







 本文介绍了一种基于视觉注意力模型(VAM)和Impdrop技术的图像特征融合方法,用于提升模型在图像识别任务中的鲁棒性和准确性。VAM能自动识别图像中的关键内容,Impdrop则通过引入随机性降低过拟合风险。
本文介绍了一种基于视觉注意力模型(VAM)和Impdrop技术的图像特征融合方法,用于提升模型在图像识别任务中的鲁棒性和准确性。VAM能自动识别图像中的关键内容,Impdrop则通过引入随机性降低过拟合风险。
上海交大在2017年10月份投放在arXiv上的一篇文章
这篇文章主要有两点:
(1)使用了Visual Attention Model(VAM),自动学习出在图像中的关键内容,减少背景的干扰。然后与通常网络提取出的特征图进行融合;
(2)特征融合时,提出一种Impdrop的手段,类似将element-wise和dropout结合的一种手段,提高模型的鲁棒性。
最终得到一个end-to-end的模型。
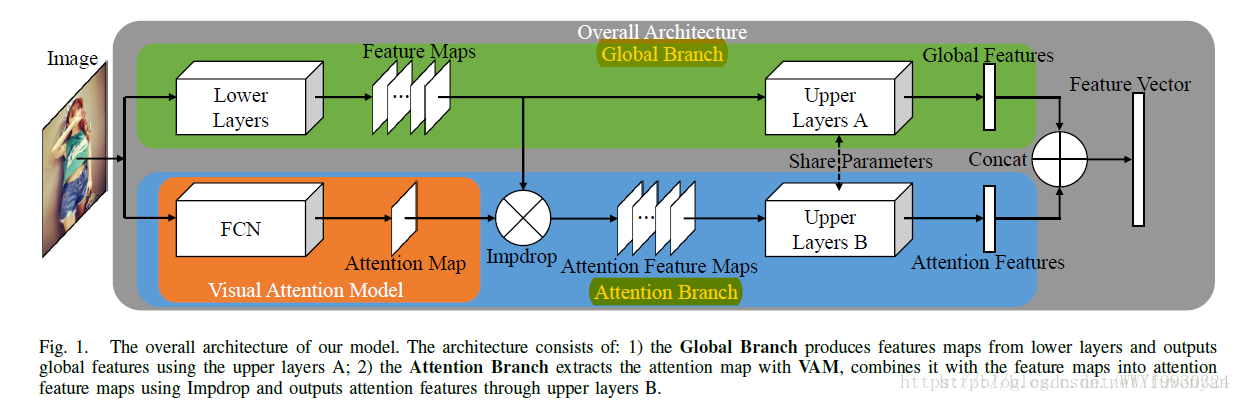
一张输入图片传送给两个分支,每个分支可以看做有两段。
上面的分支的前一段是普通的特征提取网络,能够得到特征图featureMaps;
下面分支的前一段使用纯卷积层的网络结构(FCN)生成Attention Map,含义就是图中哪些部分比对任务比较重要,这个过程称为Visual Attention Model(VAM);
在两个分支的中间,featureMaps和attentionMap会做一个融合,降低不重要的部分的相应,融合的方式就是本文提出的Impdrop,通过Impdrop就得到了一组Attention Feature maps,与上面分支前段得到的featureMaps的尺寸size相同。
两个分支的后一段,网络结构和大小相同,网络权值也是共享的,只是上面分支的输入是featureMaps,得到一个Global Features向量;而下面分支的输入是Attention Feature maps,得到Attention Features向量。
上下特征向量合并得到最终的feature Vector。
整个网络可以基于triplet loss用end-to-end的方式训练。
作者在服装语义分析和人体分割数据集上预训练了一个FCN模型,得到的输出attention map都是0~1的数,表示对应原始图片区域的重要程度。
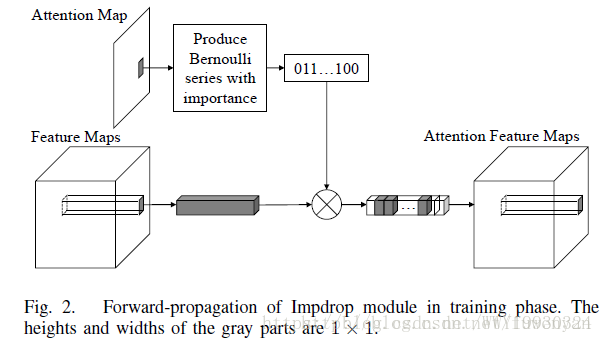
Impdrop与product乘积相比,由于引入了随机性,降低了网络过拟合的风险,使模型更具鲁棒性。尤其在小规模数据训练时能够优于乘积的方式。
实验部分:
基于其他论文的数据和网络结构预训练了一个VAM,然后再DeepFashion和Street2Shop数据集上进行finetuning
由于使用了triplet loss,因此创建了positive pairs和negative pairs。
使用了top-K的方式进行精度评估。
使用了googlenet和VGG16架构,VAM使用了ResNet架构,生成28*28的attention map
实验结果
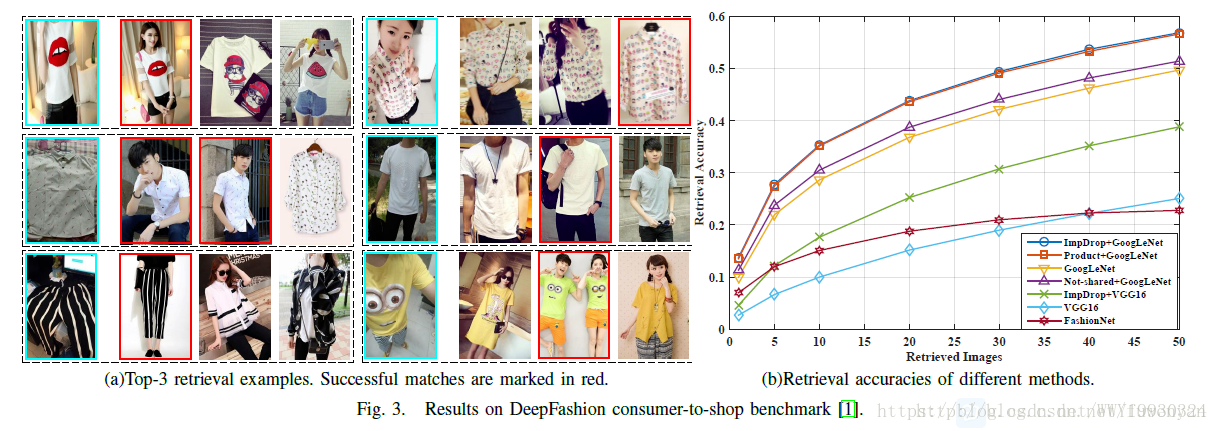
从上图可以看出基于GoogleNet的架构效果比VGG16架构的要好一些,同样基于VGG16,本文的方法也比FashionNet好一些,有意思的是,基于GoogleNet架构,采用ImpDrop和采用product两种融合方式,精度基本是相同的。
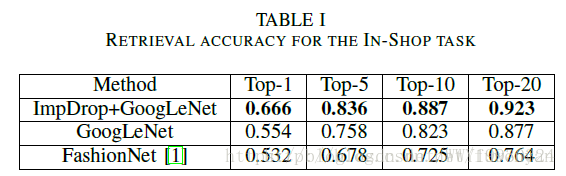
在DeepFashion in-shop数据集上的测试结果对比:
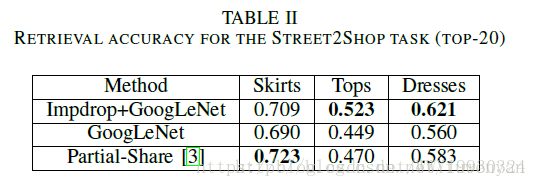
在street2shop数据集上的测试结果对比:
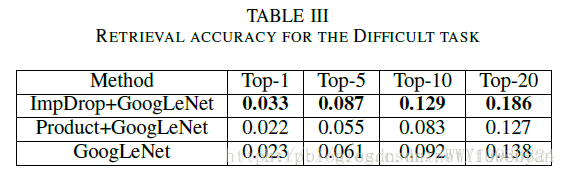
使用较大triplet loss margin创造较为困难的情况来比较ImpDrop和product的性能区别,文中说ImpDrop比product更具鲁棒性。
总结:
网络结构比较简单易懂,原理也算简单。核心思想是应用visual attention model和如何融合attention feature与普通的特征。
不过Impdrop的公式部分没太理解,不过看实验结果,感觉其实采用product的方式也没有问题的。

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









