



 本文介绍了循环神经网络(RNN)中的SimpleRNN和LSTM在处理阅读理解任务中的应用,强调了SimpleRNN的序列记忆能力和LSTM对长序列问题的改进,特别是通过遗忘门机制解决梯度爆炸和信息丢失的问题。
本文介绍了循环神经网络(RNN)中的SimpleRNN和LSTM在处理阅读理解任务中的应用,强调了SimpleRNN的序列记忆能力和LSTM对长序列问题的改进,特别是通过遗忘门机制解决梯度爆炸和信息丢失的问题。
1、循环神经网络 RNN
在做阅读的时候,我们时常需要通过上文来关联看现在段落的意思。循环神经网络就是这样,与其他网络相比最大特定就是在内部保存了一个状态,其中包含了已经查看过的内容相关信息。
2、SimpleRNN
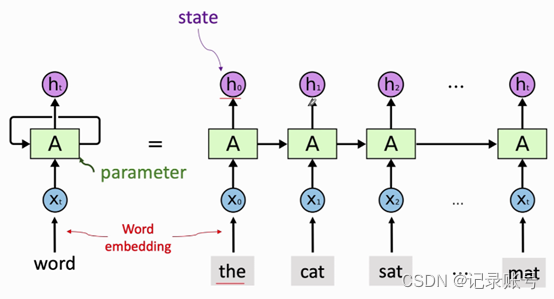
三个参数,batch_size(batch数据),timesteps(序列长度),词向量维度(输出的维度)
outputt = tanh( (W * Xt) + (U * ht-1) + bias )
最终输出的状态h5是包含了前面输入的所有状态,即整个序列信息。
3、RNN
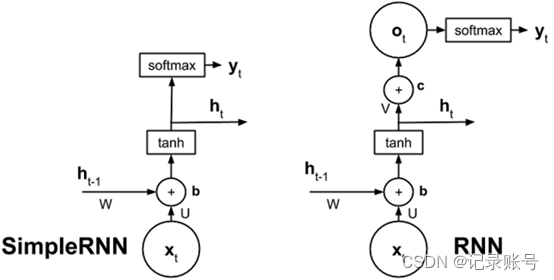
相比于SimpleRNN简化了输出计算步骤,实际的RNN有多一步计算。
4、SimpleRNN的局限性
是可以处理序列或者是时序数据,每个最后输出的h都包含了t时刻前的所有输入信息,但是局限性就在与管理长序列的能力有限。
若是长序列,用SimpleRNN会导致:
1.梯度爆炸和消失:因为过长,在反向传播的时候,越靠近顶层梯度越小,会导致速度变慢,甚至停止学习。
2.忘记最早的输入消息:同比问题一,顶层越小信息越少。
5、LSTM
长短记忆
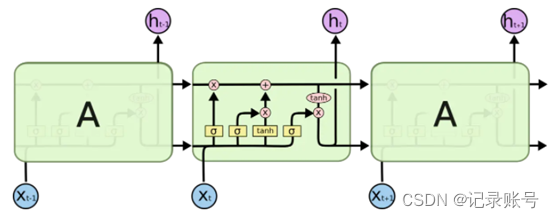
LSTM也属于RNN中的一种,所以输入的数据跟前面的一样,时序或者序列数据。在t时间的输入也是Xt,输出为状态Ht。但是结果比SimpleRNN复杂的多,有四个矩阵。最重要的是有一个传输带向量C,过去的信息可以通过传输带向量送到下一个时刻,并且不会发生太大的变化。这样可以解决梯度过高的问题。
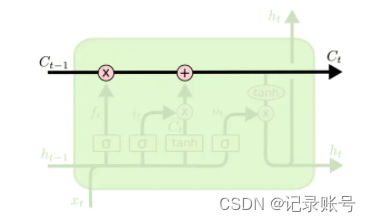
在LSTM里有几种类型的门(Gate),用来控制传输带向量C的状态。
5.1、ForgetGate
遗忘门
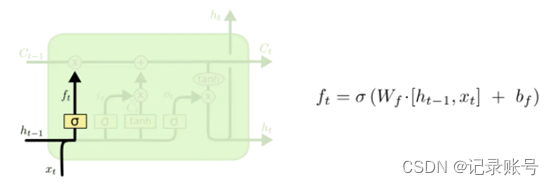
遗忘门是将输入Xt与上一个状态Ht-1 进行concatenate合并后,与Forget Gate参数矩阵Wf进行矩阵乘法,加上偏移量Bf。经过激活函数sigmoid函数进行处理,得出Ft。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









