




目录
2.2.10.根据index与size的大小关系快速定位指定index位置的节点
1.定义
既要存储下一个节点地址,还要存储前一个节点地址。是Java的集合框架中LinkedList底层实现。

2.代码
2.1.车厢类
/**
* 车厢类
*/
class DoubleNode{
//指向前驱节点
DoubleNode prev;
//存储的具体元素
int val;
//指向后继节点
DoubleNode next;
//有参构造
public DoubleNode(int val){
this.val=val;
}
}2.2.火车类
/**
* 火车类 基于int的双向链表
*/
public class DoubleLinkedList {
//存储的具体车厢个数
private int size;
//头节点
private DoubleNode first;
//尾节点
private DoubleNode last;
//具体方法实现
//...
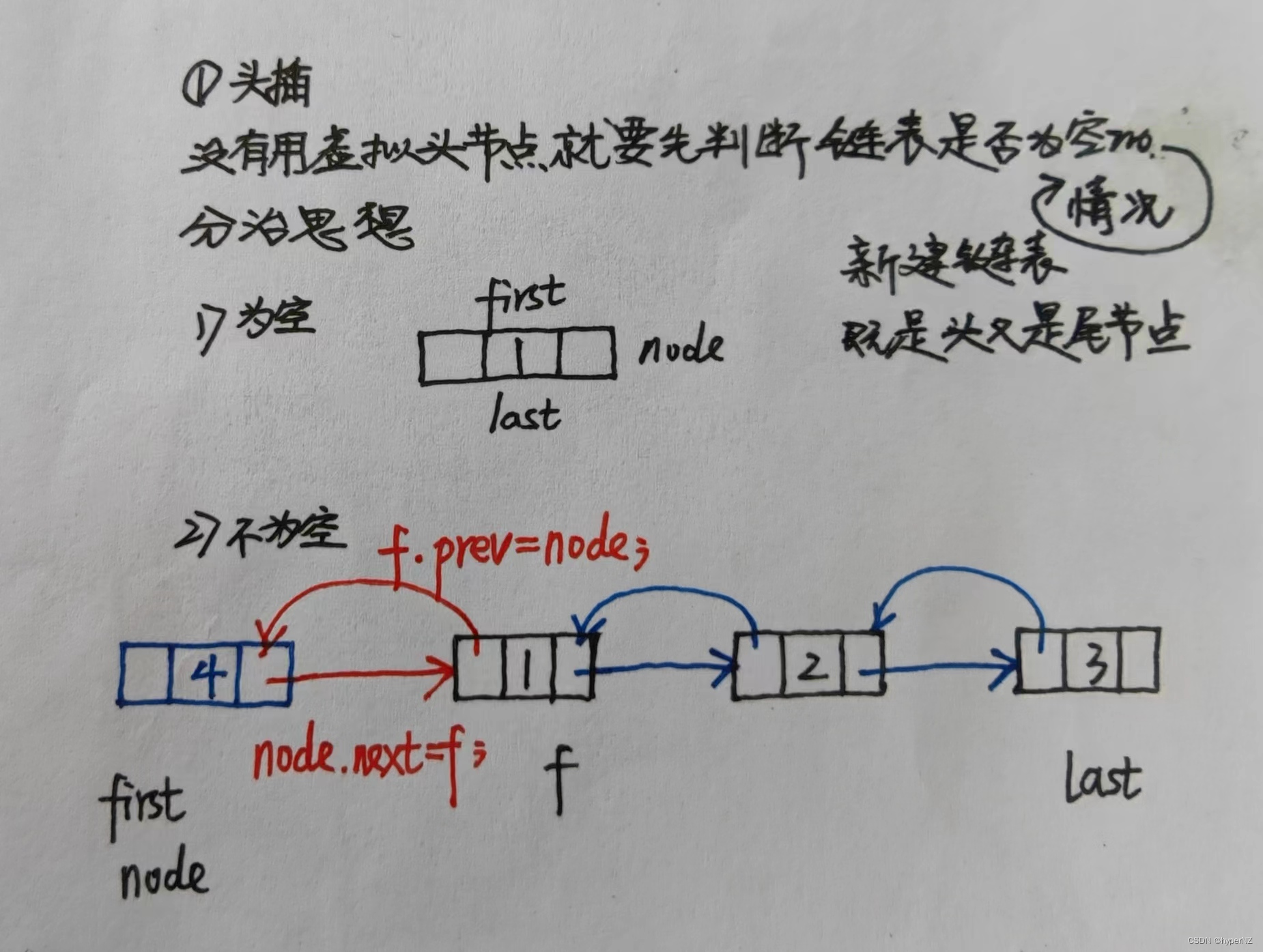
}2.2.1.在链表的头部添加节点
/**
* 头插
* @param val
*/
public void addFirst(int val) {
//引入一个局部变量,暂时存储一下头节点的地址
DoubleNode f = first;
//要插入一个节点,首先要new一个节点
DoubleNode node = new DoubleNode(val);
first = node; //因为是头插,那么这行代码不管当前链表是否为空都会执行
if(f == null) { //若链表为空,则新建的节点既是头节点又是尾节点
last = node;
} else {
node.next = f;
f.prev = node;
}
size++;
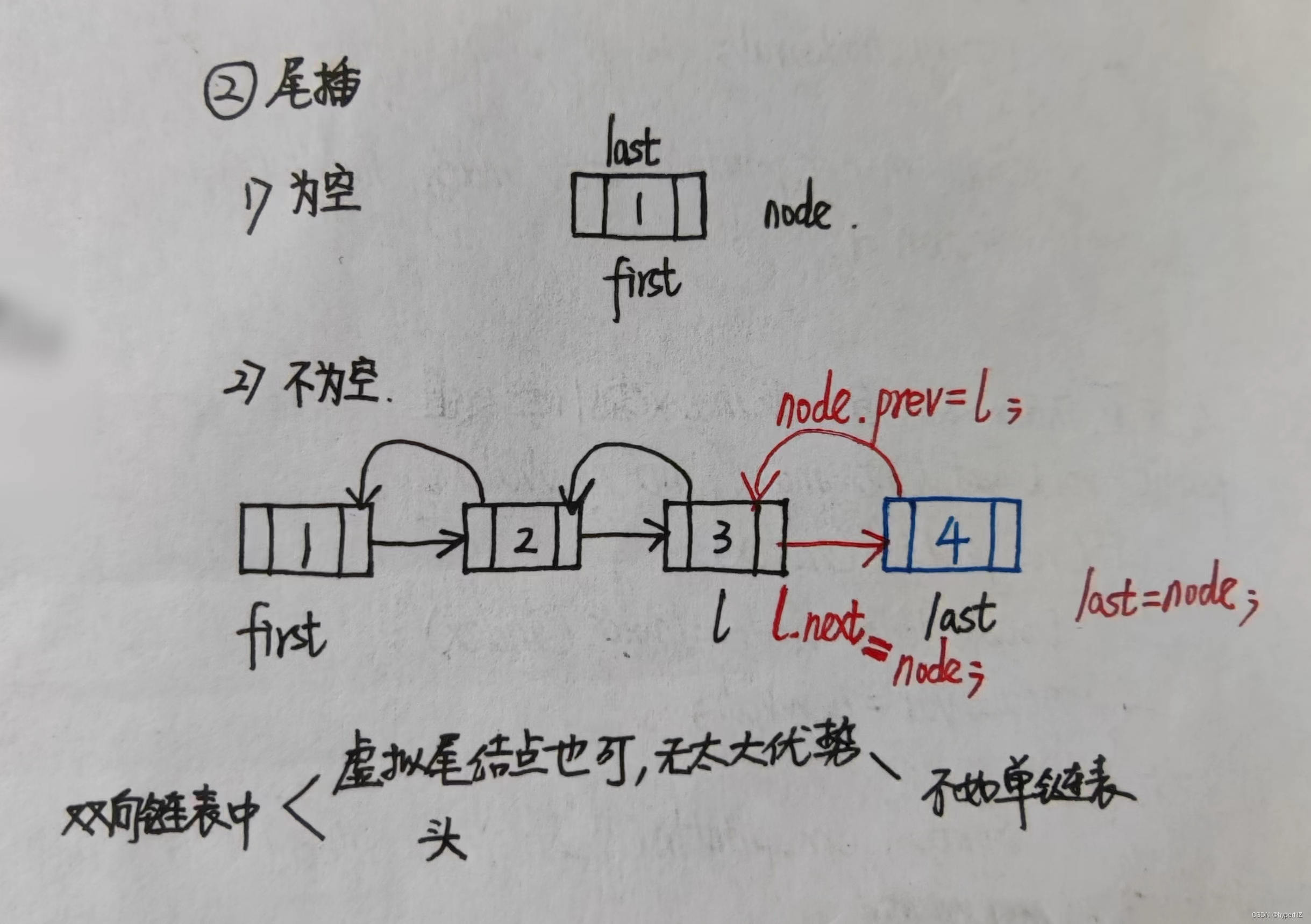
}2.2.2.在链表的尾部添加节点
/**
* 尾插
* @param val
*/
public void addLast(int val) {
//引入一个局部变量,暂时存储一下尾节点的地址
DoubleNode l = last;
DoubleNode node = new DoubleNode(val);
last = node;
if(l == null) {
first = node;
} else {
node.prev = l;
l.next = node;
}
size++;
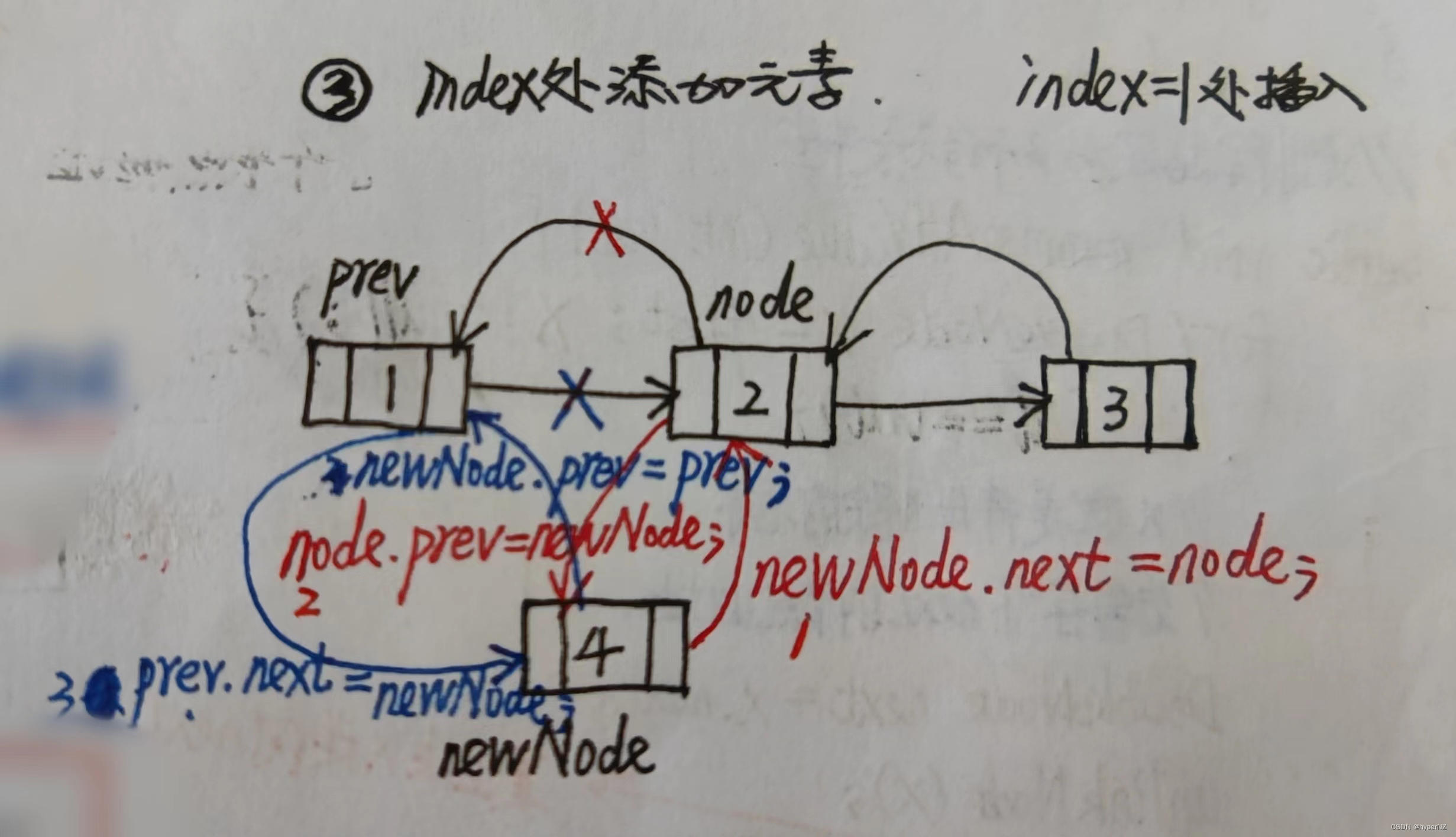
}2.2.3.在链表的任意位置index处添加节点
/**
* 任意index处添加元素
* @param val
*/
public void addIndex(int index, int val) {
if(index < 0 || index > size) {
System.err.println("add index illegal!");
return;
} else if(index == 0) {
addFirst(val);
} else if(index == size) {
addLast(val);
} else {
//此时0 < index < size
//在报错方法(未写)上使用快捷键Alt+Enter,自动生成指定方法
DoubleNode node = node(index);
//指向当前位置的前驱节点
DoubleNode prev = node.prev;
//要插入的新节点
DoubleNode newNode = new DoubleNode(val);
//先处理后半部分引用链
newNode.next = node; ①
node.prev = newNode; ②
//再处理前半部分引用链
prev.next = newNode; ③
newNode.prev = prev; ④
size++;
}
}
2.2.4.查询链表的任意位置index处的节点值
/**
* 根据index索引取得节点值
* @param index
* @return
*/
public int get(int index) {
if(rangeCheck(index)) {
DoubleNode node = node(index);
return node.val;
} else {
System.out.println("get index illegal!");
return -1;
}
}2.2.5.修改链表中任意位置index处的节点值
/**
* 修改index处的值为newVal
* @param index
* @param newVal
*/
public void set(int index, int newVal) {
if(rangeCheck(index)) {
DoubleNode node = node(index);
node.val = newVal;
} else {
System.out.println("set index illegal!");
}
}2.2.6.传入一个双向链表节点,将该节点从双向链表中删除
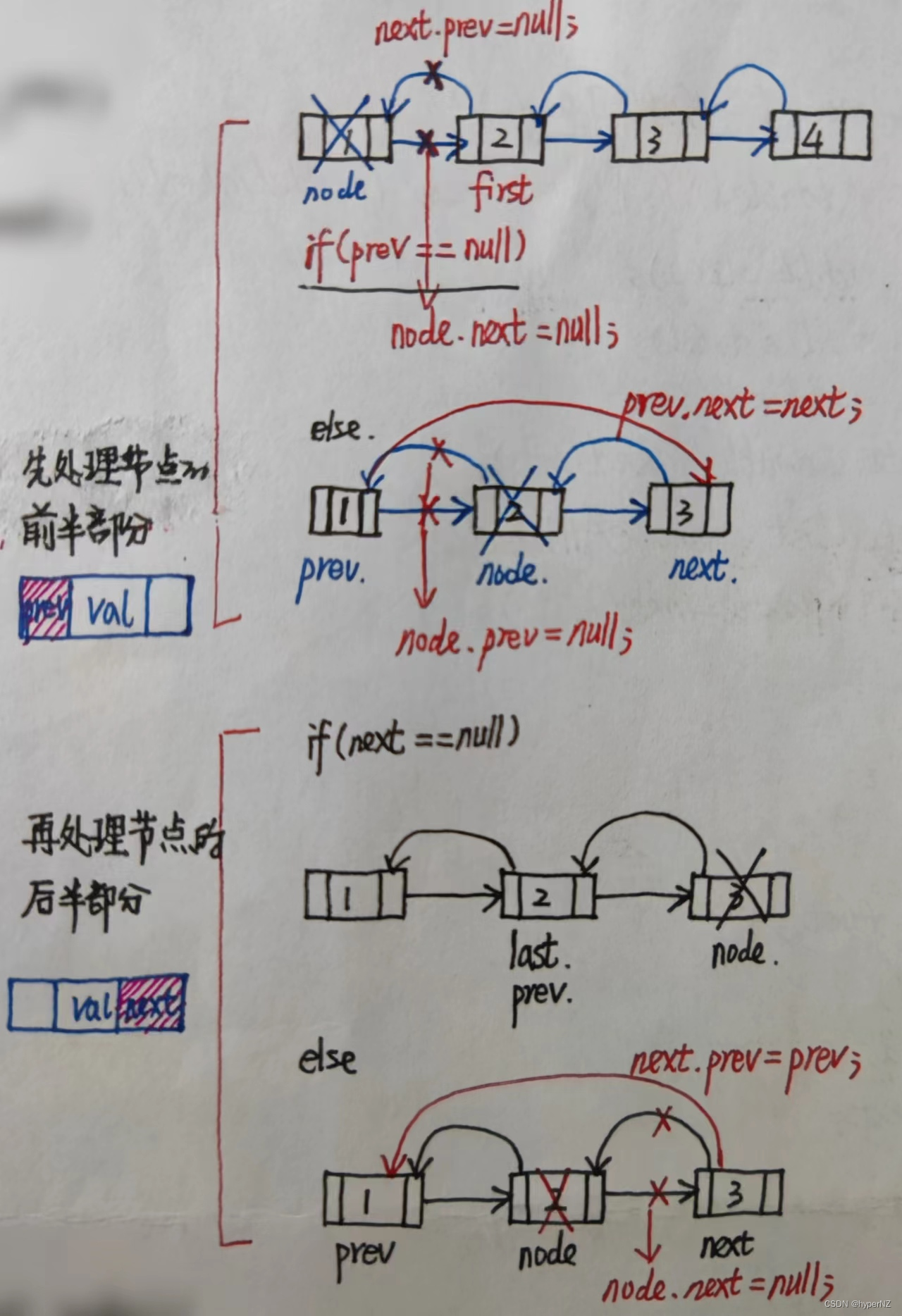
/**
* 传入一个双向链表节点,将该节点从双向链表中删除
* 核心思想 分治,先处理前驱或后继,再处理另一半的情况
* @param node
*/
private void unlinkNode(DoubleNode node) {
//待删除节点的前驱
DoubleNode prev = node.prev;
//待删除结点的后继
DoubleNode next = node.next;
//先处理前半部分引用链
//判断边界
if(prev == null) {
//说明此时待删除的节点恰好是头节点
first = next;
} else {
//此时前驱节点不为空
prev.next = next;
node.prev = null;
}
//再处理后半部分引用链
if(next == null) {
last = prev;
} else {
//此时后继节点不为空
next.prev = prev;
node.next = null;
}
size--;
}2.2.7.删除链表中第一次出现某个值的节点
/**
* 删除第一次出现值为val的元素
* @param val
*/
public void removeValueOnce(int val) {
//只需要从头开始遍历
for (DoubleNode x = first; x != null; x = x.next) {
if(x.val == val) {
unlinkNode(x);
return;
}
}
}2.2.8.删除链表中值为val的所有节点
/**
* 删除单链表中所有值为val的节点
* @param val
*/
public void removeAllValue(int val) {
for(DoubleNode x = first; x != null;) {
if(x.val == val){
//x就是待删除的元素
//先暂存一下next的节点地址
DoubleNode next = x.next;
unlinkNode(x);
x = next; //真正让x走向next
} else {
x = x.next;
}
}
}2.2.9.判断链表的index是否合法
/**
* 判断链表的index是否合法
* @param index
* @return
*/
private boolean rangeCheck(int index) {
if(index < 0 || index >= size) {
return false;
}
return true;
}2.2.10.根据index与size的大小关系快速定位指定index位置的节点
/**
* 根据index与size的大小关系快速定位指定index位置的节点
* @param index
* @return
*/
private DoubleNode node(int index) {
if(index < size >> 1) {
//从头向后
DoubleNode node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
} else {
//从后向前
DoubleNode node = last;
for (int i = size-1; i > index; i--) {
node = node.prev;
}
return node;
}
}2.2.11.toString()方法
public String toString() {
String ret = "";
DoubleNode node = first;
while(node != null) {
ret += node.val + "->";
node = node.next;
}
ret += "NULL";
return ret;
}2.3.总代码实现
/**
* 车厢类
*/
class DoubleNode{
//指向前驱节点
DoubleNode prev;
//存储的具体元素
int val;
//指向后继节点
DoubleNode next;
//有参构造
public DoubleNode(int val){
this.val=val;
}
}
/**
* 火车类 基于int的双向链表
*/
public class DoubleLinkedList {
//存储的具体车厢个数
private int size;
//头节点
private DoubleNode first;
//尾节点
private DoubleNode last;
/**
* 头插
* @param val
*/
public void addFirst(int val){
//引入一个局部变量,暂时存储一下头节点的地址
DoubleNode f=first;
//要插入一个节点,首先要new一个节点
DoubleNode node=new DoubleNode(val);
first=node;
if(f==null){
last=node;
}else{
node.next=f;
f.prev=node;
}
size++;
}
/**
* 尾插
* @param val
*/
public void addLast(int val) {
//引入一个局部变量,暂时存储一下尾节点的地址
DoubleNode l = last;
DoubleNode node = new DoubleNode(val);
last = node;
if(l == null) {
first = node;
} else {
node.prev = l;
l.next = node;
}
size++;
}
/**
* 任意index处添加元素
* @param val
*/
public void addIndex(int index, int val) {
if(index < 0 || index > size) {
System.err.println("add index illegal!");
return;
} else if(index == 0) {
addFirst(val);
} else if(index == size) {
addLast(val);
} else {
//此时0 < index < size
//在报错方法(未写)上使用快捷键Alt+Enter,自动生成指定方法
DoubleNode node = node(index);
//指向当前位置的前驱节点
DoubleNode prev = node.prev;
//要插入的新节点
DoubleNode newNode = new DoubleNode(val);
//先处理后半部分引用链
newNode.next = node;
node.prev = newNode;
//再处理前半部分引用链
prev.next = newNode;
newNode.prev = prev;
size++;
}
}
/**
* 根据index索引取得节点值
* @param index
* @return
*/
public int get(int index) {
if(rangeCheck(index)) {
DoubleNode node = node(index);
return node.val;
} else {
System.out.println("get index illegal!");
return -1;
}
}
/**
* 修改index处的值为newVal
* @param index
* @param newVal
*/
public void set(int index, int newVal) {
if(rangeCheck(index)) {
DoubleNode node = node(index);
node.val = newVal;
} else {
System.out.println("set index illegal!");
}
}
/**
* 传入一个双向链表节点,将该节点从双向链表中删除
* 核心思想 分治,先处理前驱或后继,再处理另一半的情况
* @param node
*/
private void unlinkNode(DoubleNode node) {
//待删除节点的前驱
DoubleNode prev = node.prev;
//待删除结点的后继
DoubleNode next = node.next;
//先处理前半部分引用链
//判断边界
if(prev == null) {
//说明此时待删除的节点恰好是头节点
first = next;
} else {
//此时前驱节点不为空
prev.next = next;
node.prev = null;
}
//再处理后半部分引用链
if(next == null) {
last = prev;
} else {
//此时后继节点不为空
next.prev = prev;
node.next = null;
}
size--;
}
/**
* 删除第一次出现值为val的元素
* @param val
*/
public void removeValueOnce(int val) {
//只需要从头开始遍历
for (DoubleNode x = first; x != null; x = x.next) {
if(x.val == val) {
unlinkNode(x);
return;
}
}
}
/**
* 删除单链表中所有值为val的节点
* @param val
*/
public void removeAllValue(int val){
for(DoubleNode x=first;x!=null;){
if(x.val==val){
//x就是待删除的元素
//先暂存一下next的节点地址
DoubleNode next=x.next;
unlinkNode(x);
x=next;
}else{
x=x.next;
}
}
}
/**
* 根据index与size的大小关系快速定位指定index位置的节点
* @param index
* @return
*/
private DoubleNode node(int index) {
if(index < size >> 1) {
//从头向后
DoubleNode node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
} else {
//从后向前
DoubleNode node = last;
for (int i = size-1; i > index; i--) {
node = node.prev;
}
return node;
}
}
/**
* 判断链表的index是否合法
* @param index
* @return
*/
private boolean rangeCheck(int index) {
if(index < 0 || index >= size) {
return false;
}
return true;
}
public String toString() {
String ret = "";
DoubleNode node = first;
while(node != null) {
ret += node.val + "->";
node = node.next;
}
ret += "NULL";
return ret;
}
public static void main(String[] args) {
DoubleLinkedList doubleLinkedList=new DoubleLinkedList();
doubleLinkedList.addFirst(1);
doubleLinkedList.addFirst(2);
doubleLinkedList.addFirst(3);
doubleLinkedList.addLast(3);
doubleLinkedList.addLast(3);
doubleLinkedList.addLast(3);
//3->2->1->3->3->3->NULL
doubleLinkedList.addIndex(1,99);
//3->99->2->1->3->3->3->NULL
doubleLinkedList.removeValueOnce(99);
//3->2->1->3->3->3->NULL
doubleLinkedList.removeAllValue(3);
//2->1->NULL
System.out.println(doubleLinkedList);
}
}
















 5134
5134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









