



一、子查询
1. 子查询的介绍
在一个select语句中嵌入另一个select语句,被嵌入的select语句称之为子查询语句,在外面的select语句称之为主查询。
2.主查询和子查询的关系
- 子查询是嵌入到主查询中的
- 子查询主要是辅助主查询的,要么充当条件,要么充当数据来源
- 子查询也是一条可以独立存在的语句,是一条完整的可以运行的select语句
3.子查询的使用
根据子查询的结果分类(标量、行级、列级)
例1:查询大于平均年龄的学生 (标量子查询、一个值、一行一列)
select * from students where age > (select avg(age) from students);
例2:查询学生的学号与班级相符的所有学生名字 (行级子查询、一列多行值)
select name from sutdents where id in (select id from class);
例3:查询年龄最大,身高最高的学生 (列级子查询、一行多列值)
select * from students where (age,height)>(select max(age),max(height) from students);
子查询就是一个完整的SQL语句,子查询被嵌入到一对小括号里面,有辅助查询的作用。
二、数据库设计之三范式
1. 数据库设计之三范式的介绍
范式:是对设计数据库提出的一些规范,目前共有8中,一般遵守3范式即可。
- 第一范式(1NF):强调的是列的原子性,激列不能再分成其他几列。
- 第二范式(2NF):满族1NF,另外包含两部分,一是表必须有主键;二是非主键字段必须完全依赖主键,不能部分依赖主键。
- 第三范式(3NF):满足2NF,另外非主键列必须直接依赖主键,不能存在传递依赖。即不能存在:非主键列A依赖非主键列B,非主键列B依赖主键的情况。
说明:范式的存在是为了能够更好的设计出规范的数据库。
三、E-R模型
1. E-R模型即实体-关系模型,E-R模型就是描述数据库存储数据的结构模型。
E-R模型使用场景:
(1).对于大型公司开发项目,我们需要根据产品经理的设计,我们先使用建模工具,如power desiner等这些软件来画出实体-关系模仿(E-R模型)
(2)然后根据三范式设计数据库表结构
E-R模型的效果图:
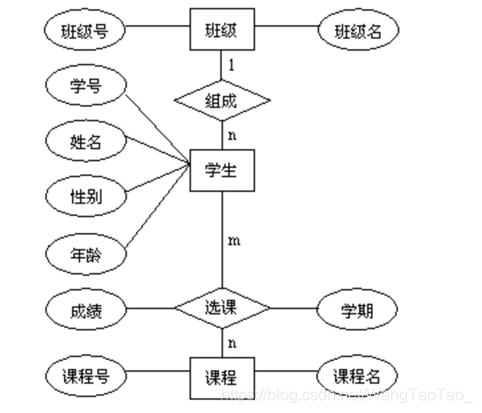
说明:
- 实体:用矩形表示
- 属性:用椭圆表示
- 关系:用菱形表示
2.E-R模型中有三种关系:
一对一、一对多、多对多
3.一对一
关系也是一种数据,需要通过一个字段存储在表中,一对一关系,在表A和在表B中创建一个字段,存储另一个表的主键值。
例如生活中一个人只有一个身份证号就是一对一的关系
4.一对多
一对多的关系就是在多的一个表(学生表)中创建一个字段,存储班级的主键值
5.多对多
多对多新建一张表C,这个表只有两个字段,一个用于存储A的主键值,另一个用于存储B的主键值。
四、数据库中外键SQL语句
1.外键约束的作用
外键约束:对外键字段的值进行更新和插入时会引用表中字段的数据进行验证,数据如果不合法则更新和插入会失败,以此来保证数据的有效性
(1)对于已经存在的字段进行添加外键约束
例如:给id字段添加外键约束
Alter table students add foreign key(id) references class(id);
(2)在创建数据表时设置外键约束
例如:创建学校表、创建老师表,给老师表中的key_id字段加外键
create table school(
id int unsigned primary key auto_increment not null,
name varchar(20) not null
);
create table teachers(
Id int unsigned primary key auto_increment not null,
name varchar(20) not null,
foreign key(key_id) references school(id)
);
2.删除外键约束
// 需要先获取外键约束名称,该名称系统会自动生成,可以通过查看创建语句来查看
show create table teacher;
// 获取名称之后可以根据名称来删除外键约束
alter table teachers drop foreign key 外键名;
五、PyMYSQL的使用
1.思考
如何实现将10000000条数据插入到MySQL数据库?
答案:如果使用之前学习的MySQL客户端来完成这个操作,那么这个工作量无疑是巨大的,我们可以通过使用程序代码的方式去连接MySQL数据库,然后对MySQL数据库进行增删改查的方式,实现10000条数据的插入,像这样使用代码的方式操作数据库就称为数据库编程。
2.安装pymysql第三方包
sudo apt-get install pymysql;
pop3 list可以查看使用pip命令安装的第三方包列表
3.pymysql的使用(以下是在pycharm中实现的)
导入pymysql包
Import pymysql
(1)创建链接对象
conn = connect(参数列表)
参数说明:
~ 参数host:连接的mysql主机,如果是本机可以用’localhost’或者’127.0.0.1’
~ 参数port:连接的mysql主机的端口号,默认是3306
~ 参数user:连接的mysql用户名
~ 参数password:连接的mysql密码
~ 参数databases:数据库的名称
~ 参数charset:与主机通信猜用的编码方式,推荐utf8
连接对象操作说明:
关闭连接 conn.close()
提交数据 conn.commit()
撤销数据 conn.rollback()
(2)获取游标对象
获取游标对象的目的就是要执行sql语句
# 调用连接对象conn的cursor()方法来获取游标对象
游标操作说明:
- 使用游标执行SQL语句: execute(operation [parameters ]) 执行SQL语句,返回受影响的行数,主要用于执行insert、update、delete、select等语句
- 获取查询结果集中的一条数据:cur.fetchone()返回一个元组, 如 (1,'张三')
- 获取查询结果集中的所有数据: cur.fetchall()返回一个元组,如((1,'张三'),(2,'李四'))
- 关闭游标: cur.close(),表示和数据库操作完成
4.pymysql完成数据的查询操作
// 首先导入pymysql 模块
import pymsql
# 1 创建连接对象
conn=pymysql.connect(host=’localhost’,port=3306,user=’root’,password=’mysql’,database=’python’,charset=’utf8’)
# 2 获取游标对象
cur = conn.cursor()
# 3 通过游标执行SQL语句
# 查询的SQL语句
sql = ‘select * from students;’
# 执行SQL语句,返回值row_count是SQL语句在执行过程中影响的行数
row_count = cur.execute(sql)
# 4 取出一行数据 例如(1,’wtt’,22,177,60,’男’)
print(cur.fetchone())
# 4 取出多行数据 例如(1,’wtt’,22,177,60,’男’),(2….),(3…)
print(cur.fetchall())
# 5 关闭游标对象
cur.close()
# 5 关闭连接
conn.close()
5.pymysql完成对数据的增删改
# 1 创建连接对象
conn=pymysql.connect(host=’localhost’,port=3306,user=’root’,password=’mysql’,database=’python’,charset=’utf8’)
# 2 获取游标对象
cur = conn.cursor()
try:
# 3 通过游标执行SQL语句
# 增数据的SQL语句
sql = “insert into students vales(0,’asd’,10,’180’,70,’男’);“
# 删数据是SQL语句
sql = “delete from students where id = 5;”
# 更新数据的SQL语句
sql = “update students set name=”ddd” ,age = 18 where id = 3;”
# 执行SQL语句,返回值row_count是SQL语句在执行过程中影响的行数
row_count = cur.execute(sql)
# 4 取出一行数据 例如(1,’wtt’,22,177,60,’男’)
print(cur.fetchone())
# 4 取出多行数据 例如(1,’wtt’,22,177,60,’男’),(2….),(3…)
print(cur.fetchall())
// 因为做了更删改的操作,所以需要提交数据到数据库
conn.commit()
except Exception as e:
// 回滚操作 即撤销
conn.rollback()
# 5 关闭游标对象
cur.close()
# 5关闭连接
conn.close()
六、防止SQL注入
什么是防SQL注入?
用户提交带有恶意的数据与SQL语法进行字符串方式的拼接,从而影响了SQL语句的逻辑和语义,最终产生数据泄露的现象。
如何防止SQL注入?
SQL语句参数化
- SQL语言中的参数使用%s来占位,此处不是python中的字符串格式化操作
- 2SQL语句中的%s占位所需要的参数存在一个列表中,把参数列表传递给execute方法中的第二个参数
防止SQL注入的示例代码:
Import pymsql
def main():
find_name = input(“请输入物品名称:”)
find_id = input(“请输入物品id:”)
# 创建连接
conn = pymysql.connect(host=’localhost’,port=3306,user=’root,
password=’mysql’,database='python’,charset=’utf8’)
# 创建游标对象
cur = conn.cursor()
# 非安全方式 执行sql语句
# sql = ‘select * from goods where name =”%s” age =”%s” ‘ % (find_name,find_id)
# cur.execute(sql)
# 此时如果进行查询,用户如果输入了1’#就可以获取任意数据,即SQL注入
# 安全的方式 执行sql语句
sql = “select * from goods where name =%s ,id=%s”
my_list=[find_name,id]
row_count = cur.execute(sql,my_list)
# 获取数据
print(cur.fetchall())
# 关闭连接和游标
cur.close()
conn.clse()
七 、事务
1.事务就是用户定义的一系列执行SQL语句的操作,这些操作要么完全的执行,要么就完全的不执行,它是一个不可分割的工作执行单元。
事务的使用场景:
在日常生活中,有时我们需要进行银行转账,这个银行转账操作背后就是需要执行多个SQL语句,假如这些SQL执行到一半突然停电了,那么就会导致这个功能只完成了一半,这种情况是不允许出现,要想解决这个问题就需要通过事务来完成。
2.事务的四大特性ACID
- 原子性
- 一致性
- 隔离性
- 持久性
原子性:
一个事务必须被视为是一个不可分割的最小单元,整个事务中的操作要么全部提交成功,要么全部回滚,对于一个事务来说,不可能只执行其中的一部分操作。
一致性:
数据库总是从一个一致性的状态转换到另一个一致性的状态。(在前面的例子中,一致性确保了,即使在转账过程中系统崩溃,支票账户中也不会损失200美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。)
隔离性:
通常来说,一个事务所作的修改操作在提交事务之前,对于其他事务来说是不可见的。(在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外的一个账户汇总程序开始运行,则其看到支票帐户的余额并没有被减去200美元。)
持久性:
一旦事务提交,数据永久保存到数据库
说明:
事务能够保证数据的完整性和一致性,让用户的操作更加安全。
(1)事务的使用,在使用事务之前要确保表的存储引擎是InnoDB类型,因为只有这个类型可以使用事务,MySQL数据库中的表的存储引擎默认是InnoDB类型。
表的存储引擎说明:
表的存储引擎就是提供一种存储数据的机制,不同表的存储引擎提供给不同的存储机制。
3.查看MySQL数据库支持的表的存储引擎
show engines
说明:
- 常用的表的存储引擎是 InnoDB 和 MyISAM
- InnoDB 是支持事务的
- MyISAM 不支持事务,优势是访问速度快,对事务没有要求或者以select、insert为主的都可以使用该存储引擎来创建2.修改
4.表的存储引擎
alter table 表明 engine=引擎类型;
5.开启事务
begin; 或者 start transaction;
6.开启事务后执行修改命令,变更数据会保存到MySQL服务端的缓存文件中,而不维护到物理表中。
7.MySQL数据库默认采用自动提交模式,如果没有显示的开启一个事务,那么每条sql语句都会被当作一个事务执行提交的操作。当设置了autocommit=0就是取消自动提交事务模式,直到显示的执行了commit和rollback表示改事务结束
8.提交事务和回滚事务
- commit; 将本地缓存文件的数据提交到物理表中,完成数据更新
- rollback;放弃本地缓存文件的缓存数据,表示回到事务开始前的状态
八、索引
1.索引的介绍
索引在MySQL中也叫做“键“,它是一个特殊的文件,它保存着数据表里的所有记录的位置信息,更通俗的来将,数据库索引就好比一本书的目录,能加快数据库的查询速度。
应用场景:
当数据库中数据量很大时,查找数据会变得很慢,我们就可以通过索引来提高查询的速度
2.索引的使用
(1)查看表中已有索引:
show index from 表名;
说明:主键列会自动创建索引
(2)索引的创建
alter table 表名 add index 索引名(字段名,…)
说明:这里如果索引名不指定的话,默认使用字段名
3.索引的删除
alter table 表名 drop index 索引名
4.复合索引
其实所谓的复合索引就是一个索引覆盖表中的两个或者多个字段,一般用在多个字段一起查询的时候
例如:alter table students add index (name,age);
说明:复合索引又叫联合索引,它的好处是减少磁盘空间开销,因为每创建一个索引,其实就是创建了一个索引文件,那么会增加磁盘空间的开销。
联合索引的最左原则,即index(name,age,address) 支持name;name,age;name,age,address组合查询,不支出age;address单独查询,也不支持name,address和age,address进行查询。因为没有用到创建的联合索引。
5.运行时间检测
// 开启运行时间检测
set profiling = 1;
// 查看执行的时间
show profiles;
6.MySQL中索引的有点和缺点的使用原则
优点:加快查询速度
缺点:创建索引会消耗时间和占用磁盘空间
- 使用原则:通过优缺点对比,不是索引越多越好,而是需要自己合理的使用。
- 对经常更新的表就避免对其进行过多索引的创建,对经常用于查询的字段应该创建索引,
- 数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
- 在一字段上相同值比较多不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可是建立索引。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









