





目录
4、Broken pipe和Connection Reset by Peer的区别
一、Nginx的启动、停止与重启
1、启动nginx
/usr/local/nginx/sbin/nginx -t 检查nginx是否配置成功
/usr/local/nginx/sbin/nginx 启动nginx2、停止nginx,有三种方式:
从容停止:
# ps -ef|grep nginx
# kill -QUIT XXXX
快速停止:
# kill -TERM 2132
或者
# kill -INT 2132
强制停止:
# kill -9 nginx2、重启,进入nginx可执行目录sbin下,输入命令
/usr/local/nginx/sbin/nginx -s reload二、Redis命令
1、常用命令
连接redis
redis-cli -h host
验证密码
auth xxx
选择对应的库
select 库名
获取key
get KEY_NAME
批量查询key
scan 0 MATCH KEY_NAME:* COUNT 10000
全量查询key,尽量不要使用这个查询方式
keys *
删除key
DEL KEY_NAME2、Redis 内存使用情况
info memory
-------------------------------------------------------------------
used_memory:1670920 由 Redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human:1.59M 以人类可读的格式返回 Redis 分配的内存总量
used_memory_rss:1633992 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
used_memory_rss_human:1.56M
used_memory_peak:1807976 Redis 的内存消耗峰值(以字节为单位)
used_memory_peak_human:1.72M 以人类可读的格式返回 Redis 的内存消耗峰值
total_system_memory:0
total_system_memory_human:0B
used_memory_lua:37888 Lua 引擎所使用的内存大小(以字节为单位)
used_memory_lua_human:37.00K
maxmemory:1048576000 所查询的Redis设置的的最大内存值(以字节为单位)
maxmemory_human:1000.00M 所查询的Redis设置的的最大内存值(以mb为单位)
maxmemory_policy:noeviction
mem_fragmentation_ratio:0.98 used_memory_rss 和 used_memory 之间的比率
mem_allocator:jemalloc-3.6.0 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc3、大key查找
redis-cli --bigkeys -i 0.1 PS:每扫描100个key休息0.1秒,可以找到某个实例 5种数据类型(String、hash、list、set、zset)的最大key
4、大key删除-分批次删除:
- hash key:通过hscan命令,每次获取100个字段,再用hdel命令
- set key:使用sscan命令,每次扫描集合中100个元素,再用srem命令每次删除一个元素
- list key:删除大的List键,未使用scan命令; 通过ltrim命令每次删除少量元素
- sorted set key:删除大的有序集合键,和List类似,使用sortedset自带的zremrangebyrank命令,每次删除top 100个元素
5、大key删除-异步删除:
UNLINK keyName
flushall async //异步清理实例数据PS:用unlink代替del来删除,这样redis会将这个key放入到一个异步线程中,进行删除,这样不会阻塞主线程
三、Linux相关
1、挂载盘查询
df -TH2、查看当前目录下的文件大小
du -sh *3、格式化sh
dos2unix **.sh4、清空文件大小
cat /dev/null > 文件名5、测试端口是否连通
telnet 172.10.10.10 80826、多重视窗管理程序
查看运行列表:
screen -ls
进入运行窗口:
screen -r 窗口号
关闭运行窗口:
ctrl c
后台运行窗口:
ctrl a+d
使用screen名字,kill掉:
screen -S session_name -X quit7、端口占用
lsof -i:端口
netstat -tunlp | grep 端口号
端口是否对外开放
iptables -L -nnetstat:Linux之netstat命令详解_一口Linux的博客-优快云博客_linux netstat
8、用户相关
useradd testuser 创建用户testuser
passwd testuser 给已创建的用户testuser设置密码
userdel docker 删除用户
groupdel docker 删除用户组
su 用户名 说明:su是switch user的缩写,表示用户切换
从新的用户状态下输入“exit”即可退回到刚才的用户状态
# 将目录/home/kafka 及其下面的所有文件、子目录的owner用户改成 kafka
chown -R kafka:kafka /home/kafka
chown -R docker:docker /home/docker 9、文件传输
scp -r demo.jar root@IP:目录10、查看CPU型号
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c11、查看物理CPU的个数
cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l12、查看逻辑CPU的个数
cat /proc/cpuinfo |grep "processor"|wc -l13、查看CPU是几核
cat /proc/cpuinfo |grep "cores"|uniq11、rz乱码问题
文件中包含控制字符,使用一下命令解决
rz -be-b, –binary 用binary的方式上传下载,不解释字符为ascii -e, –escape强制escape 所有控制字符,比如Ctrl+x,DEL等
12、crontab
修改crontab:
crontab -e
---------------------------------------------------
*/1 * * * * cd /home/demo;sh demo.sh &13、防火墙的开启、关闭、禁用命令
设置开机启用防火墙:
systemctl enable firewalld.service
设置开机禁用防火墙:
systemctl disable firewalld.service
启动防火墙:
systemctl start firewalld
关闭防火墙:
systemctl stop firewalld
检查防火墙状态:
systemctl status firewalld 14、firewall-cmd配置端口
查看防火墙状态:
firewall-cmd --state
重新加载配置:
firewall-cmd --reload
查看开放的端口:
firewall-cmd --list-ports
开启防火墙端口:
firewall-cmd --zone=public --add-port=9200/tcp --permanent
命令含义:
–zone #作用域
–add-port=9200/tcp #添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
注意:添加端口后,必须用命令firewall-cmd --reload重新加载一遍才会生效
关闭防火墙端口:
firewall-cmd --zone=public --remove-port=9200/tcp --permanent
开启端口:
/sbin/iptables -I INPUT -p tcp --dport 9000 -j ACCEPT15、jdk安装
yum install java-1.8.0-openjdk -yjdk目录:/usr/lib/jvm/java-1.8.0-openjdk
16、Shell脚本中获取指定进程的PID
#!/bin/bash
. /etc/profile
jarName=jar目录
project_pid=`ps -ef | grep $jarName | grep -v grep | awk '{print $2}'`
if [ -z "$project_pid" ];
then
echo "[ not find project pid ]"
java -jar $jarName
else
echo "find result: $project_pid"
kill -9 $project_pid
java -jar $jarName
fi
- ps -ef | grep demo.jar 打印出包含 fms.jar 的所有进程信息(一行一个进程的信息)
- grep -v grep 过滤掉包含 grep 字符的行,过滤掉当前的查找进程
- awk '{print $2}' 输出第二列的内容;等于0时输出所有内容,大于0时输出指定列的内容
17、删除服务器乱码文件
使用 ls -i 查看这个文件的ID号
find -inum 删除文件ID号 -delete18、rsync文件备份脚本
#!/bin/bash
# A script to perform incremental backups using rsync
set -o errexit
set -o nounset
set -o pipefail
readonly SOURCE_DIR="/data/dataTofile/data"
readonly BACKUP_DIR="/data/transformFile/backups"
readonly DATETIME="$(date '+%Y-%m-%d-%H-%M-%S')"
readonly BACKUP_PATH="${BACKUP_DIR}/${DATETIME}"
readonly LATEST_LINK="${BACKUP_DIR}/latest"
readonly COPY_PATH="${BACKUP_PATH}/."
readonly READ_PATH="/data/fileTodata/data"
mkdir -p "${BACKUP_DIR}"
rsync -av --remove-source-files --delete \
"${SOURCE_DIR}/" \
--link-dest "${LATEST_LINK}" \
--exclude=".cache" \
"${BACKUP_PATH}"
cp -r "${COPY_PATH}" "${READ_PATH}"
rm -rf "${LATEST_LINK}"
ln -s "${BACKUP_PATH}" "${LATEST_LINK}"
19、文件语柄数相关操作
用户级修改
1、查看语柄数
ulimit -n2、查看当前进程打开了多少句柄数
lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr|more其中第一列是打开的句柄数,第二列是进程ID
3、根据ID号来查看进程名
ps aef|grep 242044、用户级修改临时生效方
ulimit -SHn 65536选项-S表示软性极限值,-H表示硬性极限值。硬性极限值是实际的限制
软性极限值则是系统发出警告(Warning)的极限值,超过这个极限值,内核会发出警告。
通过命令只能修改当前用户环境的一些基础限制,仅在当前用户环境有效。一旦断开用户会话,或者说用户退出Linux,它的数值就又变回系统默认的1024了。并且,系统重启后,句柄数量会恢复为默认值。
5、用户级修改永久有效方式
* 表示所用的用户
echo "* soft nofile 204800" >> /etc/security/limits.conf
echo "* hard nofile 204800" >> /etc/security/limits.conf
echo "* soft nproc 204800" >> /etc/security/limits.conf
echo "* hard nproc 204800 " >> /etc/security/limits.conf重启服务,才能生效
reboot系统级修改
上面都是对一个进程打开的文件句柄数量的限制,我们还需要设置系统的总限制才可以。
假如,我们设置进程打开的文件句柄数是1024 ,但是系统总线制才500,所以所有进程最多能打开文件句柄数量500。从这里我们可以看出只设置进程的打开文件句柄的数量是不行的。所以需要修改系统的总限制才可以。
1、临时修改方式
echo 6553560 > /proc/sys/fs/file-max2、永久修改方式
echo fs.file-max = 6553560 >> /etc/sysctl.conf重启服务,才能生效
reboot3、查看是否生效
sudo sysctl -p20、查看连接数
#本地连接中 time_wait
netstat -tnp | grep TIME_WAIT | awk '{print $4}' |sort | uniq -c | sort -n
#连接中外地的IP
netstat -tnp | awk '{print $5}' | sort | uniq -c |sort -n
#查看本地TCP状态排序
netstat -ntp |awk '{print $6}' | sort | uniq -c
#查看服务器某地址端口的连接数
netstat -nat | grep 0.0.0.0:8080 |awk '{print $5}' | sort | uniq -c | sort -rn21、Linux永久修改时区
新版Linux (CentOS7/Ubuntu18以后版本)
在CentOS7以后localtime,时区设置文件localtime变成了一个链接文件。
如果是中国地区,直接进行下面的操作,可以快速完成时区设置。
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime也可以用timedatectl命令来快速设置时区:
timedatectl set-timezone Asia/Shanghai旧版Linux(CentOS6及Ubuntu16以前版本)
旧版Linux的时区文件是/etc/localtime,下面操作即可完成设置。
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime22、tcpdump抓包
tcpdump -i eth0 -w /data/tcpdump/wvp.pcap四、PG相关
1、PG的 jieba分词,只对对小写字母匹配
SELECT to_tsvector('jiebaqry_m', 'MU5735');SELECT * from rule where status = 1 and (to_tsvector('jiebaqry_m', 'mu5735') @@rules);2、PG的 jsonb 查询
SELECT
include_media
FROM
user_topic_config
WHERE
include_media @> '[{ "authorName": "测试"}]' :: jsonb推荐使用第二种
SELECT
*
FROM
user_topic_config,
jsonb_array_elements ( include_media ) include_medias
WHERE
( include_medias ->> 'authorName' = '测试' ) 五、MySql相关
1、MySQL导入数据
格式:mysql -h[ip] -P[(大写)端口] -u[用户名] -p[密码] [数据库名] < d:XX.sql(路径)
导入命令:mysql -uroot -proot -h127.0.0.1 -P3306 education<d:/database.sql2、MySQL设置用户查看指定表
create user 'ftpuser1'@'%' identified by '123456';
-- grant all privileges on demo.test_mapping to 'ftpuser'@'%' with grant option;
grant select,insert on demo.test_mapping to 'ftpuser1'@'%' with grant option;
flush privileges;3、MySQL备份脚本
#!/bin/bash
# -------------------------------------------------------------------------------
# FileName: mysql_backup.sh
# Describe: Used for database backup
# Author: meng
# 设置mysql的登录用户名和密码(根据实际情况填写)
mysql_user="user"
mysql_password="password"
mysql_host="localhost"
mysql_port="3306"
backup_dir="/data/mysql"
#将要备份的数据库
database_name="database"
dt=$(date "+%Y%m%d_%H%M")
echo "Backup Begin Date:" $(date +"%Y-%m-%d %H:%M:%S")
echo "$dt"
#如果文件夹不存在则创建
if [ ! -d $backup_dir ];
then
mkdir -p $backup_dir;
fi
# 备份全部数据库
mysqldump -h$mysql_host -P$mysql_port -u$mysql_user -p$mysql_password --databases $database_name > $backup_dir/mysql_backup_$dt.sql
#find $backup_dir -mtime +7 -type f -name '*.sql' -exec rm -rf {} \;
echo "Backup Succeed Date:" $(date +"%Y-%m-%d %H:%M:%S")
crontab(每周备份一次):
0 0 * * 7 sh /usr/local/bin/mysql_backup.sh > /usr/local/bin/mysql_backup.log 2>&1六、日常开发相关
1、Java CompletableFuture 多线程
public static void main(String[] args) {
ExecutorService executor = ExecutorBuilder.create()
.setCorePoolSize(4)
.setMaxPoolSize(8)
.setWorkQueue(new LinkedBlockingQueue<>(500))
.setKeepAliveTime(1, TimeUnit.MINUTES)
.setHandler(new ThreadPoolExecutor.CallerRunsPolicy())
.setThreadFactory(ThreadFactoryBuilder.create().setNamePrefix("async-").build())
.build();
List<String> ids = Lists.newArrayList();
CompletableFuture[] futures = disposeList.stream()
.map(d -> this.asyncMethod(d).thenAcceptAsync(id -> ids.add(id), executor)).toArray(CompletableFuture[]::new);
CompletableFuture.allOf(futures).exceptionally(e -> {
log.error("ASYNC ERROR: {}", e);
return null;
}).join();
}
private CompletableFuture<String> asyncMethod(Demo demo) {
return CompletableFuture.supplyAsync(() -> {
//处理逻辑
return demo.getId();
}, executor);
}相关链接:CompletableFuture用法详解 - 知乎
2、Idea访问堡垒机服务
-DsocksProxyHost=127.0.0.1 -DsocksProxyPort=1080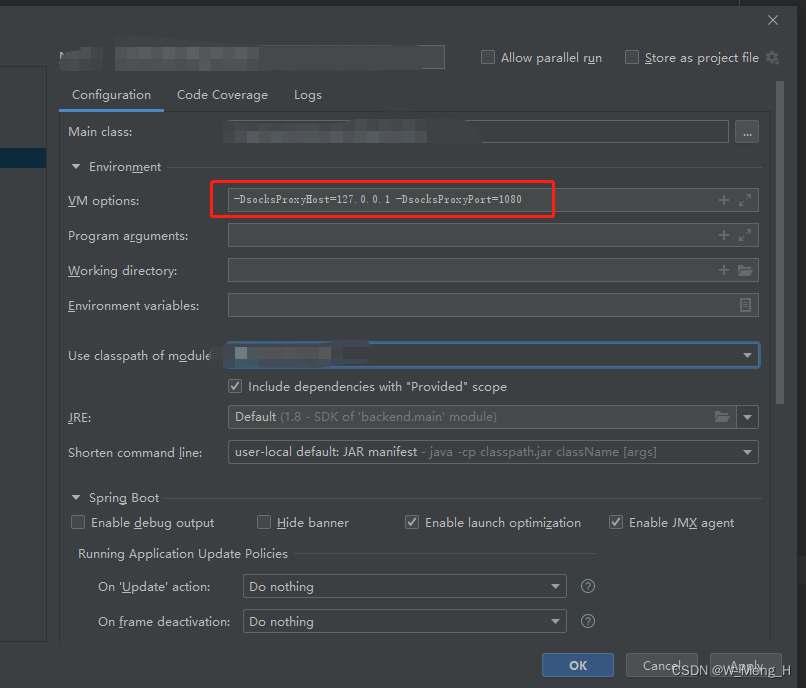
3、Java处理大文件
File file = new File(filePath);//需要读取的文件夹路径
File[] fileList = file.listFiles();
if (fileList.length == 0) {
System.out.println("目录下不存在文件");
}
for (int i = 0; i < fileList.length; i++) {
try {
String absolutePath = fileList[i].getAbsolutePath();
File files = new File(absolutePath);
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(files));
BufferedReader reader = new BufferedReader(new InputStreamReader(fis, "utf-8"), 5 * 1024 * 1024);
String line = "";
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}4、Broken pipe和Connection Reset by Peer的区别
 http://lovestblog.cn/blog/2014/05/20/tcp-broken-pipe/
http://lovestblog.cn/blog/2014/05/20/tcp-broken-pipe/1、tcpdump抓包工具
介绍了基础原理之后,再介绍下抓包工具,tcpdump,这工具对你了解tcp的整个过程会非常有帮助,在你无法调试tcp实现的情况下这个工具自然也是必不可少的,具体用法网上有很多介绍,直接从man page上也可以看到详细的介绍,我也不多说啦,下面的截图就是tcpdump根据tcp通信过程获取到的

这要稍微提下tcpdump的结果和上面的几个过程的对应关系 前面三条其实就是我们上面所说的三次握手,四次握手过程上面没有完全表现出来,只完成了一半的挥手过程(5,8两条表示的) 里面有几个标识S,F,ack,P,其实还有个R,如果有这些标识那么在tcp头里的SYN,FIN,ACK,PSH,RET分别为1,其中PSH表示要求tcp立即将数据传递给上层,不要做别的什么处理,RET这个表示重置连接,也是和我们今天讨论的问题有很大关系的FLAG,下面会详细介绍
2、reset报文发送场景
RST的标志位,这个标识为在如下几种情况下会被设置,以下是我了解的情况,可能还有更多的场景,没有验证
- 当尝试和未开放的服务器端口建立tcp连接时,服务器tcp将会直接向客户端发送reset报文
- 双方之前已经正常建立了通信通道,也可能进行过了交互,当某一方在交互的过程中发生了异常,如崩溃等,异常的一方会向对端发送reset报文,通知对方将连接关闭
- 当收到TCP报文,但是发现该报文不是已建立的TCP连接列表可处理的,则其直接向对端发送reset报文
- ack报文丢失,并且超出一定的重传次数或时间后,会主动向对端发送reset报文释放该TCP连接
3、异常模拟
从我的测试场景是这样的, 共同的前提是客户端向服务端发了数据之后立马调用close关闭socket并进程退出,而服务端在收到客户端的数据之后sleep一会,保证对方的socket已经关闭,接着分别进行两种场景测试
场景:
-
服务端往socket里写一次数据,返回继续做select
-
服务端连续写两次数据,必须保证两次的buffer都是有数据的,也就是保证ByteBuffer的pos和limit要不是一个值
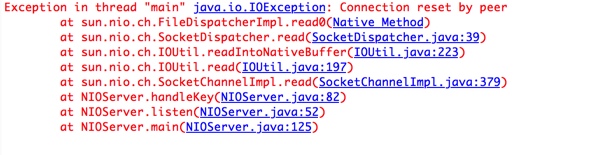
结果:
-
会抛出Connection reset by peer
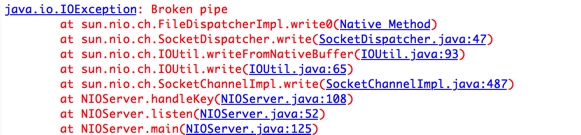
-
会抛出Broken pipe
分析:
-
当我们往一个对端已经close的通道写数据的时候,对方的tcp会收到这个报文,并且反馈一个reset报文,tcpdump的结果如下所示,当收到reset报文的时候,继续做select读数据的时候就会抛出
Connect reset by peer的异常,从堆栈可以看得出
-
当第一次往一个对端已经close的通道写数据的时候会和上面的情况一样,会收到reset报文,当再次往这个socket写数据的时候,就会抛出
Broken pipe了 ,根据tcp的约定,当收到reset包的时候,上层必须要做出处理,调用将socket文件描述符进行关闭,其实也意味着pipe会关闭,因此会抛出这个顾名思义的异常。
5、显示每个进程的上下文切换情况
pidstat -w -l -p 31981- PID:进程id
- Cswch/s:每秒主动任务上下文切换数量
- Nvcswch/s:每秒被动任务上下文切换数量
- Command:命令名
linux pidstat 命令详解 - jstarseven - 博客园
6、ModelMapper踩坑
 https://blog.youkuaiyun.com/K_Ohaha/article/details/82670758
https://blog.youkuaiyun.com/K_Ohaha/article/details/826707587、项目中引入外部Jar包(gradle)
dependencies {
dependencies { compile fileTree(dir:'libs',include:['*.jar'])}
}
8、关闭线程池,同时关停程序
public static ThreadPoolExecutor executor = new ThreadPoolExecutor(8, 10,
60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10000),
Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy());
try {
ThreadPoolUtil.executor.shutdown();
// ThreadPoolUtil.executor.awaitTermination(1, TimeUnit.MINUTES);
// isTerminated()判断子线程是否全部完成;完成 :true;没完成 :falese
while (true) {
if (ThreadPoolUtil.executor.isTerminated()) {
System.exit(0);
}
}
} catch (Exception e) {
log.error("线程关闭异常:{}",ExceptionUtils.getStackTrace(e));
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









