



 本文分析了InfluxDB在使用TSI索引时遇到的内存消耗问题,特别是SHR占用过高,以及由此导致的数据堆积。通过研究TSI原理、堆积原因和SHR的含义,提出了调整分片策略、关注读取端优化等解决方案,以提升InfluxDB的性能和稳定性。
本文分析了InfluxDB在使用TSI索引时遇到的内存消耗问题,特别是SHR占用过高,以及由此导致的数据堆积。通过研究TSI原理、堆积原因和SHR的含义,提出了调整分片策略、关注读取端优化等解决方案,以提升InfluxDB的性能和稳定性。
1.新的问题
influxdb目前支持内存型索引inmem及文件型索引tsi1。之前追踪篇将influxd索引修改为tsi1之后,经过一段时间的运行,从监控观察到,由于调用方采用异步队列+批处理的方案将数据写入influxdb,会在某些时刻调用方内部出现数据堆积,指标如图:
- 横坐标: 时间轴,从12-29 00:00 到 12-30 00:00
- 纵坐标: 队列中数据堆积长度,坐标最大值250k,即最大25w个数据堆积
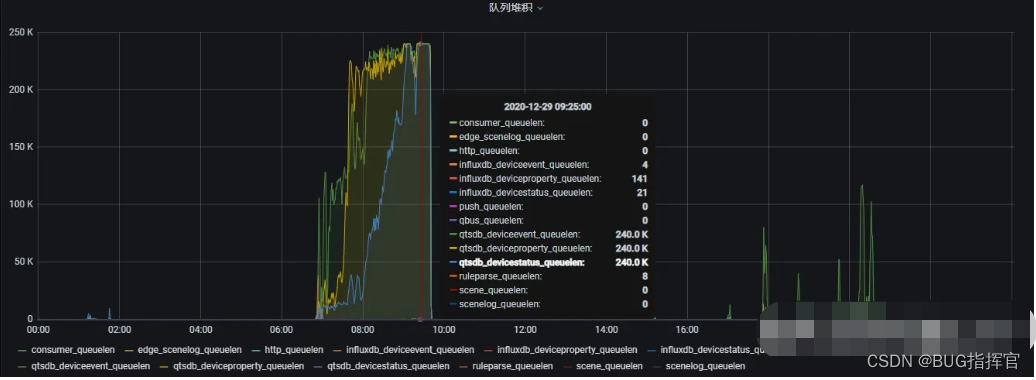
从上图可以看到,当天监控出现数次堆积,上午7:00-10:00尤为严重。在堆积时,登录influxdb服务器,查看机器状态如下:
top - 09:40:58 up 120 days, 19:18, 1 user, load average: 32.29, 32.32, 29.82
Tasks: 364 total, 1 running, 363 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.4 us, 0.1 sy, 0.0 ni, 57.7 id, 41.8 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 65433892 total, 376024 free, 30179144 used, 34878724 buff/cache
KiB Swap: 32833532 total, 32689404 free, 26624 used. 34607748 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9571 root 20 0 0.269t 0.053t 0.025t D 14.6 86.2 1081:18 influxd
在出现堆积时,wa很高,说明问题再次出现在磁盘io上,而且influxd的SHR空间占用了25g,又是为什么?
面对新出现的问题,当前的主要手段仍然是从influxdb配置文件入手,但是该如何优化?
2.tsi原理
工欲善其事,必先利其器。
查阅了相关资料之后,整理了influxdb使用tsi索引时原理图:
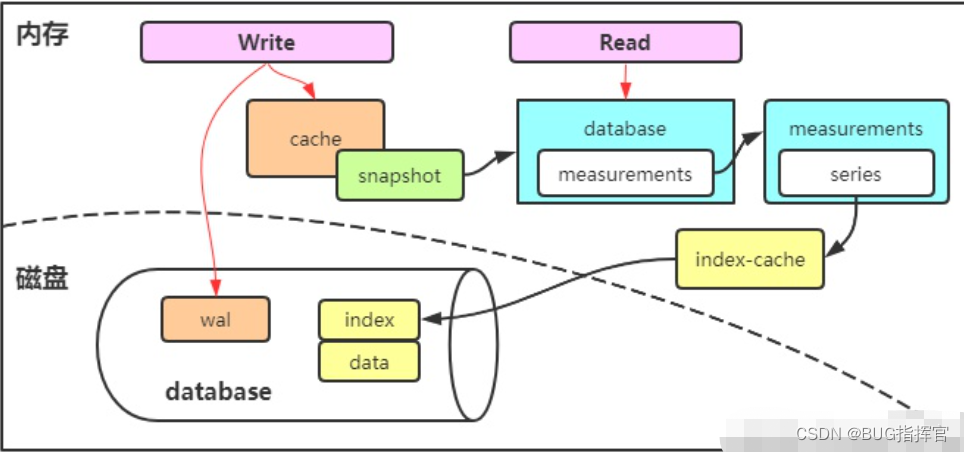
说明:
- 写入influxdb时,会同时写wal文件及cache内存, wal用于宕机恢复cache
- cache在达到配置中的阈值时,会进行snapshot快照,进行落盘
- influxdb的series及index索引会在内存中全量保存,用于快速检索
- wal文件大小在达到配置中阈值时,会进行压缩转换到index索引
- influxdb会对磁盘数据文件{{index+data}}按照分片shard维度进行四次压缩(level1,2,3及full),以节约磁盘空间
3.堆积的原因
在队列堆积的时间点,经过多次对比influxdb的日志:
#调用方队列堆积时,influxdb的关键日志如下:
#influx开始执行第四次全量压缩策略,tsm1_strategy=full
ts=2021-01-05T10:30:02.049644Z lvl=info msg="TSM compaction (start)" log_id=0RVRbtjl000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0RWXOKGG000 op_name=tsm1_compact_group op_event=start
...
#省略
...
#第四次全量压缩结束
ts=2021-01-05T10:44:13.931365Z lvl=info msg="TSM compaction (end)" log_id=0RVRbtjl000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0RWXOKGG000 op_name=tsm1_compact_group op_event=end op_elapsed=851881.724ms
...
...
此时influxdb进行分片数据的第四次的全量压缩,会进行大量的磁盘io及cpu压缩计算,导致服务的压力增大,所以调用方队列出现数据堆积,相关参数见配置文件:
#influxdb部分配置文件
#描述:内存快照的冷冻写入周期,默认10m
#场景: 当创建新的shard分片开始接受数据之后,上个shard分片进入冷冻期,
#冷冻期的shard分片不再接收写入的请求,10分钟之后,会将内存里冷冻shard的cache进行落盘操作
#应用: 本文设置为30分钟。个人认为时间越短,会越快释放上个shard的内存cache
cache-snapshot-write-cold-duration = "30m"
#描述: 使用全量策略压缩冷冻期分片的周期,默认4h
#场景: 当shard进入冷冻期后,会经过4h,开始进行全量压缩策略,进一步减少shard落盘数据占用的空间
#与cache-snapshot-write-cold-duration配合使用
#可以从日志中看到,新分片开始写入数据之后,在4h+10m之后,会对上个分片进行全量压缩策略
#应用: 本文设置为80小时。目的是不进行full压缩策略,来避免io过多消耗,后面会介绍由于设置的retention policy为72小时,所以此处大于72即可。
compact-full-write-cold-duration = "80h"
#描述: 最大并行压缩数,默认会使用golang的逻辑处理器的一半
#场景: 当进行level1,level2,level3及full策略压缩文件时使用的处理器数量,
#当前服务器为16core32物理线程,则会在压缩时默认使用16个处理器
#应用: 本文设置为8。用于减轻压缩策略时,cpu与磁盘io的压力,但相应的会导致压缩周期变长。
max-concurrent-compactions = 8
#描述: 压缩文件时,每秒写入磁盘的数据量,默认48MB
#应用:本文设置为16MB,用于减轻磁盘写入时的压力,同样会导致压缩周期变长。
compact-throughput = "16m"
#描述: 压缩文件时,每秒最大写入磁盘的峰值数据量,默认48MB
#应用:本文设置为16MB,用于减轻磁盘写入时的压力,同样会导致压缩周期变长。
compact-throughput-burst = "16m"
4.SHR占用
在本文第1小节中,使用linux的top命令可以看到,influxd进程占用RES内存为53g, SHR内存为25g。所以引申问题:
- 何为SHR?
- 为什么会有那么多的SHR?
- SHR对系统有什么影响?
使用man查看top命令的解释:
SHR – Shared Memory Size (KiB)
The amount of shared memory available to a task, not all of which is typically resident. It simply reflects memory that could be potentially shared with other processes.
共享内存的大小
程序共享内存的数据量,并不是全部驻留在内存空间,通常反映了与其他程序潜在共用的内存。
那为什么influxd会有那么高的共享内存?通过linux进程smaps分析当前实际占用内存的大小。
注: smaps中有些文件的引用仅占用虚拟内存,而不占用物理内存
#influxdb当前程序运行pid为: 9571
#1.计算influxdb数据文件通过shr占用物理内存大小,筛选出内存占用大于10m的文件:
> cat /proc/9571/smaps | sed -n '/rp_iot_cloud/,+2p' | grep -v 'Size:' | sed 's/\ kB//' | awk '{print $NF}' | awk 'BEGIN{i=-1}{i++;a[i]=$0}END{for(k=0;k<length(a);k=k+2) {if(a[k+1]/1000>10){m+=a[k+1]/1000;print a[k],a[k+1]/1000,m}}}'
--------- 文件名称 ---------------- 当前文件占用内存(MB) ----- 每行累计占用内存(MB) ----
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000640-000000010.tsm 550.148 550.148
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000640-000000009.tsm 322.392 872.54
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000640-000000008.tsm 228.524 1101.06
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000512-000000010.tsm 636.132 1737.2
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000512-000000009.tsm 336.532 2073.73
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000512-000000008.tsm 231.336 2305.06
...
#省略
...
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000384-000000005.tsm 560.716 17183.6
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000001209-000000002.tsm 315.204 17498.8
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000001216-000000001.tsm 55.644 17554.4
/data/influxdb/data/iot_cloud/rp_iot_cloud/233/000000256-000000005.tsm 514 18068.4
#2.计算influxdb索引series文件通过shr占用物理内存大小,筛选出内存占用大于10m的文件:
> cat /proc/9571/smaps | sed -n '/series/,+2p' | grep -v 'Size:' | sed 's/\ kB//' | awk '{print $NF}' | awk 'BEGIN{i=-1}{i++;a[i]=$0}END{for(k=0;k<length(a);k=k+2) {if(a[k+1]/1000>10){m+=a[k+1]/1000;print a[k],a[k+1]/1000,m}}}'
--------- 文件名称 ---------------- 当前文件占用内存(MB) ----- 每行累计占用内存(MB) ----
/data/influxdb/data/iot_cloud/_series/07/index 517.4 517.4
/data/influxdb/data/iot_cloud/_series/07/0007 99.032 616.432
/data/influxdb/data/iot_cloud/_series/07/0006 98.896 715.328
/data/influxdb/data/iot_cloud/_series/07/0005 62.732 778.06
...
#省略
...
/data/influxdb/data/iot_cloud/_series/01/0002 16.352 7014.15
/data/influxdb/data/iot_cloud/_series/00/0002 16.36 7030.51
可以看出程序运行时,会加载iot_cloud库文件:
- tsm数据文件(主要为当前shard的文件,共约18G)
- series文件(所有series文件,共约7G)
加载的内存大小与SHR内存基本吻合。基于当前的分片策略retention policy周期为7天,每天一分片,所以可以从分片角度减少shard占用的内存。笔者尝试调整分片策略:
#当前influxdb中数据库名
use iot_cloud
#修改保留策略为周期为3天,每2小时一分片
alter retention policy rp_iot_cloud on iot_cloud duration 3d REPLICATION 1 SHARD DURATION 2h default
调整为2小时一分片之后,SHR内存峰值会减少10-15g左右的占用。但是缩短分片间隔之后,influxdb会更频繁的进行内部自检及数据压缩,会造成cpu及磁盘io的消耗。所以继续考虑SHR占用较大对系统会有什么影响?
应用程序在启动之后,会共享系统一些内存:
- 堆内存(共享函数库消耗的堆空间)
- 文件缓存(从磁盘读取文件进行缓存)
对于共享堆内存则是必须占用的物理空间,而文件缓存则是系统针对磁盘读取的优化。目前influxdb在内存中引入了大量文件,在内存充足时,会占用较多的空间,用于提高程序读取性能。
5.SMP与NUMA?
cpu硬件体系架构可以分为:
- SMP(Symmetric Multi-Processor)/UMA(Uniform Memory Access)模式SMP架构,所有的CPU争用一个总线来访问所有内存,优点是资源共享,而缺点是总线争用激烈。 实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU
- NUMA(Non-Uniform Memory Access)模式NUMA架构引入了node和distance的概念。对于CPU和内存这两种最宝贵的硬件资源, NUMA用近乎严格的方式划分了所属的资源组(node),而每个资源组内的CPU和内存是几乎相等。
在influxdb服务器上,查看当前cpu及numa相关信息如下:
#lscpu用于查看当前cpu相关信息
> lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32 #共32个逻辑核数
On-line CPU(s) list: 0-31
Thread(s) per core: 2 #每个核心支持2个物理线程
Core(s) per socket: 8 #每个卡槽有8个核心
Socket(s): 2 #共2个卡槽,总共16个核心
NUMA node(s): 2 #共2个numa节点
...
...
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23 #numa节点分布
NUMA node1 CPU(s): 8-15,24-31
#numactl --hardware用于查看相关硬件信息
> numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 32365 MB #节点0分配内存为32G
node 0 free: 185 MB #节点0剩余内存185M
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 32768 MB #节点1分配内存为32G
node 1 free: 2492 MB #节点1剩余内存2492M
node distances:
node 0 1
0: 10 21
1: 21 10
#numastat查看当前状态
#miss值和foreign值越高,就要考虑绑定的问题。
> numastat
node0 node1
numa_hit 46726204589 16958785317
numa_miss 1636704898 11155932344 #numa_miss较高
numa_foreign 11155932344 1636704898
interleave_hit 22442 22958
local_node 46726202598 16958838294
other_node 1636706889 11155879367 #other_node较高
#numactl --show 用于查看当前numa策略
> numactl --show
policy: default #使用默认策略(localalloc)
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
cpubind: 0 1
nodebind: 0 1
membind: 0 1
通过查询,发现当前的numa策略会出现大量的miss。由于influxdb基于go语言开发,go语言社区中有关于 numa 感知调度的设计文档,但是本身的实现过于复杂,所以 go 语言团队在最新1.15版本还没有着手实现。目前根据相关资料,考虑influxdb运行时会占用大规模内存,建议通过如下方式启动influxdb:
numactl --interleave=all /usr/bin/influxd -config /usr/bin/influxdb.conf
6.读取端优化
从系统角度,应该同时关注influxdb写入和读取两个维度。
写入端应从具体业务场景,提前划分好写入的tags及fields,从而避免产生大量的series导致内存膨胀过快。而读取端,应明确查询时间范围,命中更少的分片数据,来防止加载大量的无用查询结果而导致程序OOM。
走查了读取端相关influxdb查询语句,发现几处类似如下消耗内存及性能的语句:
#表描述
- 表名: table
- tags: productKey,deviceName
- fields: identifier
#修改之前的sql
#由于没有时间范围,会导致查询所有shard数据,并从磁盘加载到内存,最后进行排序
select * from table where productKey=? and deviceName=? and identifier=? order by time desc limit 1
#优化之后的sql
#根据业务场景,此处可以仅查询最近2小时内的数据,避免全分片
select * from table where time > now()-2h and productKey=? and deviceName=? and identifier=? order by time desc limit 1
7.总结
本文整理了业务中使用influxdb遇到的问题,并提出了一些优化方案。目前来看,influxdb对于笔者仍然是一个黑盒程序,更细致的内容就需要从源码追寻。
当前采用了如下方式进行优化(由于需要对配置参数,策略各方面权衡,这是一个持续的过程):
(1) retention policy
#将保留策略修改为:3天一周期;1天一分片
alter retention policy rp_iot_cloud on iot_cloud duration 3d REPLICATION 1 SHARD DURATION 1d default
(2) 配置文件
#influxdb配置文件,主要参数如下:
[data]
#wal日志落盘周期,官方建议0-100ms
#尝试了100ms,50ms,20ms之后,目前折中采用50ms
wal-fsync-delay = "50ms"
#使用tsi1索引
index-version = "tsi1"
#分片允许最大内存,当超过最大内存会拒绝写入
#内存越大,多个新老分片会占用更多的堆空间
cache-max-memory-size = "2g"
#当cache超过128m时,会进行快照落盘
cache-snapshot-memory-size = "128m"
#cache冷冻写入时间
cache-snapshot-write-cold-duration = "30m"
#进行全量压缩时间
#由于retention policy为72小时
#超过72小时,可以认为不进行全量压缩
compact-full-write-cold-duration = "80h"
#并行压缩处理器
max-concurrent-compactions = 8
#压缩每秒落盘数据量
compact-throughput = "16m"
#压缩每秒最大落盘数据量
compact-throughput-burst = "16m"
#wal日志超过128m时会被压缩为索引文件,并删除
max-index-log-file-size = "128m"
[monitor]
#关闭监控
store-enabled = false
(3) 程序启动
numactl --interleave=all env GODEBUG=madvdontneed=1 /usr/bin/influxd -config /usr/bin/influxdb.conf


















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









