



 本文详细介绍了Elasticsearch的安装步骤,包括Head插件和IK分词器的使用,以及如何通过Logstash实现Elasticsearch与MySQL的数据同步。
本文详细介绍了Elasticsearch的安装步骤,包括Head插件和IK分词器的使用,以及如何通过Logstash实现Elasticsearch与MySQL的数据同步。
下载并且安装ES
Elasticsearch与MySQL数据库逻辑结构概念的对比
| Elasticsearch | 关系型数据库Mysql |
| 索引(index) | 数据库(databases) |
| 类型(type) | 表(table) |
| 文档(document) | 行(row) |
下载ElasticSearch 5.6.8版本
https://www.elastic.co/downloads/past-releases/elasticsearch-5-6-8
资源\配套软件中也提供了安装包 无需安装,解压安装包后即可使用
在命令提示符下,进入ElasticSearch安装目录下的bin目录,执行命令
.\elasticsearch
我们打开浏览器,在地址栏输入http://127.0.0.1:9200/ 即可看到输出结果
安装Head插件
因为使用es-head工具,必须使用node js的环境支撑 Node.js 是什么? 前后台分离的时候,
前端想调用我们后端,需要依赖http请求,搭建前端的开发环境,node.jsNode.js 就是运行在服务端的 JavaScript。
Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台。
Node.js是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
安装node js
https://nodejs.org/zh-cn/点击下载并且安装
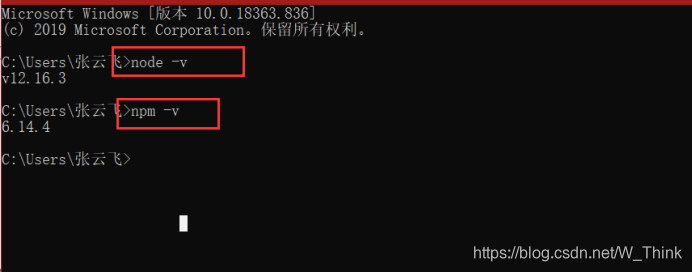
安装成功后,检查环境是否正常
打开github head的源码
https://github.com/mobz/elasticsearch-head下载并且解压到你本地
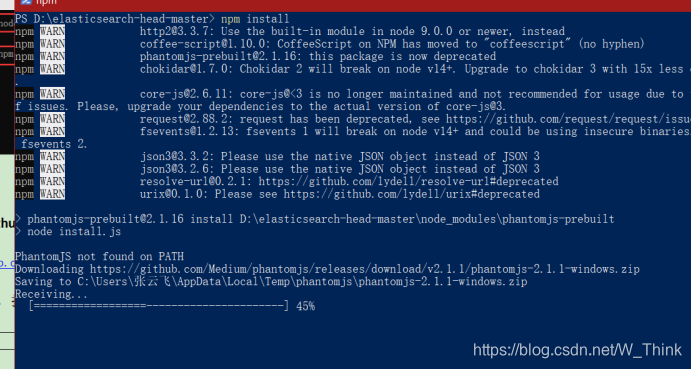
解压后,打开dos窗口,输入指令
npm install
启动head
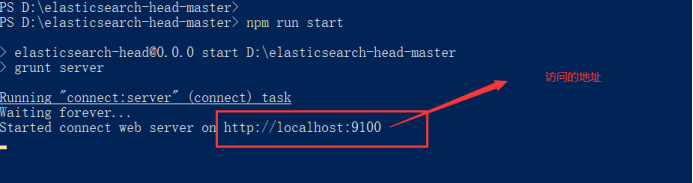
在解压的目录下输入指令
npm run start
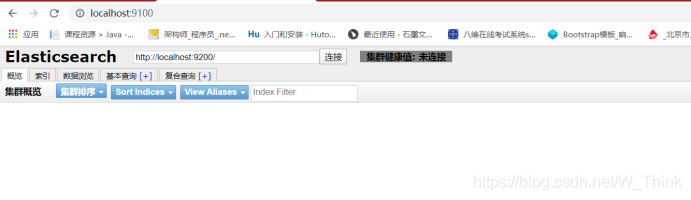
**解决跨域问题** 点击连接按钮,没有任何响应,按F12会发现如下错误 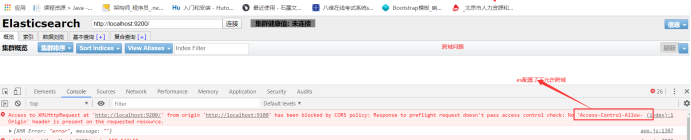
Access to XMLHttpRequest at ‘http://localhost:9200/’ from origin ‘http://localhost:9100’ has been blocked by CORS policy: Response to preflight request doesn’t pass access control check: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
需要修改elaticSearch配置文件:elasticsearch.yml文件中,增加以下两句命令
http.cors.enabled: true
http.cors.allow-origin: "*"
此步为允许elasticsearch跨越访问 点击连接即可看到相关信息
重启es服务,刷新页面
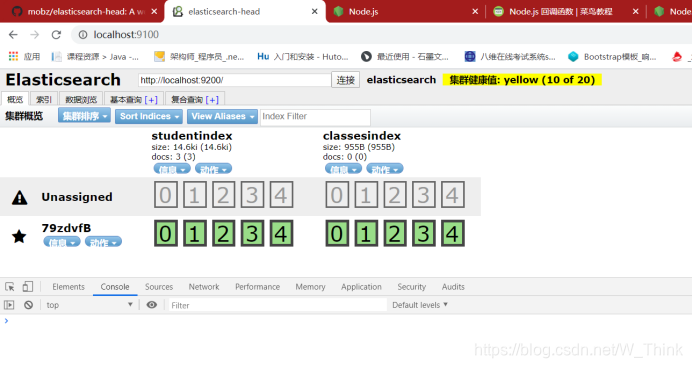
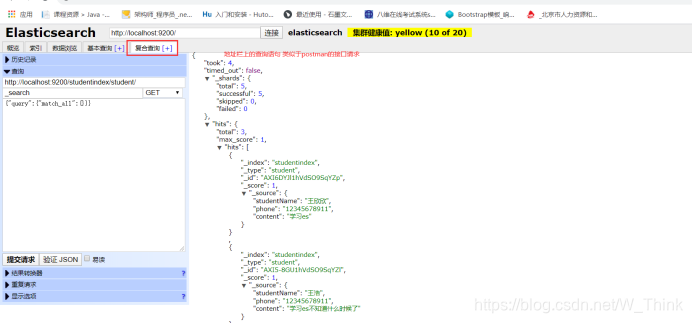
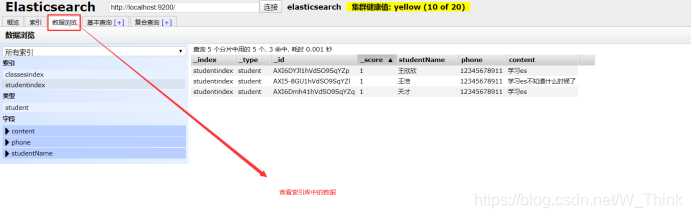
IK分词器
1.IK分词器的安装以及使用
1)讲下载好的IK分词器,解压,解压后,点进去,将里面的elasticsearch文件重命名为ik
2)讲ik文件夹拷贝到elasticsearch/plugins目录下
3)重新启动,即可加载ik分词器
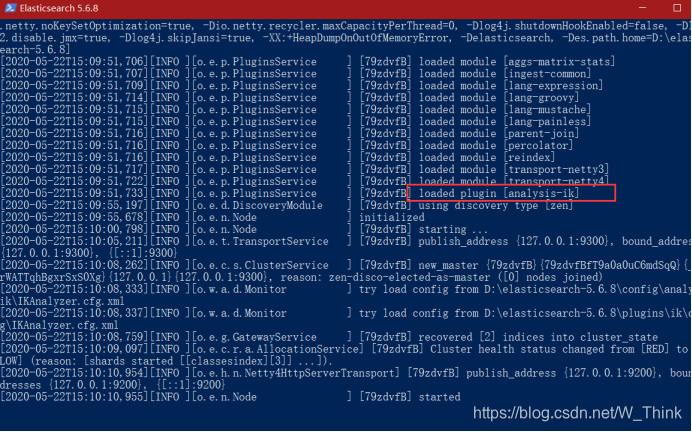
2.测试IK分词器的效果
IK提交两个分词算法 ik_smart 和 ik_max_word
ik_smart:最少切片
ik_max_word:最细粒度划分切片
3.自定义词库
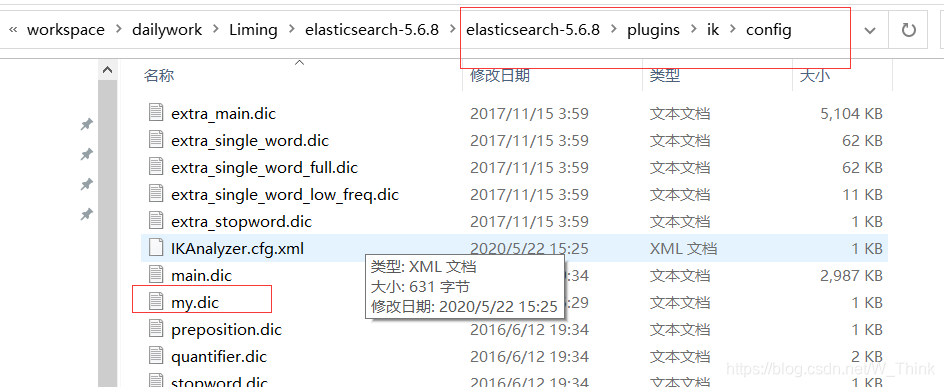
4.测试
我们在浏览器输入:
http://localhost:9200/_analyze?analyzer=chinese&pretty=true&text=我是中国人,我爱中国
Es跟mySql的数据同步
Logstash介绍
es官方推荐的一款轻量级的日志搜索处理框架,可以方便的把分散的,多样化的日志搜集起来, 并进行自定义的处理,然后 帮你传输到指定的位置,比如某个服务器或者文件中
1.Logstash安装和测试
解压logstash,进入bin目录下
.\logstash -e 'input {stdin {} } output{stdout{}} '
输入和输出
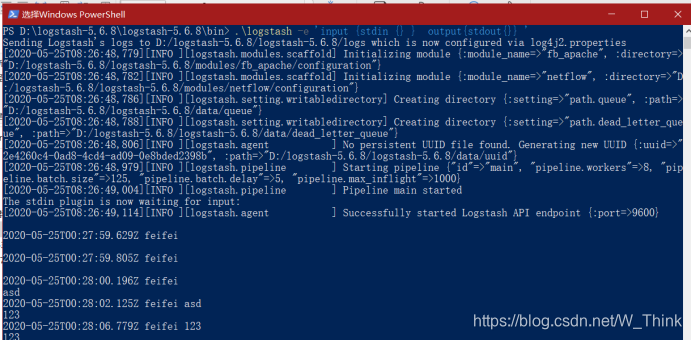
- Stdin,表示输入流,指从键盘输入
- Stdout 表示输出流,指从显示器输出
- -e 执行
- -f 执行文件
2.Mysql数据导入elasticsearch
①在logstatsh的目录下创建一个新的文件夹 mysqldata名字随意)
②在新建的文件夹下,从你的maven仓库中拷贝一份新数据库的jar包(依赖)
③新建一个mysql.conf的文件(文件的编码一定要是UTF-8的文件编码)
④把一下内容拷贝到mysql.conf文件中
input {
jdbc {
jdbc_connection_string =>"jdbc:mysql://192.168.152.153:3306/tensquare_article?setUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "D:/workspace/dailywork/Liming/logstash-5.6.8/logstash-5.6.8/mysqldata/mysql-connector-java-5.1.38.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
statement => "select id,title,content ,state FROM tb_article "
schedule => "* * * * *"
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "tensquare"
document_id => "%{id}"
document_type => "articlees"
}
stdout {
codec => json_lines
}
}
- jdbc_connection_string :需要你配置数据库连接地址
- jdbc_user :用户名
- jdbc_user :密码
- jdbc_driver_library配置你本地的mysql-connector-java-5.1.38.jar包的真实路径
- statement :查询的sql语句,并且字段一定要跟es中的type(表)保持一致
- index :eleaticsearch中的索引库的名称 document_type:eleaticsearch中的type名称(一定是存在)
- hosts :eleaticsearch的ip地址跟端口号 schedule :定时任务的时间表达式 (我们配置的是一分钟执行一次)
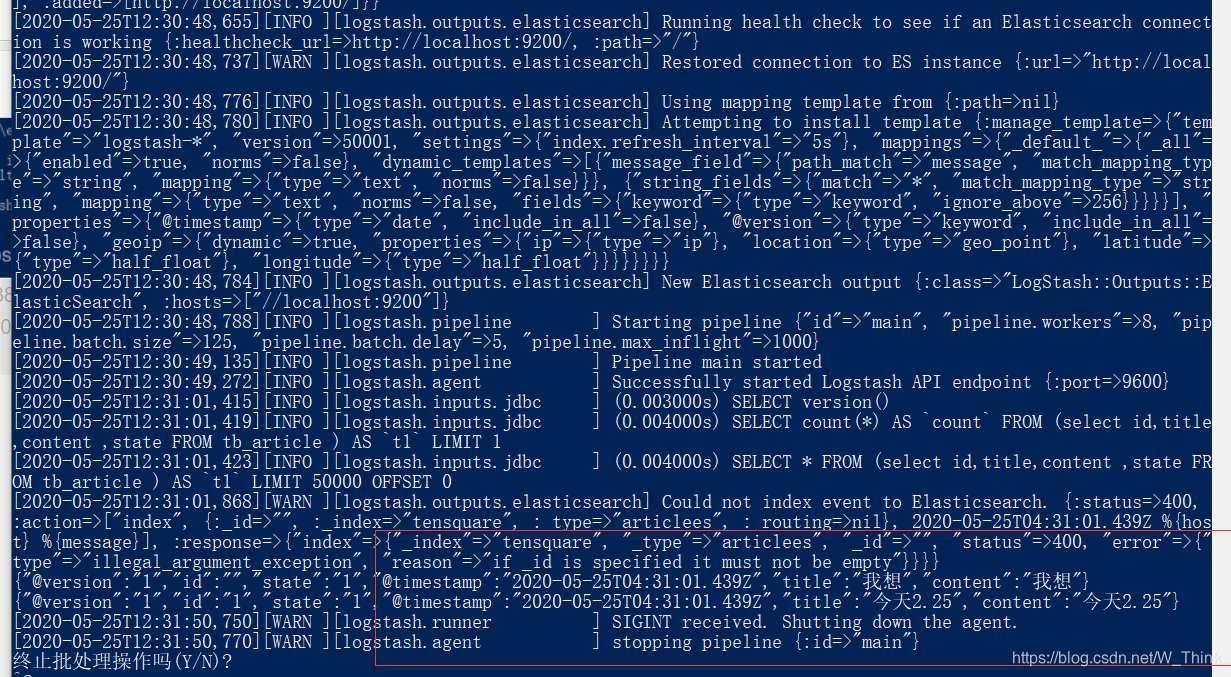
3.运行查看
.\logstash -f ..\mysqldata\mysql.conf

















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









