前面的课程中,我们提到过一个 LearnerHandler 类, 当时我们只是简单地从服务器之间的通信和协同工作的角度去分析了该类的作用。而 LearnerHandler 类其实可以看作是所有 Learner 服务器内部工作的处理者,它所负责的工作有:进行 Follower、Observer 服务器与 Leader 服务器的数据同步、事务性会话请求的转发以及 Proposal 提议投票等功能。
LearnerHandler 是一个多线程的类,在 ZooKeeper 集群服务运行过程中,一个 Follower 或 Observer 服务器就对应一个 LearnerHandler 。在集群服务器彼此协调工作的过程中,Leader 服务器会与每一个 Learner 服务器维持一个长连接,并启动一个单独的 LearnerHandler 线程进行处理。
如下面的代码所示,在 LearnerHandler 线程类中,最核心的方法就是 run 方法,处理数据同步等功能都在该方法中进行调用。首先通过 syncFollower 函数判断数据同步的方式是否是快照方式。如果是快照方式,就将 Leader 服务器上的数据操作日志 dump 出来发送给 Follower 等服务器,在 Follower 等服务器接收到数据操作日志后,在本地执行该日志,最终完成数据的同步操作。
public void run() {
boolean needSnap = syncFollower(peerLastZxid, leader.zk.getZKDatabase(), leader);
if(needSnap){
leader.zk.getZKDatabase().serializeSnapshot(oa);
oa.writeString("BenWasHere", "signature");
bufferedOutput.flush();
}
}
通过操作日志的方式进行数据同步或备份的操作已经是行业中普遍采用的方式,比如我们都熟悉的 MySQL 、Redis 等数据库也是采用操作日志的方式。
结束
请你注意,为了更好地讲解 Leader 服务器在管理集群服务器中数据一致性的作用,我介绍了当集群中 Leader 服务器崩溃时,如何处理事务性会话请求的过程。现在我们知道了在这种情况下,ZooKeeper 会把事务性请求会话挂起,暂时不进行操作。可能有些同学会产生这样的问题:如果会话挂起过多,会不会对系统产生压力,当 Leader 服务器产生后,一下子要处理大量的会话请求,这样不会造成服务器高负荷吗?
这里请你放心,Leader 选举的过程非常快速,在这期间不会造成大量事务性请求的会话操作积压,并不会对集群性能产生大的影响。
15 ZooKeeper 究竟是怎么选中 Leader 的?
下面我们就深入到 ZooKeeper 的底层,来学习一下 Leader 服务器选举的实现方法。
Leader 服务器的选举原理
Leader 服务器的作用是管理 ZooKeeper 集群中的其他服务器。因此,如果是单独一台服务器,不构成集群规模。在 ZooKeeper 服务的运行中不会选举 Leader 服务器,也不会作为 Leader 服务器运行。在前面的课程中我们介绍过,一个 ZooKeeper 服务要想满足集群方式运行,至少需要三台服务器。本课时我们就以三台服务器组成的 ZooKeeper 集群为例,介绍一下 Leader 服务器选举的内部过程和底层实现。
服务启动时的 Leader 选举
Leader 服务器的选举操作主要发生在两种情况下。第一种就是 ZooKeeper 集群服务启动的时候,第二种就是在 ZooKeeper 集群中旧的 Leader 服务器失效时,这时 ZooKeeper 集群需要选举出新的 Leader 服务器。
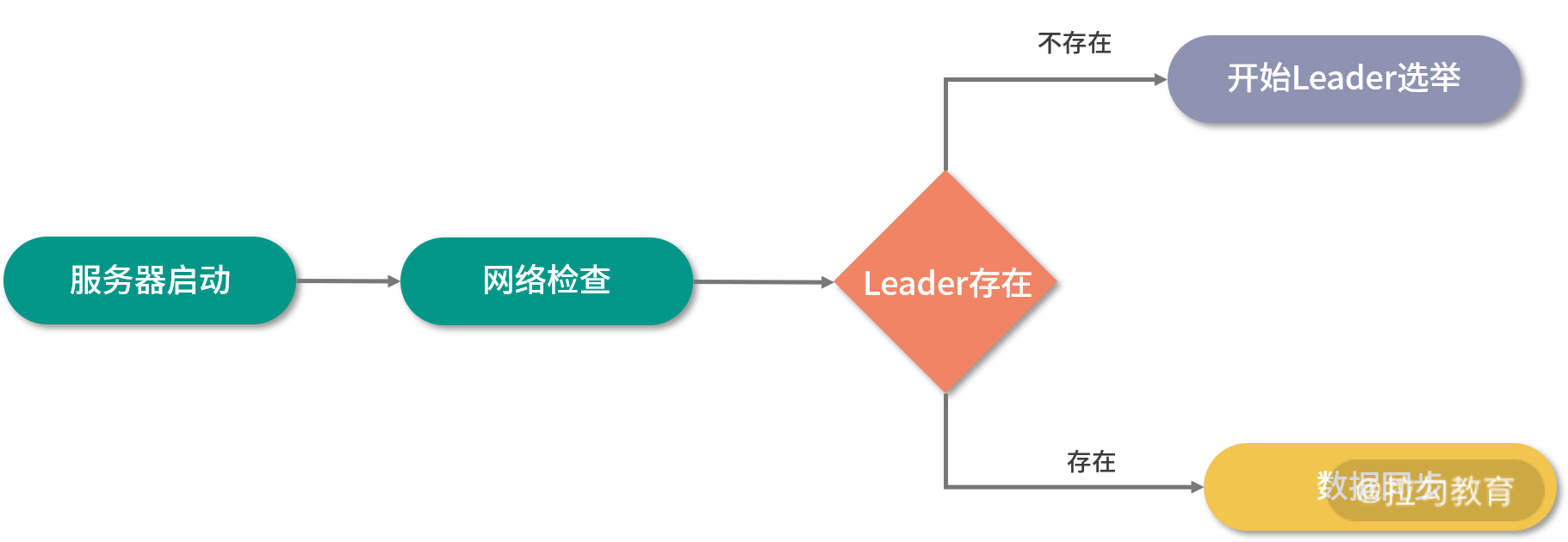
我们先来介绍在 ZooKeeper 集群服务最初启动的时候,Leader 服务器是如何选举的。在 ZooKeeper 集群启动时,需要在集群中的服务器之间确定一台 Leader 服务器。当 ZooKeeper 集群中的三台服务器启动之后,首先会进行通信检查,如果集群中的服务器之间能够进行通信。集群中的三台机器开始尝试寻找集群中的 Leader 服务器并进行数据同步等操作。如何这时没有搜索到 Leader 服务器,说明集群中不存在 Leader 服务器。这时 ZooKeeper 集群开始发起 Leader 服务器选举。在整个 ZooKeeper 集群中 Leader 选举主要可以分为三大步骤分别是:发起投票、接收投票、统计投票。
发起投票
我们先来看一下发起投票的流程,在 ZooKeeper 服务器集群初始化启动的时候,集群中的每一台服务器都会将自己作为 Leader 服务器进行投票。也就是每次投票时,发送的服务器的 myid(服务器标识符)和 ZXID (集群投票信息标识符)等选票信息字段都指向本机服务器。 而一个投票信息就是通过这两个字段组成的。以集群中三个服务器 Serverhost1、Serverhost2、Serverhost3 为例,三个服务器的投票内容分别是:Severhost1 的投票是(1,0)、Serverhost2 服务器的投票是(2,0)、Serverhost3 服务器的投票是(3,0)。
接收投票
集群中各个服务器在发起投票的同时,也通过网络接收来自集群中其他服务器的投票信息。
在接收到网络中的投票信息后,服务器内部首先会判断该条投票信息的有效性。检查该条投票信息的时效性,是否是本轮最新的投票,并检查该条投票信息是否是处于 LOOKING 状态的服务器发出的。
统计投票
在接收到投票后,ZooKeeper 集群就该处理和统计投票结果了。对于每条接收到的投票信息,集群中的每一台服务器都会将自己的投票信息与其接收到的 ZooKeeper 集群中的其他投票信息进行对比。主要进行对比的内容是 ZXID,ZXID 数值比较大的投票信息优先作为 Leader 服务器。如果每个投票信息中的 ZXID 相同,就会接着比对投票信息中的 myid 信息字段,选举出 myid 较大的服务器作为 Leader 服务器。
拿上面列举的三个服务器组成的集群例子来说,对于 Serverhost1,服务器的投票信息是(1,0),该服务器接收到的 Serverhost2 服务器的投票信息是(2,0)。在 ZooKeeper 集群服务运行的过程中,首先会对比 ZXID,发现结果相同之后,对比 myid,发现 Serverhost2 服务器的 myid 比较大,于是更新自己的投票信息为(2,0),并重新向 ZooKeeper 集群中的服务器发送新的投票信息。而 Serverhost2 服务器则保留自身的投票信息,并重新向 ZooKeeper 集群服务器中发送投票信息。
而当每轮投票过后,ZooKeeper 服务都会统计集群中服务器的投票结果,判断是否有过半数的机器投出一样的信息。如果存在过半数投票信息指向的服务器,那么该台服务器就被选举为 Leader 服务器。比如上面我们举的例子中,ZooKeeper 集群会选举 Severhost2 服务器作为 Leader 服务器。
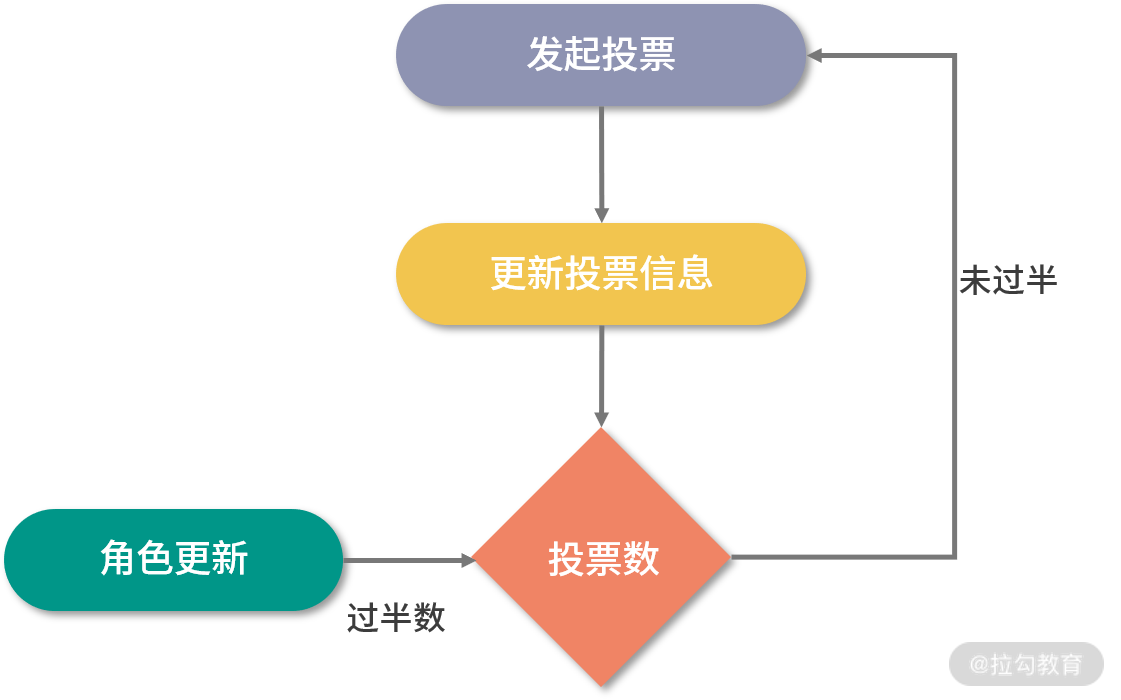
当 ZooKeeper 集群选举出 Leader 服务器后,ZooKeeper 集群中的服务器就开始更新自己的角色信息,除被选举成 Leader 的服务器之外,其他集群中的服务器角色变更为 Following。
服务运行时的 Leader 选举
上面我们介绍了 ZooKeeper 集群启动时 Leader 服务器的选举方法。接下来我们再看一下在 ZooKeeper 集群服务的运行过程中,Leader 服务器是如果进行选举的。
在 ZooKeeper 集群服务的运行过程中,Leader 服务器作为处理事物性请求以及管理其他角色服务器,在 ZooKeeper 集群中起到关键的作用。在前面的课程中我们提到过,当 ZooKeeper 集群中的 Leader 服务器发生崩溃时,集群会暂停处理事务性的会话请求,直到 ZooKeeper 集群中选举出新的 Leader 服务器。而整个 ZooKeeper 集群在重新选举 Leader 时也经过了四个过程,分别是变更服务器状态、发起投票、接收投票、统计投票。其中,与初始化启动时 Leader 服务器的选举过程相比,变更状态和发起投票这两个阶段的实现是不同的。下面我们来分别看看这两个阶段。
变更状态
与上面介绍的 ZooKeeper 集群服务器初始化阶段不同。在 ZooKeeper 集群服务运行的过程中,集群中每台服务器的角色已经确定了,当 Leader 服务器崩溃后 ,ZooKeeper 集群中的其他服务器会首先将自身的状态信息变为 LOOKING 状态,该状态表示服务器已经做好选举新 Leader 服务器的准备了,这之后整个 ZooKeeper 集群开始进入选举新的 Leader 服务器过程。
发起投票
ZooKeeper 集群重新选举 Leader 服务器的过程中发起投票的过程与初始化启动时发起投票的过程基本相同。首先每个集群中的服务器都会投票给自己,将投票信息中的 Zxid 和 myid 分别指向本机服务器。
底层实现
到目前为止,我们已经对 ZooKeeper 集群中 Leader 服务器的选举过程做了详细的介绍。接下来我们再深入 ZooKeeper 底层,来看一下底层实现的关键步骤。
之前我们介绍过,ZooKeeper 中实现的选举算法有三种,而在目前的 ZooKeeper 3.6 版本后,只支持 “快速选举” 这一种算法。而在代码层面的实现中,QuorumCnxManager 作为核心的实现类,用来管理 Leader 服务器与 Follow 服务器的 TCP 通信,以及消息的接收与发送等功能。在 QuorumCnxManager 中,主要定义了 ConcurrentHashMap 类型的 senderWorkerMap 数据字段,用来管理每一个通信的服务器。
public class QuorumCnxManager {
final ConcurrentHashMap<Long, SendWorker> senderWorkerMap;
final ConcurrentHashMap<Long, ArrayBlockingQueue<ByteBuffer>> queueSendMap;
final ConcurrentHashMap<Long, ByteBuffer> lastMessageSent;
}
而在 QuorumCnxManager 类的内部,定义了 RecvWorker 内部类。该类继承了一个 ZooKeeperThread 类的多线程类。主要负责消息接收。在 ZooKeeper 的实现中,为每一个集群中的通信服务器都分配一个 RecvWorker,负责接收来自其他服务器发送的信息。在 RecvWorker 的 run 函数中,不断通过 queueSendMap 队列读取信息。
class SendWorker extends ZooKeeperThread {
Long sid;
Socket sock;
volatile boolean running = true;
DataInputStream din;
final SendWorker sw;
public void run() {
threadCnt.incrementAndGet();
while (running && !shutdown && sock != null) {
int length = din.readInt();
if (length <= 0 || length > PACKETMAXSIZE) {
throw new IOException(
"Received packet with invalid packet: " + length);
}
byte[] msgArray = new byte[length];
din.readFully(msgArray, 0, length);
ByteBuffer message = ByteBuffer.wrap(msgArray);
addToRecvQueue(new Message(message.duplicate(), sid));
}
}
}
除了接收信息的功能外,QuorumCnxManager 内还定义了一个 SendWorker 内部类用来向集群中的其他服务器发送投票信息。如下面的代码所示。在 SendWorker 类中,不会立刻将投票信息发送到 ZooKeeper 集群中,而是将投票信息首先插入到 pollSendQueue 队列,之后通过 send 函数进行发送。
class SendWorker extends ZooKeeperThread {
Long sid;
Socket sock;
RecvWorker recvWorker;
volatile boolean running = true;
DataOutputStream dout;
public void run() {
while (running && !shutdown && sock != null) {
ByteBuffer b = null;
try {
ArrayBlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);
if (bq != null) {
b = pollSendQueue(bq, 1000, TimeUnit.MILLISECONDS);
} else {
LOG.error("No queue of incoming messages for " + "server " + sid);
break;
}
if(b != null){
lastMessageSent.put(sid, b);
send(b);
}
} catch (InterruptedException e) {
LOG.warn("Interrupted while waiting for message on queue", e);
}
}
}
}
实现了投票信息的发送与接收后,接下来我们就来看看如何处理投票结果。在 ZooKeeper 的底层,是通过 FastLeaderElection 类实现的。如下面的代码所示,在 FastLeaderElection 的内部,定义了最大通信间隔 maxNotificationInterval、服务器等待时间 finalizeWait 等属性配置。
public class FastLeaderElection implements Election {
final static int maxNotificationInterval = 60000;
final static int IGNOREVALUE = -1
QuorumCnxManager manager;
}
在 ZooKeeper 底层通过 getVote 函数来设置本机的投票内容,如下图面的代码所示,在 getVote 中通过 proposedLeader 服务器信息、proposedZxid 服务器 ZXID、proposedEpoch 投票轮次等信息封装投票信息。
synchronized public Vote getVote(){
return new Vote(proposedLeader, proposedZxid, proposedEpoch);
}
在完成投票信息的封装以及投票信息的接收和发送后。一个 ZooKeeper 集群中,Leader 服务器选举底层实现的关键步骤就已经介绍完了。 Leader 节点的底层实现过程的逻辑相对来说比较简单,基本分为封装投票信息、发送投票、接收投票等。
结束
通过本课时的学习,我们就 ZooKeeper 服务端在集群环境下,如何选举出 Leader 服务器做了一个比较详细的介绍。我们知道 Leader 选举一般发生在 ZooKeeper 集群服务初始化和集群中旧的 Leader 服务器崩溃时。Leader 选举保证了 ZooKeeper 集群运行的可靠性。当旧的 Leader 服务器发生崩溃时,需要重新选举出新的 Leader 服务器以保证集群服务的稳定性。
在这个过程中我们思考一个问题,那就是之前崩溃的 Leader 服务器是否会参与本次投票,以及是否能被重新选举为 Leader 服务器。这主要取决于在选举过程中旧的 Leader 服务器的运行状态。如果该服务器可以正常运行且可以和集群中其他服务器通信,那么该服务器也会参与新的 Leader 服务器的选举,在满足条件的情况下该台服务器也会再次被选举为新的 Leader 服务器。
16 ZooKeeper 集群中 Leader 与 Follower 的数据同步策略
在 Leader 节点选举后,还需要把 Leader 服务器和 Follow 服务器进行数据同步。在保证整个 ZooKeeper 集群中服务器数据一致的前提下,ZooKeeper 集群才能对外提供服务。
为什么要进行同步
接着上面介绍的内容,在我们介绍 ZooKeeper 集群数据同步之前,先要清楚为什么要进行数据同步。在 ZooKeeper 集群服务运行过程中,主要负责处理发送到 ZooKeeper 集群服务端的客户端会话请求。这些客户端的会话请求基本可以分为事务性的会话请求和非事务性的会话请求,而这两种会话的本质区别在于,执行会话请求后,ZooKeeper 集群服务器状态是否发生改变。
事务性会话请求最常用的操作类型有节点的创建、删除、更新等操作。而查询数据节点等会话请求操作就是非事务性的,因为查询不会造成 ZooKeeper 集群中服务器上数据状态的变更 。
我们之前介绍过,分布式环境下经常会出现 CAP 定义中的一致性问题。比如当一个 ZooKeeper 集群服务器中,Leader 节点处理了一个节点的创建会话操作后,该 Leader 服务器上就新增了一个数据节点。而如果不在 ZooKeeper 集群中进行数据同步,那么其他服务器上的数据则保持旧有的状态,新增加的节点在服务器上不存在。当 ZooKeeper 集群收到来自客户端的查询请求时,会出现该数据节点查询不到的情况,这就是典型的集群中服务器数据不一致的情况。为了避免这种情况的发生,在进行事务性请求的操作后,ZooKeeper 集群中的服务器要进行数据同步,而主要的数据同步是从 Learnning 服务器同步 Leader 服务器上的数据。
同步方法
在介绍了 ZooKeeper 集群服务器的同步作用后,接下来我们再学习一下 ZooKeeper 集群中数据同步的方法。我们主要通过三个方面来讲解 ZooKeeper 集群中的同步方法,分别是同步条件、同步过程、同步后的处理。
同步条件
同步条件是指在 ZooKeeper 集群中何时触发数据同步的机制。与上一课时中 Leader 选举首先要判断集群中 Leader 服务器是否存在不同,要想进行集群中的数据同步,首先需要 ZooKeeper 集群中存在用来进行数据同步的 Learning 服务器。 也就是说,当 ZooKeeper 集群中选举出 Leader 节点后,除了被选举为 Leader 的服务器,其他服务器都作为 Learnning 服务器,并向 Leader 服务器注册。之后系统就进入到数据同步的过程中。
同步过程
在数据同步的过程中,ZooKeeper 集群的主要工作就是将那些没有在 Learnning 服务器上执行过的事务性请求同步到 Learning 服务器上。这里请你注意,事务性的会话请求会被同步,而像数据节点的查询等非事务性请求则不在数据同步的操作范围内。 而在具体实现数据同步的时候,ZooKeeper 集群又提供四种同步方式,如下图所示:
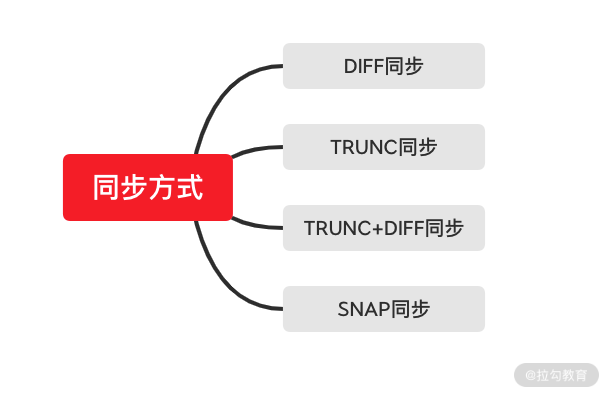
DIFF 同步
DIFF 同步即差异化同步的方式,在 ZooKeeper 集群中,Leader 服务器探测到 Learnning 服务器的存在后,首先会向该 Learnning 服务器发送一个 DIFF 不同指令。在收到该条指令后,Learnning 服务器会进行差异化方式的数据同步操作。在这个过程中,Leader 服务器会将一些 Proposal 发送给 Learnning 服务器。之后 Learnning 服务器在接收到来自 Leader 服务器的 commit 命令后执行数据持久化的操作。
TRUNC+DIFF 同步
TRUNC+DIFF 同步代表先回滚再执行差异化的同步,这种方式一般发生在 Learnning 服务器上存在一条事务性的操作日志,但在集群中的 Leader 服务器上并不存在的情况 。发生这种情况的原因可能是 Leader 服务器已经将事务记录到本地事务日志中,但没有成功发起 Proposal 流程。当这种问题产生的时候,ZooKeeper 集群会首先进行回滚操作,在 Learning 服务器上的数据回滚到与 Leader 服务器上的数据一致的状态后,再进行 DIFF 方式的数据同步操作。
TRUNC 同步
TRUNC 同步是指仅回滚操作,就是将 Learnning 服务器上的操作日志数据回滚到与 Leader 服务器上的操作日志数据一致的状态下。之后并不进行 DIFF 方式的数据同步操作。
SNAP 同步
SNAP 同步的意思是全量同步,是将 Leader 服务器内存中的数据全部同步给 Learnning 服务器。在进行全量同步的过程中,Leader 服务器首先会向 ZooKeeper 集群中的 Learning 服务器发送一个 SNAP 命令,在接收到 SNAP 命令后, ZooKeeper 集群中的 Learning 服务器开始进行全量同步的操作。随后,Leader 服务器会从内存数据库中获取到全量数据节点和会话超时时间记录器,将他们序列化后传输给 Learnning 服务器。Learnning 服务器接收到该全量数据后,会对其反序列化后载入到内存数据库中。
同步后的处理
数据同步的本质就是比对 Leader 服务器与 Learning 服务器,将 Leader 服务器上的数据增加到 Learnning 服务器,再将 Learnning 服务器上多余的事物日志回滚。前面的介绍已经完成了数据的对比与传递操作,接下来就在 Learning 服务器上执行接收到的事物日志,进行本地化的操作。
底层实现
到现在为止,我们已经学习了 ZooKeeper 集群中数据同步的方法,下面我们深入到代码层面来看一下 ZooKeeper 的底层是如何实现的。首先我们来看看 Learnning 服务器是如何接收和判断同步方式的。如下面的代码所示,ZooKeeper 底层实现了一个 Learner 类,该类可以看作是集群中 Learnning 服务器的实例对象,与集群中的 Learning 服务器是一一对应的。
public class Learner {}
而在 Learner 类的内部,主要通过 syncWithLeader 函数来处理来自 Leader 服务器的命令。在接收到来自 Leader 服务器的命令后,通过 qp.getType() 方法判断数据同步的方式。
protected void syncWithLeader(long newLeaderZxid) throws Exception{
if (qp.getType() == Leader.DIFF) {
snapshotNeeded = false;
} else if (qp.getType() == Leader.TRUNC) {
}
}
在确定了数据同步的方式后,再调用 packetsCommitted.add(qp.getZxid()) 方法将事物操作同步到处理队列中,之后调用事物操作线程进行处理。
if (pif.hdr.getZxid() == qp.getZxid() && qp.getType() == Leader.COMMITANDACTIVATE) {
QuorumVerifier qv = self.configFromString(new String(((SetDataTxn) pif.rec).getData()));
boolean majorChange = self.processReconfig(qv, ByteBuffer.wrap(qp.getData()).getLong(),
qp.getZxid(), true);
if (majorChange) {
throw new Exception("changes proposed in reconfig");
}
}
if (!writeToTxnLog) {
if (pif.hdr.getZxid() != qp.getZxid()) {
LOG.warn("Committing " + qp.getZxid() + ", but next proposal is " + pif.hdr.getZxid());
} else {
zk.processTxn(pif.hdr, pif.rec);
packetsNotCommitted.remove();
}
} else {
packetsCommitted.add(qp.getZxid());
结束
我们知道了 ZooKeeper 集群之所以进行数据同步,是为了避免在处理事务性会话请求时,服务器上的数据状态发生变化,最终导致在 ZooKeeper 集群中出现数据不一致的情况。因此,在处理新增数据节点等会话请求的时候,需要在 ZooKeeper 集群中进行数据同步。
而在 ZooKeeper 集群数据同步的过程中,一般采用四种同步方式,这里我们要注意的是 TRUNC+DIFF 这种同步方式,我们上面讲到过,这种同步方式是先回滚数据再同步数据。而回滚到的状态可以看作是删除在 Leader 服务器上不存在的事务性操作记录。
17 集群中 Leader 的作用:事务的请求处理与调度分析
今天这我们还是围绕 Leader 在集群中的作用以及实现原理来进一步探究 Leader 服务器在 ZooKeeper 中的作用,即处理事务性的会话请求以及管理 ZooKeeper 集群中的其他角色服务器。而在接收到来自客户端的事务性会话请求后,ZooKeeper 集群内部又是如何判断会话的请求类型,以及转发处理事务性请求的呢?
事务性请求处理
在 ZooKeeper 集群接收到来自客户端的会话请求操作后,首先会判断该条请求是否是事务性的会话请求。对于事务性的会话请求,ZooKeeper 集群服务端会将该请求统一转发给 Leader 服务器进行操作。通过前面我们讲过的,Leader 服务器内部执行该条事务性的会话请求后,再将数据同步给其他角色服务器,从而保证事务性会话请求的执行顺序,进而保证整个 ZooKeeper 集群的数据一致性。
在 ZooKeeper 集群的内部实现中,是通过什么方法保证所有 ZooKeeper 集群接收到的事务性会话请求都能交给 Leader 服务器进行处理的呢?下面我们就带着这个问题继续学习。
在 ZooKeeper 集群内部,集群中除 Leader 服务器外的其他角色服务器接收到来自客户端的事务性会话请求后,必须将该条会话请求转发给 Leader 服务器进行处理。 ZooKeeper 集群中的 Follow 和 Observer 服务器,都会检查当前接收到的会话请求是否是事务性的请求,如果是事务性的请求,那么就将该请求以 REQUEST 消息类型转发给 Leader 服务器。
在 ZooKeeper集群中的服务器接收到该条消息后,会对该条消息进行解析。分析出该条消息所包含的原始客户端会话请求。之后将该条消息提交到自己的 Leader 服务器请求处理链中,开始进行事务性的会话请求操作。如果不是事务性请求,ZooKeeper 集群则交由 Follow 和 Observer 角色服务器处理该条会话请求,如查询数据节点信息。
Leader 事务处理分析
上面我们介绍了 ZooKeeper 集群在处理事务性会话请求时的内部原理。接下来我们就以客户端发起的创建节点请求 setData 为例,具体看看 ZooKeeper 集群的底层处理过程。
在 ZooKeeper 集群接收到来自客户端的一个 setData 会话请求后,其内部的处理逻辑基本可以分成四个部分。如下图所示,分别是预处理阶段、事务处理阶段、事务执行阶段、响应客户端。
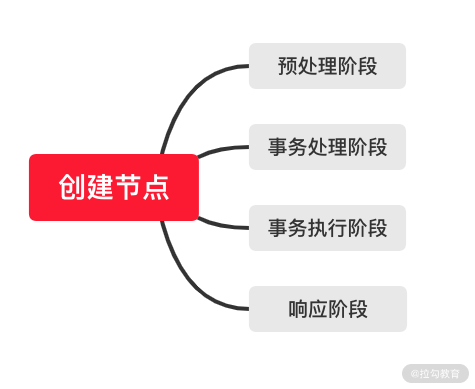
预处理阶段:
在预处理阶段,主要工作是通过网络 I/O 接收来自客户端的会话请求。判断该条会话请求的类型是否是事务性的会话请求,之后将该请求提交给
PrepRequestProcessor 处理器进行处理。封装请求事务头并检查会话是否过期,最后反序列化事务请求信息创建 setDataRequest 请求,在 setDataRequest 记录中包含了要创建数据的节点的路径、数据节点的内容信息以及数据节点的版本信息。最后将该请求存放在 outstandingChanges 队列中等待之后的处理。
事务处理阶段:
在事务处理阶段,ZooKeeper 集群内部会将该条会话请求提交给 ProposalRequestProcessor 处理器进行处理。本阶段内部又分为提交、同步、统计三个步骤。其具体的处理过程我们在之前的课程中已经介绍过了,这里不再赘述。
事务执行阶段:
在经过预处理阶段和事务会话的投票发起等操作后,一个事务性的会话请求都已经准备好了,接下来就是在 ZooKeeper 的数据库中执行该条会话的数据变更操作。
在处理数据变更的过程中,ZooKeeper 内部会将该请求会话的事务头和事务体信息直接交给内存数据库 ZKDatabase 进行事务性的持久化操作。之后返回 ProcessTxnResult 对象表明操作结果是否成功。
响应客户端:
在 ZooKeeper 集群处理完客户端 setData 方法发送的数据节点创建请求后,会将处理结果发送给客户端。而在响应客户端的过程中,ZooKeeper 内部首先会创建一个 setDataResponse 响应体类型,该对象主要包括当前会话请求所创建的数据节点,以及其最新状态字段信息 stat。之后创建请求响应头信息,响应头作为客户端请求响应的重要信息,客户端在接收到 ZooKeeper 集群的响应后,通过解析响应头信息中的事务 ZXID 和请求结果标识符 err 来判断该条会话请求是否成功执行。
事务处理底层实现
介绍完 ZooKeeper 集群处理事务性会话请求的理论方法和内部过程后。接下来我们从代码层面来进一步分析 ZooKeeper 在处理事务性请求时的底层核心代码实现。
首先,ZooKeeper 集群在收到客户端发送的事务性会话请求后,会对该请求进行预处理。在代码层面,ZooKeeper 通过调用 PrepRequestProcessor 类来实现预处理阶段的全部逻辑。可以这样理解:在处理客户端会话请求的时候,首先调用的就是 PrepRequestProcessor 类。而在 PrepRequestProcessor 内部,是通过 pRequest 方法判断客户端发送的会话请求类型。如果是诸如 setData 数据节点创建等事务性的会话请求,就调用 pRequest2Txn 方法进一步处理。
protected void pRequest(Request request){
...
switch (request.type) {
case OpCode.setData:
SetDataRequest setDataRequest = new SetDataRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, setDataRequest, true);
break;
}
}
而在 pRequest2Txn 方法的内部,就实现了预处理阶段的主要逻辑。如下面的代码所示,首先通过 checkSession 方法检查该条会话请求是否有效(比如会话是否过期等),之后调用 checkACL 检查发起会话操作的客户端在 ZooKeeper 服务端是否具有相关操作的权限。最后将该条会话创建的相关信息,诸如 path 节点路径、data 节点数据信息、version 节点版本信息等字段封装成 setDataRequest 类型并传入到 setTxn 方法中,最后加入处理链中进行处理。
case OpCode.setData:
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
SetDataRequest setDataRequest = (SetDataRequest)record;
if(deserialize)
ByteBufferInputStream.byteBuffer2Record(request.request, setDataRequest);
path = setDataRequest.getPath();
validatePath(path, request.sessionId);
nodeRecord = getRecordForPath(path);
checkACL(zks, request.cnxn, nodeRecord.acl, ZooDefs.Perms.WRITE, request.authInfo, path, null);
int newVersion = checkAndIncVersion(nodeRecord.stat.getVersion(), setDataRequest.getVersion(), path);
request.setTxn(new SetDataTxn(path, setDataRequest.getData(), newVersion));
nodeRecord = nodeRecord.duplicate(request.getHdr().getZxid());
nodeRecord.stat.setVersion(newVersion);
addChangeRecord(nodeRecord);
结束
在本课时中,我们主要学习了 ZooKeeper 集群中 Leader 服务器是如何处理事务性的会话请求的,并且在处理完事务性的会话请求后,是如何通知其他角色服务器进行同步操作的。
可以说在 ZooKeeper 集群处理事务性的请过程中,Follow 和 Observer 服务器主要负责接收客户端的会话请求,并转发给 Leader 服务器。而真正处理该条会话请求的是 Leader 服务器。
这就会引发一个问题:当一个业务场景在查询操作多而创建删除等事务性操作少的情况下,ZooKeeper 集群的性能表现的就会很好。而如果是在极端情况下,ZooKeeper 集群只有事务性的会话请求而没有查询操作,那么 Follow 和 Observer 服务器就只能充当一个请求转发服务器的角色, 所有的会话的处理压力都在 Leader 服务器。在处理性能上整个集群服务器的瓶颈取决于 Leader 服务器的性能。ZooKeeper 集群的作用只能保证在 Leader 节点崩溃的时候,重新选举出 Leader 服务器保证系统的稳定性。这也是 ZooKeeper 设计的一个缺点。
18 集群中 Follow 的作用:非事务请求的处理与 Leader 的选举分析
在 ZooKeeper 集群中,Leader 服务器主要负责处理来自客户端的事务性会话请求,并在处理完事务性会话请求后,管理和协调 ZooKeeper 集群中 Follow 和 Observer 等角色服务器的数据同步。因此,在 ZooKeeper 集群中,Leader 服务器是最为核心的服务器,一个 ZooKeeper 服务在集群模式下运行,必须存在一个 Leader 服务器。而在 ZooKeeper 集群中,是通过崩溃选举的方式来保证 ZooKeeper 集群能够一直存在一个 Leader 服务器对外提供服务的。那么在 ZooKeeper 集群选举出 Leader 的过程中,Follow 服务器又做了哪些工作?
对这些问题的研究,有助于我们掌握整个 ZooKeeper 集群服务的运行过程,清楚不同状态下服务器的处理逻辑和相关操作。使我们在日常工作中,更好地开发 ZooKeeper 相关服务,并在运维过程中快速定位问题,搭建更加高效稳定的 ZooKeeper 服务器。
非事务性请求处理过程
在 ZooKeeper 集群接收到来自客户端的请求后,会首先判断该会话请求的类型,如是否是事务性请求。所谓事务性请求,是指 ZooKeeper 服务器执行完该条会话请求后,是否会导致执行该条会话请求的服务器的数据或状态发生改变,进而导致与其他集群中的服务器出现数据不一致的情况。
这里我们以客户端发起的数据节点查询请求为例,分析一下 ZooKeeper 在处理非事务性请求时的实现过程。
当 ZooKeeper 集群接收到来自客户端发送的查询会话请求后,会将该客户端请求分配给 Follow 服务器进行处理。而在 Follow 服务器的内部,也采用了责任链的处理模式来处理来自客户端的每一个会话请求。
在第 12 课时中,我们学习了 Leader 服务器的处理链过程,分别包含预处理器阶段、Proposal 提交处理器阶段以及 final 处理器阶段。与 Leader 处理流程不同的是,在 Follow 角色服务器的处理链执行过程中,FollowerRequestProcessor 作为第一个处理器,主要负责筛选该条会话请求是否是事务性的会话请求。如果是事务性的会话请求,则转发给 Leader 服务器进行操作。如果不是事务性的会话请求,则交由 Follow 服务器处理链上的下一个处理器进行处理。
而下一个处理器是 CommitProcessor ,该处理器的作用是对来自集群中其他服务器的事务性请求和本地服务器的提交请求操作进行匹配。匹配的方式是,将本地执行的 sumbit 提交请求,与集群中其他服务器接收到的 Commit 会话请求进行匹配,匹配完成后再交由 Follow 处理链上的下一个处理器进行处理。最终,当一个客户端会话经过 Final 处理器操作后,就完成了整个 Follow 服务器的会话处理过程,并将结果响应给客户端。
底层实现
简单介绍完 ZooKeeper 集群中 Follow 服务器在处理非事务性请求的过程后,接下来我们再从代码层面分析一下底层的逻辑实现是怎样的。
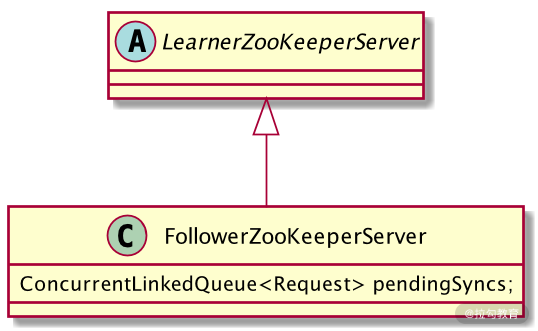
从代码实现的角度讲,ZooKeeper 集群在接收到来自客户端的请求后,会将请求交给 Follow 服务器进行处理。而 Follow 服务器内部首先调用的是 FollowerZooKeeperServer 类,该类的作用是封装 Follow 服务器的属性和行为,你可以把该类当作一台 Follow 服务器的代码抽象。
如下图所示,该 FollowerZooKeeperServer 类继承了 LearnerZooKeeperServer 。在一个 FollowerZooKeeperServer 类内部,定义了一个核心的 ConcurrentLinkedQueue 类型的队列字段,用于存放接收到的会话请求。
在定义了 FollowerZooKeeperServer 类之后,在该类的 setupRequestProcessors 函数中,定义了我们之前一直反复提到的处理责任链,指定了该处理链上的各个处理器。如下面的代码所示,分别按顺序定义了起始处理器 FollowerRequestProcessor 、提交处理器 CommitProcessor、同步处理器 SendAckRequestProcessor 以及最终处理器 FinalProcessor。
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true, getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this,
new SendAckRequestProcessor((Learner)getFollower()));
syncProcessor.start();
选举过程
介绍完 Follow 服务器处理非事务性请求的过程后,接下来我们再学习一下 Follow 服务器的另一个主要的功能:在 Leader 服务器崩溃的时候,重新选举出 Leader 服务器。
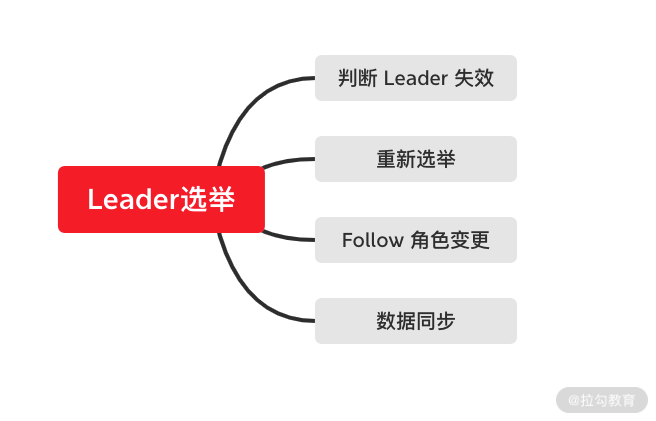
ZooKeeper 集群重新选举 Leader 的过程本质上只有 Follow 服务器参与工作。而在 ZooKeeper 集群重新选举 Leader 节点的过程中,如下图所示。主要可以分为 Leader 失效发现、重新选举 Leader 、Follow 服务器角色变更、集群同步这几个步骤。
Leader 失效发现
通过之前的介绍我们知道,在 ZooKeeper 集群中,当 Leader 服务器失效时,ZooKeeper 集群会重新选举出新的 Leader 服务器。也就是说,Leader 服务器的失效会触发 ZooKeeper 开始新 Leader 服务器的选举,那么在 ZooKeeper 集群中,又是如何发现 Leader 服务器失效的呢?
这里就要介绍到 Leader 失效发现。和我们之前介绍的保持客户端活跃性的方法,它是通过客户端定期向服务器发送 Ping 请求来实现的。在 ZooKeeper 集群中,探测 Leader 服务器是否存活的方式与保持客户端活跃性的方法非常相似。首先,Follow 服务器会定期向 Leader 服务器发送 网络请求,在接收到请求后,Leader 服务器会返回响应数据包给 Follow 服务器,而在 Follow 服务器接收到 Leader 服务器的响应后,如果判断 Leader 服务器运行正常,则继续进行数据同步和服务转发等工作,反之,则进行 Leader 服务器的重新选举操作。
Leader 重新选举
当 Follow 服务器向 Leader 服务器发送状态请求包后,如果没有得到 Leader 服务器的返回信息,这时,如果是集群中个别的 Follow 服务器发现返回错误,并不会导致 ZooKeeper 集群立刻重新选举 Leader 服务器,而是将该 Follow 服务器的状态变更为 LOOKING 状态,并向网络中发起投票,当 ZooKeeper 集群中有更多的机器发起投票,最后当投票结果满足多数原则的情况下。ZooKeeper 会重新选举出 Leader 服务器。
Follow 角色变更
在 ZooKeeper 集群中,Follow 服务器作为 Leader 服务器的候选者,当被选举为 Leader 服务器之后,其在 ZooKeeper 集群中的 Follow 角色,也随之发生改变。也就是要转变为 Leader 服务器,并作为 ZooKeeper 集群中的 Leader 角色服务器对外提供服务。
集群同步数据
在 ZooKeeper 集群成功选举 Leader 服务器,并且候选 Follow 服务器的角色变更后。为避免在这期间导致的数据不一致问题,ZooKeeper 集群在对外提供服务之前,会通过 Leader 角色服务器管理同步其他角色服务器,具体的数据同步方法,我们在第14课时中已经详细的讲解过了,这里不再赘述。
底层实现
介绍完 ZooKeeper 集群重新选举 Leader 服务器的理论方法后,接下来我们再来分析代码层面上 ZooKeeper 的核心实现。
首先,ZooKeeper 集群会先判断 Leader 服务器是否失效,而判断的方式就是 Follow 服务器向 Leader 服务器发送请求包,之后 Follow 服务器接收到响应数据后,进行解析,如下面的代码所示,Follow 服务器会根据返回的数据,判断 Leader 服务器的运行状态,如果返回的是 LOOKING 关键字,表明与集群中 Leader 服务器无法正常通信。
switch (rstate) {
case 0:
ackstate = QuorumPeer.ServerState.LOOKING;
break;
case 1:
ackstate = QuorumPeer.ServerState.FOLLOWING;
break;
case 2:
ackstate = QuorumPeer.ServerState.LEADING;
break;
case 3:
ackstate = QuorumPeer.ServerState.OBSERVING;
break;
default:
continue;
之后,在 ZooKeeper 集群选举 Leader 服务器时,是通过 FastLeaderElection 类实现的。该类实现了 TCP 方式的通信连接,用于在 ZooKeeper 集群中与其他 Follow 服务器进行协调沟通。
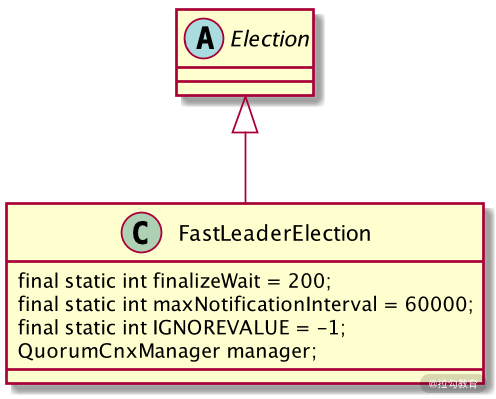
如上图所示,FastLeaderElection 类继承了 Election 接口,定义其是用来进行选举的实现类。而在其内部,又定义了选举通信相关的一些配置参数,比如 finalizeWait 最终等待时间、最大通知间隔时间 maxNotificationInterval 等。
在选举的过程中,首先调用 ToSend 函数向 ZooKeeper 集群中的其他角色服务器发送本机的投票信息,其他服务器在接收投票信息后,会对投票信息进行有效性验证等操作,之后 ZooKeeper 集群统计投票信息,如果过半数的机器投票信息一致,则集群就重新选出新的 Leader 服务器。
static public class ToSend {
static enum mType {crequest, challenge, notification, ack}
ToSend(mType type,
long leader,
long zxid,
long electionEpoch,
ServerState state,
long sid,
long peerEpoch,
byte[] configData) {
this.leader = leader;
this.zxid = zxid;
this.electionEpoch = electionEpoch;
this.state = state;
this.sid = sid;
this.peerEpoch = peerEpoch;
this.configData = configData;
}
结束
通过本课时的学习,我们知道在 ZooKeeper 集群中 Follow 服务器的功能和作用。Follow 服务器在 ZooKeeper 集群服务运行的过程中,负责处理来自客户端的查询等非事务性的请求操作。当 ZooKeeper 集群中旧的 Leader 服务器失效时,作为投票者重新选举出新的 Leader 服务器。
这里我们要注意一个问题,那就是在重新选举 Leader 服务器的过程中,ZooKeeper 集群理论上是无法进行事务性的请求处理的。因此,发送到 ZooKeeper 集群中的事务性会话会被挂起,暂时不执行,等到选举出新的 Leader 服务器后再进行操作。
19 Observer 的作用与 Follow 有哪些不同?
在 ZooKeeper 集群服务运行的过程中,Follow 服务器主要负责处理来自客户端的非事务性请求,其中大部分是处理客户端发起的查询会话等请求。而在 ZooKeeper 集群中,Leader 服务器失效时,会在 Follow 集群服务器之间发起投票,最终选举出一个 Follow 服务器作为新的 Leader 服务器。
除了 Leader 和 Follow 服务器,ZooKeeper 集群中还有一个 Observer 服务器。在 ZooKeeper 集群中,Observer 服务器对于提升整个 ZooKeeper 集群运行的性能具有至关重要的作用。而本课时,我们就开始学习什么是 Observer 服务器,以及它在 ZooKeeper 集群中都做了哪些工作。
Observer 介绍
在 ZooKeeper 集群服务运行的过程中,Observer 服务器与 Follow 服务器具有一个相同的功能,那就是负责处理来自客户端的诸如查询数据节点等非事务性的会话请求操作。但与 Follow 服务器不同的是,Observer 不参与 Leader 服务器的选举工作,也不会被选举为 Leader 服务器。
在前面的课程中,我们或多或少有涉及 Observer 服务器,当时我们把 Follow 服务器和 Observer 服务器统称为 Learner 服务器。你可能会觉得疑惑,Observer 服务器做的事情几乎和 Follow 服务器一样,那么为什么 ZooKeeper 还要创建一个 Observer 角色服务器呢?
要想解释这个问题,就要从 ZooKeeper 技术的发展过程说起,最早的 ZooKeeper 框架如下图所示,可以看到,其中是不存在 Observer 服务器的。
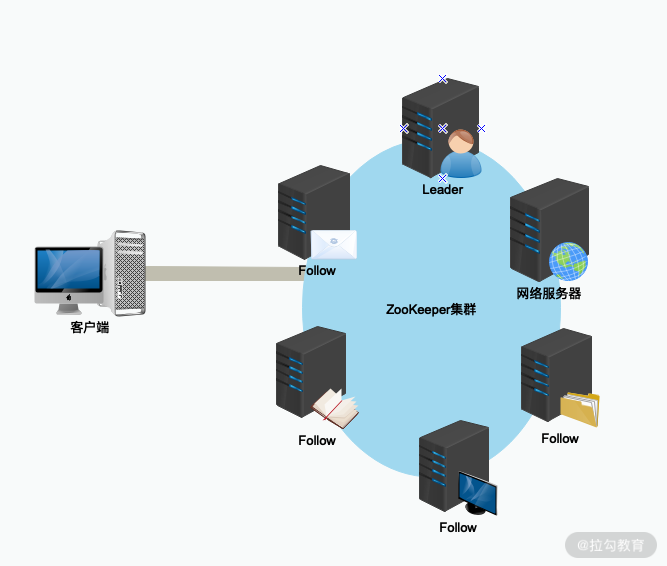
在早期的 ZooKeeper 集群服务运行过程中,只有 Leader 服务器和 Follow 服务器。不过随着 ZooKeeper 在分布式环境下的广泛应用,早期模式的设计缺点也随之产生,主要带来的问题有如下几点:
- 随着集群规模的变大,集群处理写入的性能反而下降。
- ZooKeeper 集群无法做到跨域部署。
其中最主要的问题在于,当 ZooKeeper 集群的规模变大,集群中 Follow 服务器数量逐渐增多的时候,ZooKeeper 处理创建数据节点等事务性请求操作的性能就会逐渐下降。这是因为 ZooKeeper 集群在处理事务性请求操作时,要在 ZooKeeper 集群中对该事务性的请求发起投票,只有超过半数的 Follow 服务器投票一致,才会执行该条写入操作。
正因如此,随着集群中 Follow 服务器的数量越来越多,一次写入等相关操作的投票也就变得越来越复杂,并且 Follow 服务器之间彼此的网络通信也变得越来越耗时,导致随着 Follow 服务器数量的逐步增加,事务性的处理性能反而变得越来越低。
为了解决这一问题,在 ZooKeeper 3.6 版本后,ZooKeeper 集群中创建了一种新的服务器角色,即 Observer——观察者角色服务器。Observer 可以处理 ZooKeeper 集群中的非事务性请求,并且不参与 Leader 节点等投票相关的操作。这样既保证了 ZooKeeper 集群性能的扩展性,又避免了因为过多的服务器参与投票相关的操作而影响 ZooKeeper 集群处理事务性会话请求的能力。
在引入 Observer 角色服务器后,一个 ZooKeeper 集群服务在部署的拓扑结构,如下图所示:
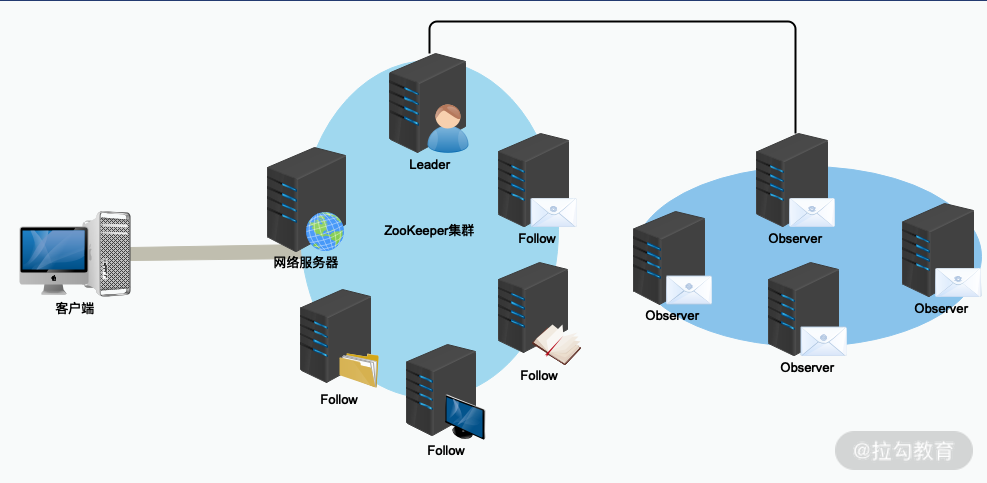
在实际部署的时候,因为 Observer 不参与 Leader 节点等操作,并不会像 Follow 服务器那样频繁的与 Leader 服务器进行通信。因此,可以将 Observer 服务器部署在不同的网络区间中,这样也不会影响整个 ZooKeeper 集群的性能,也就是所谓的跨域部署。
底层实现
介绍完 Observer 的作用和原理后,接下来我们再从底层代码的角度去分析一下 ZooKeeper 是如何实现一个 Observer 服务器的。
首先,在我们平时开发 ZooKeeper 服务的时候,如果想让某个服务器以 Observer 角色运行,需要在该服务器的运行配置文件 zoo.cfg 文件中添加 peerType 属性。如下面的代码所示,将该服务器的 peerType 属性设置为 observer 。
peerType=observer
而当 ZooKeeper 集群服务开始运行的时候,首先调用 ObserverZooKeeperServer 类,来实例化 ZooKeeper 集群中每个 Observer 服务器,并初始化调用链等相关操作。如下面的代码所示:
ObserverZooKeeperServer(FileTxnSnapLog logFactory, QuorumPeer self, ZKDatabase zkDb) throws IOException {
super(logFactory, self.tickTime, self.minSessionTimeout, self.maxSessionTimeout, zkDb, self);
LOG.info("syncEnabled =" + syncRequestProcessorEnabled);
而在 ObserverZooKeeperServer 类的 commitRequest 函数中,就设置了与 Follow 角色不同的实现方式。如下面的代码所示,Observer 不会接收网络中的 Proposal 请求,不会像 Follow 一样,在 Proposal 阶段就获得 Leader 服务器发送的变更数据。Observer 服务器是从 INFORM 数据包中获得变更的数据,在 commitRequest 函数的内部实现中,提交执行来自 INFORM 数据包中的事务操作。
public void commitRequest(Request request) {
if (syncRequestProcessorEnabled) {
// Write to txnlog and take periodic snapshot
syncProcessor.processRequest(request);
}
commitProcessor.commit(request);
INFORM 消息
了解 Observer 服务器的底层实现过程后,我们再来介绍一下 INFORM 消息。Observer 不会接收来自 Leader 服务器提交的投票请求,且不会接收网络中的 Proposal 请求信息,只会从网络中接收 INFORM 类型的信息包。
而 INFORM 信息的内部只包含已经被 Cmmit 操作过的投票信息,因为 Observer 服务器只接收已经被提交处理的 Proposal 请求,不会接收未被提交的会话请求。这样就从底层信息的角度隔离了 Observer 参与投票操作,进而使 Observer 只负责查询等相关非事务性操作,保证扩展多个 Observer 服务器时不会对 ZooKeeper 集群写入操作的性能产生影响。
Observer 处理链
接下来,我们再来看一下 Observer 服务器处理一次会话请求的底层实现过程。与 Leader 和 Follow 服务器一样,在处理一条来自客户单的会话请求时, Observer 同样采用的是处理链的设计方式。在这个 Observer 处理链上,主要定义了三个处理器,处理器的执行顺序分别是 ObserverRequestProcessor 处理器、CommitProcessor 处理器以及 FinalRequestProcessor 处理器。
在 ObserverRequestProcessor 处理器中,首先判断客户端请求的会话类型,将所有事务性的会话请求交给 Leader 服务器处理,如下面的代码所示。
public void run() {
try {
while (!finished) {
Request request = queuedRequests.take();
...
switch (request.type) {
case OpCode.sync:
zks.pendingSyncs.add(request);
zks.getObserver().request(request);
break;
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
zks.getObserver().request(request);
break;
...
}
}
...
}
}
之后调用 CommitProcessor 处理器,将该条会话放入到 queuedRequests 请求等待队列中。并唤醒相关线程进行会话处理。queuedRequests 队列实现了 BlockingQueue 阻塞队列:当 queuedRequests 队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。 这就形成了一个消费者—生产者模式的处理方式。
public void processRequest(Request request) {
if (stopped) {
return;
}
if (LOG.isDebugEnabled()) {
LOG.debug("Processing request:: " + request);
}
queuedRequests.add(request);
wakeup();
}
在将会话请求放入到等待处理队列后,CommitProcessor 处理器的 run 方法从该队列中取出要处理的会话请求,然后解析会话请求中的请求服务器 zxid、请求事务信息 txn、请求头信息 hdr 等,并封装成 requeset 对象,然后传递给下一个处理器 FinalRequestProcessor。FinalRequestProcessor 处理器中会根据请求的类型,最终执行相关的操作。
结束
我们学习了在 ZooKeeper 集群服务运行过程中 Observer 服务器的作用和功能。
与 Follow 服务器一样,他们都可以处理 ZooKeeper 集群中的非事务性会话请求,不同之处在于,Observer 不参与 ZooKeeper 集群中 Leader 服务器的选举以及事务性会话处理的投票工作。
这里给你留一个思考题:利用 Observer 服务器的这一特性,在平时的生产环境中,我们可以采用什么样的方式,来提高 ZooKeeper 集群服务的性能呢?所谓的跨域部署最常见的就是将 ZooKeeper 集群中的物理机器部署在不同的地域或机房中。
20 一个运行中的 ZooKeeper 服务会产生哪些数据和文件?
之前的课程我们都在介绍 ZooKeeper 框架能够实现的功能,而无论是什么程序,其本质就是对数据的操作。比如 MySQl 数据库操作的是数据表,Redis 数据库操作的是存储在内存中的 Key-Value 值。不同的数据格式和存储方式对系统运行的效率和处理能力都有很大影响。本课时就来学习,在 ZooKeeper 程序运行期间,都会处理哪些数据,以及他们的存储格式和存储位置。
ZooKeeper 服务提供了创建节点、添加 Watcher 监控机制、集群服务等丰富的功能。这些功能服务的实现,离不开底层数据的支持。从数据存储地点角度讲,ZooKeeper 服务产生的数据可以分为内存数据和磁盘数据。而从数据的种类和作用上来说,又可以分为事务日志数据和数据快照数据。
内存数据
首先,我们介绍一下什么是内存数据。在专栏的基础篇中,主要讲解了通过 ZooKeeper 数据节点的特性,来实现一些像发布订阅这样的功能。而这些数据节点实际上就是 ZooKeeper 在服务运行过程中所操作的数据。
我在基础篇中提到过,ZooKeeper 的数据模型可以看作一棵树形结构,而数据节点就是这棵树上的叶子节点。从数据存储的角度看,ZooKeeper 的数据模型是存储在内存中的。我们可以把 ZooKeeper 的数据模型看作是存储在内存中的数据库,而这个数据库不但存储数据的节点信息,还存储每个数据节点的 ACL 权限信息以及 stat 状态信息等。
而在底层实现中,ZooKeeper 数据模型是通过 DataTree 类来定义的。如下面的代码所示,DataTree 类定义了一个 ZooKeeper 数据的内存结构。DataTree 的内部定义类 nodes 节点类型、root 根节点信息、子节点的 WatchManager 监控信息等数据模型中的相关信息。可以说,一个 DataTree 类定义了 ZooKeeper 内存数据的逻辑结构。
public class DataTree {
private DataNode root
private final WatchManager dataWatches
private final WatchManager childWatches
private static final String rootZookeeper = "/";
}
事务日志
在介绍 ZooKeeper 集群服务的时候,我们介绍过,为了整个 ZooKeeper 集群中数据的一致性,Leader 服务器会向 ZooKeeper 集群中的其他角色服务发送数据同步信息,在接收到数据同步信息后, ZooKeeper 集群中的 Follow 和 Observer 服务器就会进行数据同步。而这两种角色服务器所接收到的信息就是 Leader 服务器的事务日志。在接收到事务日志后,并在本地服务器上执行。这种数据同步的方式,避免了直接使用实际的业务数据,减少了网络传输的开销,提升了整个 ZooKeeper 集群的执行性能。
在我们启动一个 ZooKeeper 服务器之前,首先要创建一个 zoo.cfg 文件并进行相关配置,其中有一项配置就是 dataLogDir 。在这项配置中,我们会指定该台 ZooKeeper 服务器事务日志的存放位置。
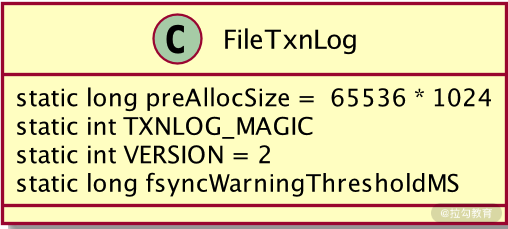
在 ZooKeeper 服务的底层实现中,是通过 FileTxnLog 类来实现事务日志的底层操作的。如下图代码所示,在 FileTxnLog 类中定义了一些属性字段,分别是:
- preAllocSize:可存储的日志文件大小。如用户不进行特殊设置,默认的大小为 65536*1024 字节。
- TXNLOG_MAGIC:设置日志文件的魔数信息为ZKLG。
- VERSION:设置日志文件的版本信息。
- lastZxidSeen:最后一次更新日志得到的 ZXID。
定义了事务日志操作的相关指标参数后,在 FileTxnLog 类中调用 static 静态代码块,来将这些配置参数进行初始化。比如读取 preAllocSize 参数分配给日志文件的空间大小等操作。
static {
LOG = LoggerFactory.getLogger(FileTxnLog.class);
String size = System.getProperty("zookeeper.preAllocSize");
if (size != null) {
try {
preAllocSize = Long.parseLong(size) * 1024;
} catch (NumberFormatException e) {
LOG.warn(size + " is not a valid value for preAllocSize");
}
}
Long fsyncWarningThreshold;
if ((fsyncWarningThreshold = Long.getLong("zookeeper.fsync.warningthresholdms")) == null)
fsyncWarningThreshold = Long.getLong("fsync.warningthresholdms", 1000);
fsyncWarningThresholdMS = fsyncWarningThreshold;
经过参数定义和日志文件的初始化创建后,在 ZooKeeper 服务器的 dataDir 路径下就生成了一个用于存储事务性操作的日志文件。我们知道在 ZooKeeper 服务运行过程中,会不断地接收和处理来自客户端的事务性会话请求,这就要求每次在处理事务性请求的时候,都要记录这些信息到事务日志中。
如下面的代码所示,在 FileTxnLog 类中,实现记录事务操作的核心方法是 append。从方法的命名中可以看出,ZooKeeper 采用末尾追加的方式来维护新的事务日志数据到日志文件中。append 方法首先会解析事务请求的头信息,并根据解析出来的 zxid 字段作为事务日志的文件名,之后设置日志的文件头信息 magic、version、dbid 以及日志文件的大小 。
public synchronized boolean append(TxnHeader hdr, Record txn) throws IOException
{
if (hdr == null) {
return false;
}
if (hdr.getZxid() <= lastZxidSeen) {
LOG.warn("Current zxid " + hdr.getZxid()
+ " is <= " + lastZxidSeen + " for "
+ hdr.getType());
} else {
lastZxidSeen = hdr.getZxid();
}
if (logStream==null) {
if(LOG.isInfoEnabled()){
LOG.info("Creating new log file: log." + Long.toHexString(hdr.getZxid()));
}
logFileWrite = new File(logDir, ("log." + Long.toHexString(hdr.getZxid())));
fos = new FileOutputStream(logFileWrite);
logStream=new BufferedOutputStream(fos);
oa = BinaryOutputArchive.getArchive(logStream);
FileHeader fhdr = new FileHeader(TXNLOG_MAGIC,VERSION, dbId);
fhdr.serialize(oa, "fileheader");
// Make sure that the magic number is written before padding.
logStream.flush();
currentSize = fos.getChannel().position();
streamsToFlush.add(fos);
}
padFile(fos);
byte[] buf = Util.marshallTxnEntry(hdr, txn);
if (buf == null || buf.length == 0) {
throw new IOException("Faulty serialization for header " + "and txn");
}
Checksum crc = makeChecksumAlgorithm();
crc.update(buf, 0, buf.length);
oa.writeLong(crc.getValue(), "txnEntryCRC");
Util.writeTxnBytes(oa, buf);
return true;
从对事务日志的底底层代码分析中可以看出,在 datadir 配置参数路径下存放着 ZooKeeper 服务器所有的事务日志,所有事务日志的命名方法都是“log.+ 该条事务会话的 zxid”。
数据快照
最后,我们来介绍 ZooKeeper 服务运行过程中产生的最后一个数据文件,即事务快照。
说到快照,可能很多技术人员都不陌生。一个快照可以看作是当前系统或软件服务运行状态和数据的副本。在 ZooKeeper 中,数据快照的作用是将内存数据结构存储到本地磁盘中。因此,从设计的角度说,数据快照与内存数据的逻辑结构一样,都使用 DataTree 结构。在 ZooKeeper 服务运行的过程中,数据快照每间隔一段时间,就会把 ZooKeeper 内存中的数据存储到磁盘中,快照文件是间隔一段时间后对内存数据的备份。
因此,与内存数据相比,快照文件的数据具有滞后性。而与上面介绍的事务日志文件一样,在创建数据快照文件时,也是使用 zxid 作为文件名称。
在代码层面,ZooKeeper 通过 FileTxnSnapLog 类来实现数据快照的相关功能。如下图所示,在FileTxnSnapLog 类的内部,最核心的方法是 save 方法,在 save 方法的内部,首先会创建数据快照文件,之后调用 FileSnap 类对内存数据进行序列化,并写入到快照文件中。
public void save(DataTree dataTree,
ConcurrentHashMap<Long, Integer> sessionsWithTimeouts,
boolean syncSnap)
throws IOException {
long lastZxid = dataTree.lastProcessedZxid;
File snapshotFile = new File(snapDir, Util.makeSnapshotName(lastZxid));
LOG.info("Snapshotting: 0x{} to {}", Long.toHexString(lastZxid),
snapshotFile);
snapLog.serialize(dataTree, sessionsWithTimeouts, snapshotFile, syncSnap);
}
总结
通过本课时的学习,我们知道在 ZooKeeper 服务的运行过程中,会涉及内存数据、事务日志、数据快照这三种数据文件。从存储位置上来说,事务日志和数据快照一样,都存储在本地磁盘上;而从业务角度来讲,内存数据就是我们创建数据节点、添加监控等请求时直接操作的数据。事务日志数据主要用于记录本地事务性会话操作,用于 ZooKeeper 集群服务器之间的数据同步。事务快照则是将内存数据持久化到本地磁盘。
这里要注意的一点是,数据快照是每间隔一段时间才把内存数据存储到本地磁盘,因此数据并不会一直与内存数据保持一致。在单台 ZooKeeper 服务器运行过程中因为异常而关闭时,可能会出现数据丢失等情况。

















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









