 Java优先级队列(PriorityQueue)原理与应用
Java优先级队列(PriorityQueue)原理与应用





目录
 http://t.csdn.cn/rJ8fM
http://t.csdn.cn/rJ8fM1.概念
在很多应用中,我们通常需要按照优先级情况对待处理对象进行处理,比如首先处理优先级最高的对象,然后处理次高的对象。
在这种情况下,数据结构应该提供2个最基本的操作:一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
2.内部原理
优先级队列的实现方式很多,最常见的是用堆来构建。其底层是基于堆来实现的,仍满足队列的3大操作。(还是队列,不过套了堆的包装)。
3.操作
- 入队列:调用堆的add方法。
- 出队列:按照优先级出队列,优先级最高的先出(堆顶元素),调用堆的extractMax方法。
- 查看队首元素:即堆顶元素。
4.应用
- 医生排患者手术名单,优先级就是病情严重程度,相同严重程度再看时间先后。
- 操作系统的作业(进程/任务)调度。
5.代码实现
import heap.MaxHeap;
public class PriorityQueue implements Queue {
private MaxHeap heap = new MaxHeap();
@Override
public void offer(int value) {
heap.add(value);
}
@Override
public int poll() {
return heap.extractMax();
}
@Override
public int peek() {
return heap.peekHeap();
}
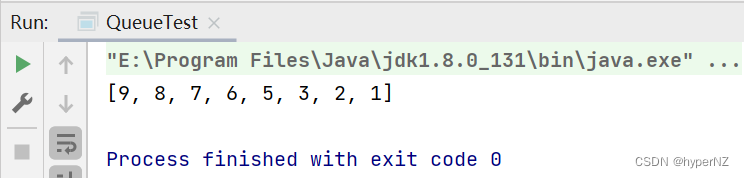
}import java.util.Arrays;
public class QueueTest {
public static void main(String[] args) {
int[] arr = {3, 5, 2, 1, 7, 6, 9, 8};
Queue queue = new PriorityQueue(); //降序排列
for(int i : arr) {
queue.offer(i);
}
for (int i = 0; i < arr.length; i++) {
arr[i] = queue.poll();
}
System.out.println(Arrays.toString(arr));
}
}
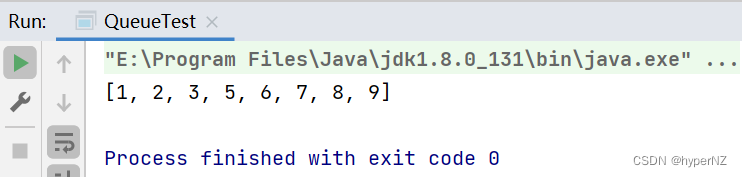
import java.util.Arrays;
import java.util.PriorityQueue;
public class QueueTest {
public static void main(String[] args) {
int[] arr = {3, 5, 2, 1, 7, 6, 9, 8};
PriorityQueue<Integer> queue = new PriorityQueue<>(); //升序排序,JDK中的PriorityQueue是基于最小堆实现的
// Queue queue = new PriorityQueue(); //降序排列
for(int i : arr) {
queue.offer(i);
}
for (int i = 0; i < arr.length; i++) {
arr[i] = queue.poll();
}
System.out.println(Arrays.toString(arr));
}
}
PS:源码分析:
private void siftUp(int k, E x) { if (comparator != null) siftUpUsingComparator(k, x); else siftUpComparable(k, x); }当使用JDK的优先级队列时,若传入的是自定义类型,如Student,
- 要么向优先级队列中传入该类的比较器。
public PriorityQueue(Comparator<? super E> comparator) { this(DEFAULT_INITIAL_CAPACITY, comparator); }
- 要么自定义的类型实现了Comparable接口。
JDK内置的类,如String,包装类等都默认是Comparable的子类。
private void siftUpComparable(int k, E x) { Comparable<? super E> key = (Comparable<? super E>) x; while (k > 0) { int parent = (k - 1) >>> 1; Object e = queue[parent]; if (key.compareTo((E) e) >= 0) break; queue[k] = e; k = parent; } queue[k] = key; }e是父节点的值,key是子节点的值。if分支说明当前节点 >= 父节点,停止。
父节点 < 子节点,堆顶存放的就是最小值,最小堆。
要想通过CompareTo方法改造为最大堆,则this.val < o.val =>return 1;
根据JDK代码,就把小的值留在子节点,大的值跑上面了,变为最大堆。
6.TOP-K问题
问题:在100w个集合中,找到前100大的元素值。
解决:
①建一最大堆,然后返回100次堆顶。时间复杂度O(n) + O(klogk);空间复杂度O(n)。
②排序。时间复杂度O(nlogn);空间复杂度O(1)。
③TOP-K问题:
取大构建小堆,取小构建大堆。
取大用小堆核心:
相当于打擂过程,声明一个大小为100的最小堆,然后依次扫描此集合与堆顶元素比较。
- 若队列中元素个数<100,直接入队。
- 若队列中元素个数>100,比较当前扫描元素和堆顶元素的大小:
- 若扫描元素<堆顶元素,则一定小于堆中所以元素,跳过。
- 若扫描元素>堆顶元素,将当前堆中最小值(堆顶元素)换出,换一个更“优秀”的元素(扫描元素)进来。

n是元素个数,前k大元素:时间复杂度O(nlogk)(n扫描所有数,logk构建取出堆);空间复杂度O(k)(开k个大小的堆,一般k << n)。
④快排partition思想。(最优解)时间复杂度O(n)。

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









