




 本文介绍了Python爬虫面对的常见反爬虫机制,包括header检验、User-Agent、Referer、Cookies、X-Forwarded-For、访问频率限制和IP限制。针对这些机制,提供了相应的应对策略,如设置User-Agent、处理Cookies、使用代理IP等,帮助爬虫开发者绕过限制。
本文介绍了Python爬虫面对的常见反爬虫机制,包括header检验、User-Agent、Referer、Cookies、X-Forwarded-For、访问频率限制和IP限制。针对这些机制,提供了相应的应对策略,如设置User-Agent、处理Cookies、使用代理IP等,帮助爬虫开发者绕过限制。
爬虫与反爬虫,这相爱相杀的一对,简直可以写出一部壮观的斗争史。而在大数据时代,数据就是金钱,很多企业都为自己的网站运用了反爬虫机制,防止网页上的数据被爬虫爬走。然而,如果反爬机制过于严格,可能会误伤到真正的用户请求;如果既要和爬虫死磕,又要保证很低的误伤率,那么又会加大研发的成本。
简单低级的爬虫速度快,伪装度低,如果没有反爬机制,它们可以很快的抓取大量数据,甚至因为请求过多,造成服务器不能正常工作。而伪装度高的爬虫爬取速度慢,对服务器造成的负担也相对较小。所以,网站反爬的重点也是那种简单粗暴的爬虫,反爬机制也会允许伪装度高的爬虫,获得数据。毕竟伪装度很高的爬虫与真实用户也就没有太大差别了。
header检验
最简单的反爬机制,就是检查 HTTP 请求的 Headers信息,包括 User-Agent, Referer、Cookies 等。
User-Agent
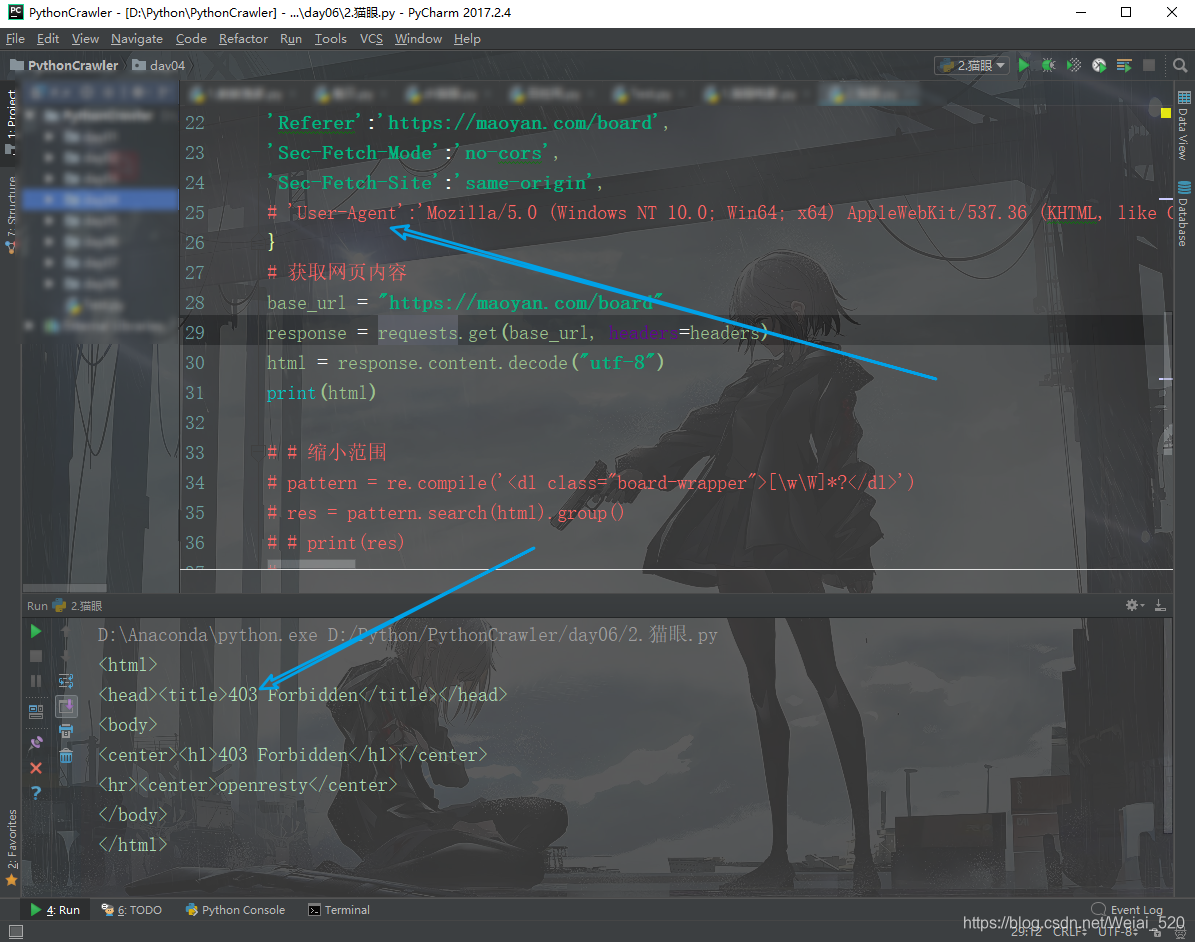
当我们使用浏览器访问网站的时候,浏览器会发送一小段信息给网站,我们称为Request Headers,在这个头部信息里面包含了本次访问的一些信息,例如编码方式,当前地址,将要访问的地址等等。这些信息一般来说是不必要的,但是现在很多网站会把这些信息利用起来。其中最常被用到的一个信息,叫做“User-Agent”。网站可以通过User-Agent来判断用户是使用什么浏览器访问。
我们以猫眼电影为例,下图是没有User-Agent的情况:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









