




 本文围绕多字符编码和Unicode编码展开。介绍了c++中char和wchar_t的区别,以及string和wstring的特点与转换方法。还讲解了L、_T、_TEXT的区别,说明了字符集和字符编码相关内容。此外,提及vs编写通信代码的编码注意点及vs2017修改编码的方法。
本文围绕多字符编码和Unicode编码展开。介绍了c++中char和wchar_t的区别,以及string和wstring的特点与转换方法。还讲解了L、_T、_TEXT的区别,说明了字符集和字符编码相关内容。此外,提及vs编写通信代码的编码注意点及vs2017修改编码的方法。
多字符编码 和 Unicode编码
一 多字符编码 和 Unicode 编码的区别
c++ 基本数据类型中表示字符有两种:char wchar_t
char 叫多字节字符,一个char占一个字节,之所以叫多字节字符是因为它表示一个字时可能是一个字节也可能是多个字节。一个英文字符(如’s’)用一个char(一个字节)表示,一个中文汉字(如’中’)用3个char(三个字节)表示
wchar_t被称为宽字符,一个wchar_t占2个字节。之所以叫宽字符是因为所有的字都要用两个字节(即一个wchar_t)来表示,不管是英文还是中文
string与wstring
字符数组可以表示一个字符串,但它是一个定长的字符串,我们在使用之前必须知道这个数组的长度。为方便字符串的操作,STL为我们定义好了字符串的类string和wstring。大家对string肯定不陌生,但wstring可能就用的少了。
string是普通的多字节版本,是基于char的,对char数组进行的一种封装。
wstring是Unicode版本,是基于wchar_t的,对wchar_t数组进行的一种封装
二 string 和 wstring 转换
1 跨平台方法
#include <cstdlib>
#include <string.h>
#include <st// wstring => string
std::string WString2String(const std::wstring& ws)
{
std::string strLocale = setlocale(LC_ALL, "");
const wchar_t* wchSrc = ws.c_str();
size_t nDestSize = wcstombs(NULL, wchSrc, 0) + 1;
char *chDest = new char[nDestSize];
memset(chDest,0,nDestSize);
wcstombs(chDest,wchSrc,nDestSize);
std::string strResult = chDest;
delete []chDest;
setlocale(LC_ALL, strLocale.c_str());
return strResult;
}
// string => wstring
std::wstring String2WString(const std::string& s)
{
std::string strLocale = setlocale(LC_ALL, "");
const char* chSrc = s.c_str();
size_t nDestSize = mbstowcs(NULL, chSrc, 0) + 1;
wchar_t* wchDest = new wchar_t[nDestSize];
wmemset(wchDest, 0, nDestSize);
mbstowcs(wchDest,chSrc,nDestSize);
std::wstring wstrResult = wchDest;
delete []wchDest;
setlocale(LC_ALL, strLocale.c_str());
return wstrResult;
}
2 windows wstirng 转 string
static std::string ws2s(const std::wstring& ws)
{
_bstr_t t = ws.c_str();
char* pchar = (char*)t;
std::string result = pchar;
return result;
}
3 MFC Cstring 转 string
static std::string CString2string(CString csStrData)
{
int n = csStrData.GetLength();
int len = WideCharToMultiByte(CP_ACP, 0, csStrData, csStrData.GetLength(), NULL, 0, NULL, NULL);
char * pData = new char[len + 1];
WideCharToMultiByte(CP_ACP, 0, csStrData, csStrData.GetLength()+1, pData, len+1, NULL, NULL);
pData[len+1] = '\0';
return pData;
}
三 多字符编码 和 Unicode 编码 相关知识
1 L , _T, _TEXT 区别
(1 ) L
字符串(literal string)前面的大写字母L,用来告诉编译器该字符串应该作为Unicode来编译。它用来将ASNI转换为Unicode,Unicode字符串中每个字符占16位(两个字节),而在ASNI中每个字符占用一个字节。
(2)_T、_TEXT 效果相同
_T是一个宏,如果项目使用了Unicode字符集(定义了UNICODE宏),则自动在字符串前面加上L,否则字符串不变。Visual C++里边定义字符串的时候,用_T来保证兼容性。VC支持ascii和unicode两种字符类型,用_T可以保证从ascii编码类型转换到unicode编码类型的时候,程序不需要修改
tchar.h中定义如下:
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
#ifdef _UNICODE
#define __T(x) L ## x
#else
#define __T(x) x
#endif
2 相关变量总结:
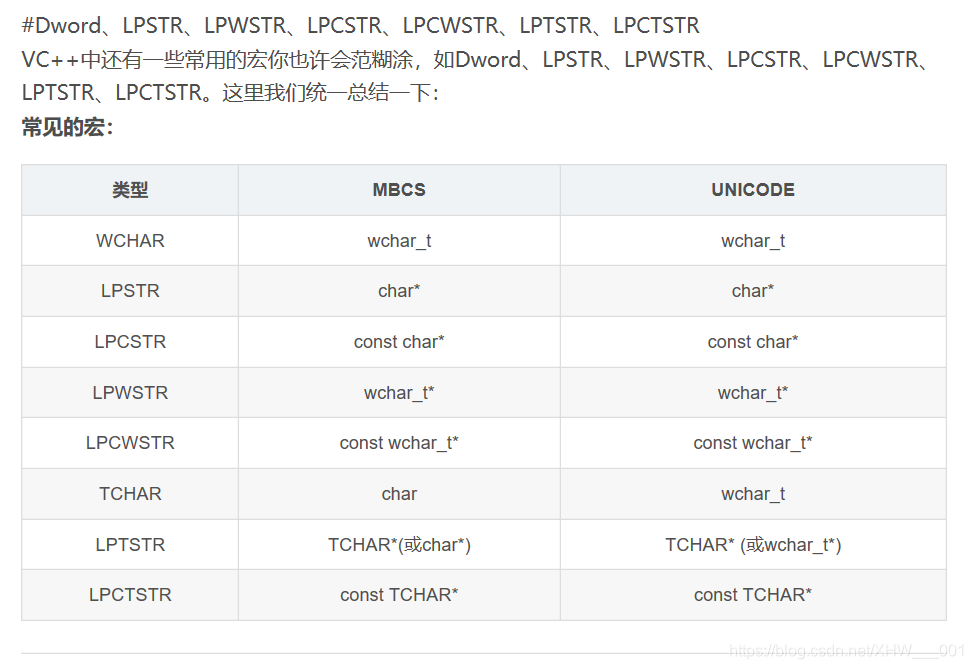
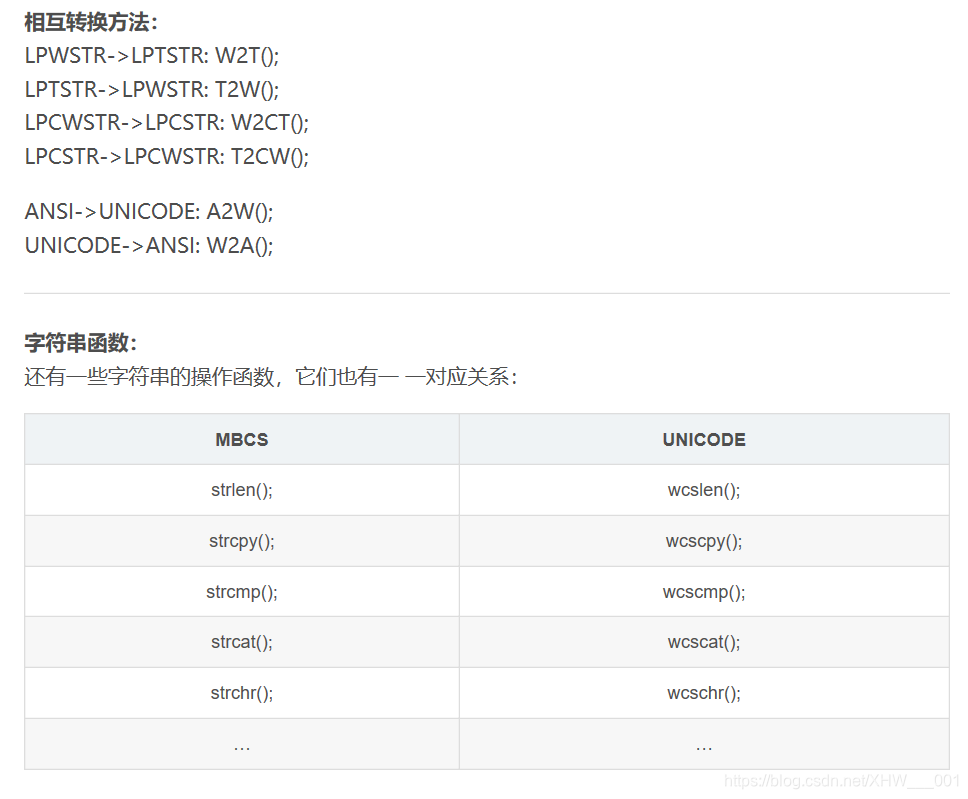
四字符集和字符编码说明
参考文档:
https://blog.youkuaiyun.com/youxishaonian/article/details/70312438
https://blog.youkuaiyun.com/luoweifu/article/details/49382969
https://blog.youkuaiyun.com/luoweifu/article/details/49385121
五 其他
1 vs 编写通信代码注意点
在编写通信程序中, 通信内容要求utf-8格式。 需要产看一下vs输出的编码格式, 如果是gb2312格式,则需要将汉字转换成utf-8格式
1 gb2312 转 utf-8
wstatic char* G2U (const char* gb2312)
{
int len = MultiByteToWideChar(CP_ACP, 0, gb2312, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_ACP, 0, gb2312, -1, wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, str, len, NULL, NULL);
if (wstr) delete[] wstr;
return str;
}
2 utf-8 转 gb2312
char* U2G(const char* utf8)
{
int len = MultiByteToWideChar(CP_UTF8, 0, utf8, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len+1];
memset(wstr, 0, len+1);
MultiByteToWideChar(CP_UTF8, 0, utf8, -1, wstr, len);
len = WideCharToMultiByte(CP_ACP, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len+1];
memset(str, 0, len+1);
WideCharToMultiByte(CP_ACP, 0, wstr, -1, str, len, NULL, NULL);
if(wstr) delete[] wstr;
return str;
}
2 vs2017 可修改编码 方法如下:
https://blog.youkuaiyun.com/yanchenyu365/article/details/86615433

















 5213
5213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









