



转自https://www.datalearner.com/blog/1051501160659926
一、环境的准备
JDK需8.0以上
1、JDK 8.0: http://download.oracle.com/otn-pub/java/jdk/8u144-b01/090f390dda5b47b9b721c7dfaa008135/jdk-8u144-windows-x64.exe
2、IntelliJ IDEA: https://download.jetbrains.8686c.com/idea/ideaIC-2017.2.exe
二、创建工程
安装好环境后,我们打开IntelliJ IDEA,然后创建一个Maven工程,Group Id和Artifact Id自己随便写没关系的。创建完之后我们的目录就如下图所示了。


好了,下面我们就开始编写爬虫了。
三、第一个示例
首先,假设我们需要爬取数据学习网站上第一页的博客(http://www.datalearner.com/blog )。首先,我们需要使用maven导入HttpClient 4.5.3这个包(这是目前最新的包,你可以根据需要使用其他的版本)。那么,我们在pom.xml中添加如下语句:
<dependencies><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.3</version></dependency></dependencies>
此时4.5.3会标红,点击右下角idea自动跳出的enable...自动下载,下载完成后标红消失。
Java本身提供了关于网络访问的包,在java.net中,然后它不够强大。于是Apache基金会发布了开源的http请求的包,即HttpClient,这个包提供了非常多的网络访问的功能。在这里,我们也是使用这个包来编写爬虫。好了,使用pom.xml下载完这个包之后我们就可以开始编写我们的第一个爬虫例子了。其代码如下(注意,我们的程序是建立在test包下面的,因此,需要在这个包下才能运行):
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* description:httpclient爬虫
* @author WangJunhe
* @date 2019-07-13
* @version 1.0
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("https://www.youkuaiyun.com/");
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = null;
try {
entity = response.getEntity();
} catch (NullPointerException e) {
e.printStackTrace();
}
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
如上面的代码所示,爬虫的第一步需要构建一个客户端,即请求端,我们这里使用CloseableHttpClient作为我们的请求端,然后确定使用哪种方式请求什么网址,再然后使用HttpResponse获取请求的地址对应的结果即可。最后取出HttpEntity转换一下就可以得到我们请求的网址对应的内容了。上述程序对应的输出如下图所示:
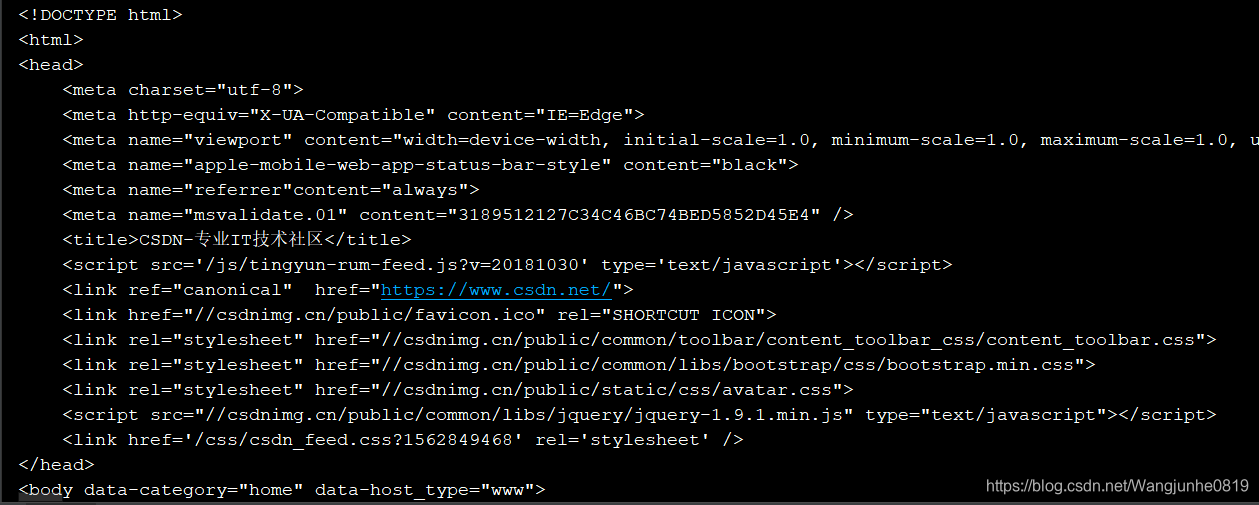
显然,这就是我们需要的网址对应的页面的源代码。于是我们的第一个爬虫就成功的将网门需要的页面的内容下载下来了。

















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









