



 本文介绍了哈希表的概念、工作原理,以及为何需要哈希表。重点讨论了哈希函数的作用、哈希碰撞及其解决方法,如开放地址法(线性探测法)和链地址法。
本文介绍了哈希表的概念、工作原理,以及为何需要哈希表。重点讨论了哈希函数的作用、哈希碰撞及其解决方法,如开放地址法(线性探测法)和链地址法。
哈希表
哈希表是什么
下面是百度百科上对哈希表的介绍:
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
下面是《数据结构 C语言版 第二版》书中关于哈希表(散列表)的描述:
如果能在元素的存储位置和其关键字之间建立某种直接关系,那么在进行查找时,就无须作比较或只需要很少的比较,按照这种关系直接由关键字找到相应的记录。这就是散列查找法的思想,它通过对元素的关键字值进行某种运算,直接求出元素的地址,即使用关键字到地址的直接转换方法,而不需要反复比较。
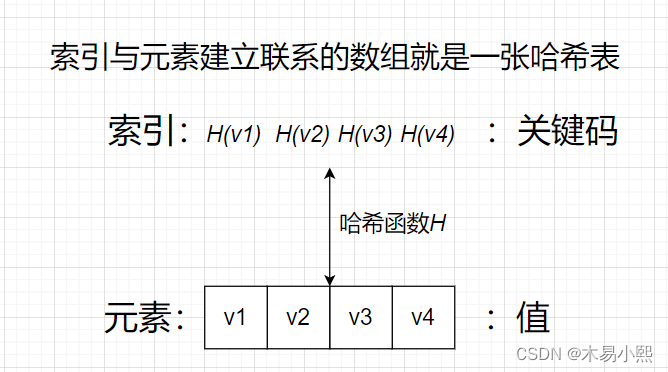
用通俗的话讲就是:哈希表是数组的一种扩展,哈希表中存储的元素和数组的索引有一个确定的关系,我们将这个确定的关系称之为哈希函数(Hash)。
“数组是一张哈希表”,我在很多地方看到了这个观点。
我认为不够严谨,因为数组的索引与存储的元素不一定有确定的关系。
哈希表中关键码对应数组下标,通过下标直接访问数组中的元素。
为什么需要哈希表
哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现在集合里
线性表、树表结构的查找方法都是以关键字的比较为基础的。在查找过程中只考虑各元素关键字之间的相对大小,记录在存储结构中的位置和其关键字无直接关系,其查找时间与表的长度有关,特别是当节点个数很多时,查找需要大量的无效节点的关键字进行比较,致使查找速度很慢
下面给出哈希法中常用的几个术语
1.哈希函数和哈希地址:在记录的存储位置p和其关键字key之间建立一个确定的对应关系H,使p=H(key),称这个对应关系H为哈希函数,p为哈希地址
2. 哈希表:一个有限连续的地址空间,用以储存按哈希函数计算得到相应哈希地址的数据记录。通常哈希表的存储空间是一个一维数组,哈希地址使数组的下标
3. 哈希碰撞和同义词:对不同的关键字可能得到同一哈希地址,即key1 ≠ key2 ,而 H(key1)=H(key2) 。这种现象称为冲突。具有相同函数值的关键字对该哈希函数来说称作同义词,key1与key2互为同义词
哈希函数
哈希函数,把value直接映射到哈希表的索引上,然后就可以通过查询索引快速知道这个value是否存在。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把value映射为哈希表上的索引数字了。
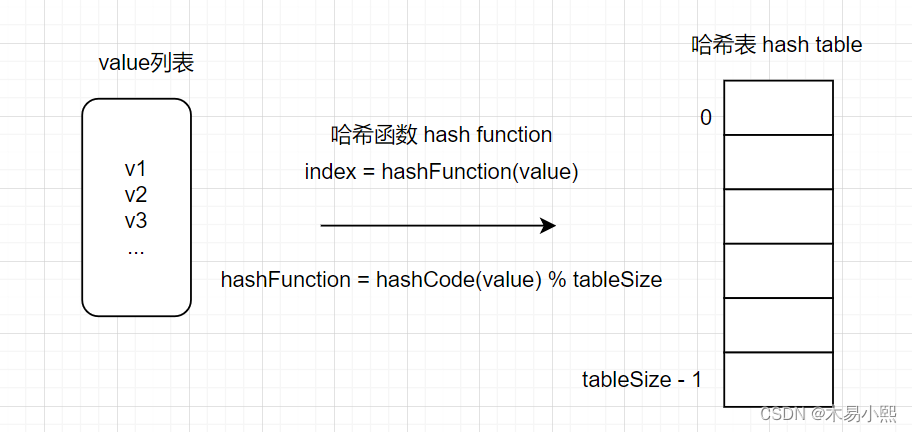
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,就要我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
如果value的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几个value同时映射到哈希表 同一个索引下标的位置。
接下来哈希碰撞登场
哈希碰撞
如图,v1和v2都映射到同一位置上,这一现象叫做哈希碰撞
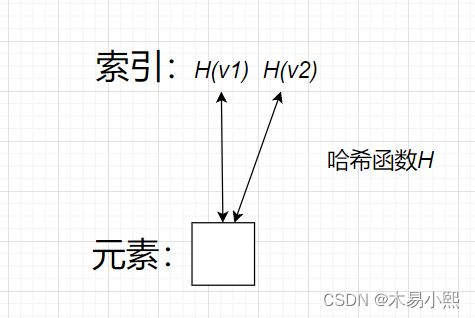
一般哈希碰撞有两种解决方法,开放地址法和链地址法(拉链法)
开放地址法
开放地址法的基本思想是:
把记录都存储在哈希表数组中,当某一记录关键字 key 的初始哈希地址H₀ = H(key) 发生冲突时,以H₀未基础,采取合适方法计算得到另一个地址H₁,如果H₁仍然发生冲突,以H₁为基础在求出下一个地址H₂ ,若H₂ 仍然冲突,再求得H₃。依次类推,直至Hₖ 不发生冲突为止,则Hₖ为该记录在表中哈希地址。
开放地址法分为三种具体的探测方法,线性探测法、二次探测法和伪随机探测法,下面具体说一下线性探测法。
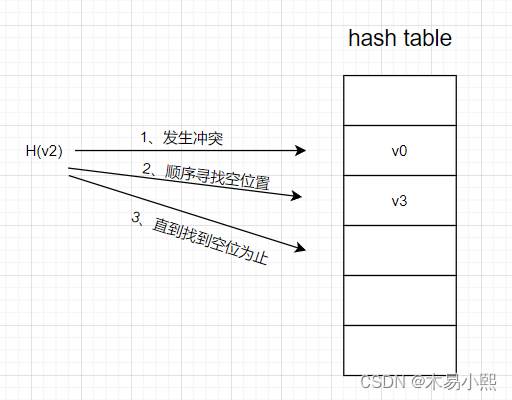
线性探测法
将哈希表想象成一个循环表,发生冲突时,从冲突地址的下一单元顺序寻找空单元,如果到最后一个位置也没有找到空单元,则回到表头开始继续查找,一旦找到一个空位,就把此元素放入次空位中。如果找不到空位,说明哈希表已满,需要进行溢出处理
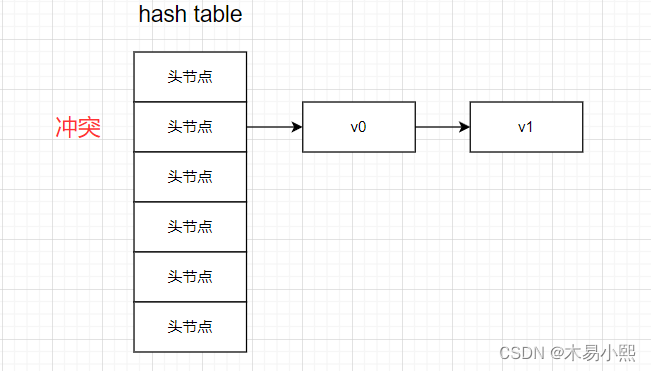
链地址法(拉链法)
链地址法的具体思想是:
把具有相同哈希地址的记录放在同一个单链表中,称之为同义词链表。有m个哈希地址就有m个单链表。凡是出现冲突的value,都以节点的方式插入到以出现冲突的哈希地址为头节点的单链表中

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









