 Python数据类型深入解析:元组、字典与集合
Python数据类型深入解析:元组、字典与集合








 本文详细介绍了Python的基础数据类型,包括元组的不可变特性,字典的快速查找和插入原理,以及集合的去重功能。通过实例展示了它们的操作方法,如元组的转换、字典的增删改查和集合的数学运算。强调了这些数据类型在实际编程中的应用价值。
本文详细介绍了Python的基础数据类型,包括元组的不可变特性,字典的快速查找和插入原理,以及集合的去重功能。通过实例展示了它们的操作方法,如元组的转换、字典的增删改查和集合的数学运算。强调了这些数据类型在实际编程中的应用价值。
元组
我们知道,用方括号括起来的是列表,那么用圆括号括起来的是什么,是元组。
元组也是序列结构,但是是一种不可变序列,你可以简单的理解为内容不可变的列表。除了在内部元素不可修改 的区别外,元组和列表的用法差不多。
元组与列表相同的操作:
- 使用方括号加下标访问元素
- 切片(形成新元组对象)
- count()/index()
- len()/max()/min()/tuple()
元组中不允许的操作,确切的说是元组没有的功能
- 修改、新增元素
- 删除某个元素(但可以删除整个元组)
- 所有会对元组内部元素发生修改动作的方法。
例如,元组没有remove,append,pop等方法 看一些实例:
tup1 = () # 创建空元组
tup1 = (40,) # 创建只包含一个元素的元组时,要在元素的后面跟个逗号
tup = (1, 2, 3, 4)
tup[2]
3
tup[3] = "a"
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
tup[3] = "a"
TypeError: 'tuple' object does not support item assignment
元组与列表类似的特殊操作

元组只保证它的一级子元素不可变,对于嵌套的元素内部,不保证不可变!
tup = ('a', 'b', ['A', 'B'])
tup[2][0] = 'a'
tup[2][1] = 'b'
tup
('a', 'b', ['a', 'b'])
列表和元组的转换
使用list函数可以把元组转换成列表
使用tuple函数可以把列表转换成元组
字典
Python的字典数据类型是基于hash散列算法实现的,采用键值对(key:value)的形式,根据key的值计算value的 地址,具有非常快的查取和插入速度。但它是无序的,包含的元素个数不限,值的类型也可以是其它任何数据类 型!
字典的key必须是不可变的对象,例如整数、字符串、bytes和元组,但使用最多的还是字符串。 列表、字典、集 合等就不可以作为key。同时,同一个字典内的key必须是唯一的,但值则不必。
字典可精确描述为不定长、可变、无序、散列的集合类型
字典的每个键值对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,例如:
d = {key1 : value1, key2 : value2 }
创建字典
dict()函数是Python内置的创建字典的方法。
test = {} # 创建空字典
test = {"a":'123','b':'2',"c":3}
dict([('name', 'juran'), ('age', 18), ('addr', 'cs')])
{'name': 'juran', 'age': 18, 'addr': 'cs'}
dict(a=1, b=2, jack=4098)
{'a':1,'b':2}
访问字典
字典是集合类型,不是序列类型,因此没有索引下标的概念,更没有切片的说法。但是,与list类似,字典采用把 相应的键放入方括号内获取对应值的方式取值。
dic = {'Name': 'json','Age': 18}
print ("dic['Name']: ", dic['Name'])
print ("dic['Age']: ", dic['Age'])
如果访问字典里没有的键,会抛出异常:
dic['address']
Traceback (most recent call last):
File "<pyshell#7>", line 1, in <module>
dic["address"]
KeyError: 'address'
增加和修改
增加就是往字典插入新的键值对,修改就是给原有的键赋予新的值。由于一个key只能对应一个值,所以,多次 对一个key赋值,后面的值会把前面的值冲掉。
dic = {'Name': 'json','Age': 18}
dic["address"] = "beijing"
dic["address"] = "Shanghai"
dic["Age"] = 20
dic
{'Name': 'json', 'Age': 20, 'address': 'Shanghai'}
-------------------------------------
要统计字典内键的个数,可以使用Python内置的len()函数:
len(dic)
3
删除字典元素、清空字典和删除字典
使用del关键字删除字典元素或者字典本身,使用字典的clear()方法清空字典。
dic
{'Name': 'json', 'Age': 20, 'address': 'Shanghai'}
del dic['Name'] # 删除指定的键
dic
{'Age': 20, 'address': 'Shanghai'}
-------------------------------------
a = dic.pop('Age') # 弹出并返回指定的键。必须提供参数!
20
dic.clear() # 清空字典
del dic # 删除字典本身
字典的重要方法
get(key) 返回指定键的值,如果值不在字典中,则返回default值
items() 以列表返回可遍历的(键, 值) 元组对
keys() 以列表返回字典所有的键
values() 以列表返回字典所有的值
接下来我们看看例子:
dic = {'Name': 'json', 'Age': 20, 'address': 'Shanghai'}
dic.get("sex") # 访问不存在的key,没有报错
dic['sex'] # 访问不存在的key,报错。
Traceback (most recent call last):
File "<pyshell#44>", line 1, in <module>
dic["sex"]
KeyError: 'sex'
-------------------------------------
dic.items()
dict_items([('Name', 'json'), ('Age', 20), ('address', 'Shanghai')])
-------------------------------------
dic.values()
dict_values(['json', 20, 'Shanghai'])
-------------------------------------
dic.keys()
dict_keys(['Name', 'Age', 'address'])
-------------------------------------
dic.pop('Name')
json
遍历字典
从Python3.6开始遍历字典获得的键值对是有序的。
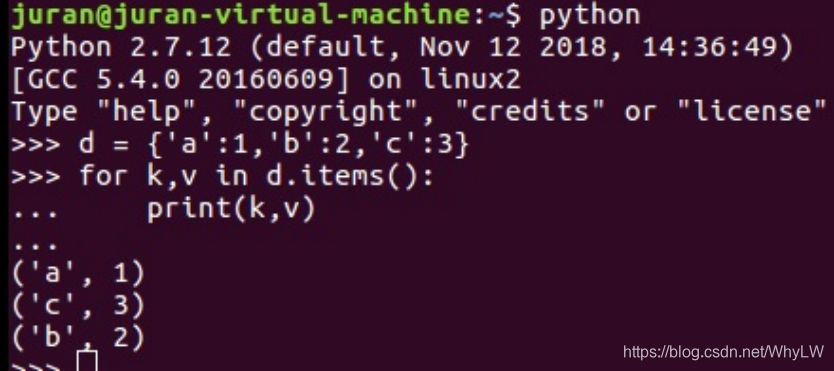
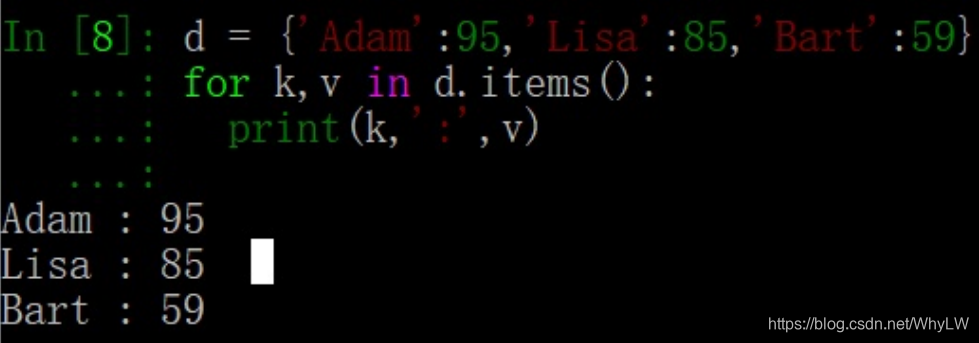
dic = {'Name': 'Jack', 'Age': 7, 'Class': 'First'}
1 直接遍历字典获取键,根据键取值
for key in dic:
print(key, dic[key])
2 利用items方法获取键值,速度很慢,少用!
for key,value in dic.items():
print(key,value)
3 利用keys方法获取键
for key in dic.keys():
print(key, dic[key])
4 利用values方法获取值,但无法获取对应的键。
for value in dic.values():
print(value)
bytes
在Python3以后,字符串和bytes类型彻底分开了。字符串是以字符为单位进行处理的,bytes类型是以字节为单 位处理的。
bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。
Python3中,bytes通常用于网络数据传输、二进制图片和文件的保存等等。可以通过调用bytes()生成bytes实 例,其值形式为 b’xxxxx’,对于同一个字符串如果采用不同的编码方式生成bytes对象,就会形成不同的值。
b = b'' 创建一个空的bytes
b = byte() 创建一个空的bytes
b = b'hello' 直接指定这个hello是bytes类型
b = bytes('string',encoding='编码类型') 利用内置bytes方法,将字符串转换为指定编码的by
tes
b = str.encode('编码类型') 利用字符串的encode方法编码成bytes,默认为utf-8类型
bytes.decode('编码类型') 将bytes对象解码成字符串,默认使用utf-8进行解码。
当然也有简单的使用方法
string = b'xxxxxx'.decode() 直接以默认的utf-8编码解码bytes成string
b = string.encode() 直接以默认的utf-8编码string为bytes
In [38]: s = 'abc'
In [39]: s.encode('utf8')
Out[39]: b'abc'
In [40]: s1 = b'abc'
In [41]: s1.decode()
Out[41]: 'abc'
set集合
集合set
set集合是一个无序不重复元素的集,基本功能包括关系测试和消除重复元素。集合使用大括号({})框定元素,并 以逗号进行分隔。但是注意:如果要创建一个空集合,必须用 set() 而不是 {} ,因为后者创建的是一个空字典。 集合数据类型的核心在于自动去重。
s = set([1,1,2,3,3,4])
s
{1, 2, 3, 4} # 自动去重
-------------------------------------
>>> set("this is test") # 对于字符串,集合会把它一个一个拆开,然后去重,空格是空格去 重
{'t', ' ', 's', 'h', 'e', 'i'}
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
s = {1,2,3,4}
s.add(5)
s
{1,2,3,4,5}
s.add(5)
{1,2,3,4,5}
可以通过update()方法,将另一个对象更新到已有的集合中,这一过程同样会进行去重。
>>> s
{1, 2, 3, 4, 5}
>>> s.update("json")
>>> s
{1, 2, 3, 4, 5, 'j', 's', 'n', 'o'}
通过remove(key)方法删除指定元素,或者使用pop()方法。注意,集合的pop方法无法设置参数,删除指定的元素:
s
{1, 2, 3, 4, 5, 'j', 's', 'n', 'o'}
s.remove("n")
{1, 2, 3, 4, 5, 'j', 's', 'o'}
s.pop() # 弹出第一个元素
1
s.pop(3)
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
s.pop(3)
TypeError: pop() takes no arguments (1 given)
需要注意的是,集合不能取出某个元素,因为集合既不支持下标索引也不支持字典那样的通过键值对获取。 除了add、clear、copy、pop、remove、update等集合常规操作,剩下的全是数学意义上的集合操作,交并差等等
对集合进行交并差等,既可以使用union一类的英文方法名,也可以更方便的使用减号表示差集,“&”表示交 集,“|”表示并集 。
x = set('runoob')
y = set('google')
x, y
(set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) # 重复的被删除
x & y # 交集
set(['o'])
x | y # 并集
set(['b', 'e', 'g', 'l', 'o', 'n', 'r', 'u'])
x - y # 差集
set(['r', 'b', 'u', 'n'])
集合数据类型属于Python内置的数据类型,但不被重视,在很多书籍中甚至都看不到一点介绍。其实,集合是一 种非常有用的数据结构,它的去重和集合运算是其它内置类型都不具备的功能,在很多场合有着非常重要的作 用,比如网络爬虫。
最后
人生苦短,Python当歌!!!
原创不易,严禁抄袭。


















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









