<think>
我们注意到日志中出现了两次死锁重试,但还没有成功。我们需要进一步优化死锁处理策略,并考虑其他可能的优化措施。以下是一个更全面的解决方案:
### 优化方向:
1. **减小事务粒度**:将每个分块再拆分成更小的子分块进行提交
2. **调整隔离级别**:尝试使用更低的隔离级别(如READ COMMITTED)
3. **索引优化**:确保目标表的索引不会导致死锁(特别是主键和唯一索引)
4. **顺序写入**:按照主键顺序写入可能减少死锁
5. **超时设置调整**:增加锁等待超时时间
### 修改后的代码(关键部分):
```python
# 修改write_to_database函数,将每个分块拆分成更小的子分块
def write_to_database(df, engine, table_name, max_retries=5, sub_chunk_size=50):
"""数据库写入函数 - 子分块提交"""
total_written = 0
num_sub_chunks = (len(df) - 1) // sub_chunk_size + 1
for sub_idx in range(num_sub_chunks):
sub_start = sub_idx * sub_chunk_size
sub_end = min((sub_idx + 1) * sub_chunk_size, len(df))
sub_df = df.iloc[sub_start:sub_end]
for attempt in range(max_retries):
try:
# 获取目标表列名
inspector = inspect(engine)
target_columns = [col['name'] for col in inspector.get_columns(table_name)]
# 筛选存在的列
existing_columns = [col for col in sub_df.columns if col in target_columns]
filtered_sub_df = sub_df[existing_columns]
# 写入数据库
with engine.begin() as connection:
filtered_sub_df.to_sql(
name=table_name,
con=connection,
if_exists='append',
index=False,
chunksize=50, # 使用较小的chunksize
method='multi'
)
written_count = len(filtered_sub_df)
total_written += written_count
break # 成功则跳出重试循环
except OperationalError as e:
error_msg = str(e).lower()
if ("deadlock" in error_msg or "lock wait timeout" in error_msg) and attempt < max_retries - 1:
wait_time = (2 ** attempt) + 0.5
logging.warning(f"死锁/锁超时,等待{wait_time:.2f}秒后重试子分块 {sub_idx+1}/{num_sub_chunks} (尝试 {attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
logging.error(f"子分块 {sub_idx+1} 写入失败: {str(e)}")
# 备份失败的子分块
backup_path = os.path.join(OUTPUT_DIR, f"error_subchunk_{sub_idx+1}.csv")
sub_df.to_csv(backup_path, index=False)
logging.warning(f"失败子分块已保存至: {backup_path}")
raise
except SQLAlchemyError as e:
logging.error(f"数据库错误: {str(e)}")
if attempt < max_retries - 1:
wait_time = 1 + attempt
logging.info(f"等待{wait_time}秒后重试")
time.sleep(wait_time)
else:
backup_path = os.path.join(OUTPUT_DIR, f"error_subchunk_{sub_idx+1}.csv")
sub_df.to_csv(backup_path, index=False)
logging.warning(f"失败子分块已保存至: {backup_path}")
raise
return total_written
```
### 完整修改后的代码:
```python
import os
import json
import logging
import traceback
import time
import pandas as pd
import random
from datetime import datetime
from sqlalchemy import create_engine, inspect
from sqlalchemy.exc import OperationalError, SQLAlchemyError
from dotenv import load_dotenv
# 初始化日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler("bsw_task_jira_deal.log"),
logging.StreamHandler()
]
)
# 加载环境变量
load_dotenv()
# 输出文件配置
OUTPUT_DIR = r"D:\AEB Management\output"
OUTPUT_FILE = "processed_data.csv"
os.makedirs(OUTPUT_DIR, exist_ok=True)
# ------------------ 配置加载 ------------------
def load_config(config_path):
"""加载 JSON 配置文件为字典"""
try:
with open(config_path, "r", encoding="utf-8") as file:
config = json.load(file)
logging.info(f"成功加载配置文件: {config_path}")
return config
except Exception as e:
logging.error(f"加载配置文件失败: {str(e)}")
logging.error(traceback.format_exc())
return {
"default_responsible": "管理员",
"default_email": os.getenv("DEFAULT_EMAIL", "admin@example.com")
}
# ------------------ 数据列处理 ------------------
def add_columns(dataframe, bsw_staff_set):
"""根据业务规则动态添加新列"""
current_time = pd.Timestamp.now()
# 添加基础列
dataframe['HorizontalExpansion PN'] = None
# 1. KOCHI_PL 项目处理逻辑
kochi_condition_include = (
(dataframe['Project key'] == 'KOCHI_PL') &
(dataframe['Labels'].str.contains('CheckItOnOtherProject', na=False))
)
kochi_condition_exclude = (
(dataframe['Project key'] == 'KOCHI_PL') &
(~dataframe['Labels'].str.contains('CheckItOnOtherProject', na=False))
)
if kochi_condition_include.any():
extracted_projects = dataframe.loc[kochi_condition_include, 'Summary'].str.extract(r'(P\d{5})', expand=False)
dataframe.loc[kochi_condition_include, 'HorizontalExpansion PN'] = extracted_projects
valid_extraction = extracted_projects.notna()
dataframe.loc[kochi_condition_include & valid_extraction, 'Project key'] = extracted_projects[valid_extraction]
if kochi_condition_exclude.any():
dataframe.loc[kochi_condition_exclude, 'Project key'] = 'noneed'
# 2. 核心业务分析列
# ProjectNum
dataframe['ProjectNum'] = dataframe['Project key']
# BSW Self Test
def is_bsw_self_test(row):
if row['Involvement of BSW'] != 'Yes':
return 0
found_by = row.get('Custom field (Found By)', '')
labels = row.get('Labels', '')
cond1 = found_by in ['Development Audit', 'Review', 'SW Unit Test', 'Development']
cond2 = (found_by == 'SW Integration Test') and ('BSW_IT' in labels)
return 1 if cond1 or cond2 else 0
dataframe['BSW Self Test'] = dataframe.apply(is_bsw_self_test, axis=1)
# BSW Issue
def is_bsw_issue(row):
if not (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes'):
return 0
custom_field = str(row.get('Custom field (Custom_2)', ''))
keywords = ['平台问题', '开发设计问题', '三方包问题',
'Development Design Issue', 'Platform Issue', 'Party Package Issue']
return 1 if any(keyword in custom_field for keyword in keywords) else 0
dataframe['BSW Issue'] = dataframe.apply(is_bsw_issue, axis=1)
# Stack BSW Analyzed
def is_stack_analyzed(row):
if not (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes'):
return 0
components = str(row.get('Component/s', ''))
custom_field = str(row.get('Custom field (Custom_2)', ''))
cond1 = 'Stack' in components
cond2 = '非BSW问题' in custom_field or 'Non-BSW' in custom_field
return 1 if cond1 or cond2 else 0
dataframe['Stack BSW Analyzed'] = dataframe.apply(is_stack_analyzed, axis=1)
# Stack BSW Unanalyzed
def is_stack_unanalyzed(row):
if not (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes'):
return 0
components = str(row.get('Component/s', ''))
custom_field = str(row.get('Custom field (Custom_2)', ''))
cond1 = 'Stack' in components
cond2 = '非BSW问题' in custom_field or 'Non-BSW' in custom_field
return 1 if not (cond1 or cond2) else 0
dataframe['Stack BSW Unanalyzed'] = dataframe.apply(is_stack_unanalyzed, axis=1)
# Stack Total
dataframe['Stack Total'] = dataframe.apply(
lambda row: 1 if (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
'Stack' in str(row.get('Component/s', ''))) else 0,
axis=1
)
# BSW Involve
dataframe['BSW Involve'] = dataframe.apply(
lambda row: 1 if (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes') else 0,
axis=1
)
# BSW Involve Unclosed
dataframe['BSW Involve Unclosed'] = dataframe.apply(
lambda row: 1 if (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes' and
row.get('Status', '') != 'Closed') else 0,
axis=1
)
# 3. HorizontalExpansion 分析列
if 'Created' in dataframe.columns:
dataframe['Created'] = pd.to_datetime(dataframe['Created'], errors='coerce')
days_since_creation = (current_time - dataframe['Created']).dt.days
else:
days_since_creation = pd.Series([0] * len(dataframe))
# HorizontalExpansion Count
dataframe['HorizontalExpansion Count'] = dataframe['HorizontalExpansion PN'].notna().astype(int)
# HorizontalExpansion Unfinished
dataframe['HorizontalExpansion Unfinished'] = (
dataframe['HorizontalExpansion PN'].notna() &
(dataframe['Status'] != 'Done')
).astype(int)
# HorizontalExpansion Delay
dataframe['HorizontalExpansion Delay'] = (
dataframe['HorizontalExpansion PN'].notna() &
(dataframe['Status'] != 'Done') &
(days_since_creation > 30)
).astype(int)
# 4. 分类分析列
# BSW Analysis Conclusions
def bsw_analysis_conclusions(row):
if row['Involvement of BSW'] == 'No':
return 'Non-BSW'
elif row['Involvement of BSW'] == 'Yes':
if pd.notna(row['Custom field (Custom_2)']):
custom_field = row['Custom field (Custom_2)']
if '非BSW问题' in custom_field or 'Non-BSW' in custom_field:
return 'Analyzed-Non-BSW'
elif '开发设计问题' in custom_field or 'Development Design Issue' in custom_field:
return 'Analyzed-BSW'
elif '需求问题' in custom_field or 'Requirement Issue' in custom_field:
return 'Analyzed-Non-BSW'
elif '平台问题' in custom_field or 'Platform Issue' in custom_field:
return 'Analyzed-BSW'
elif '三方包问题' in custom_field or 'Party Package Issue' in custom_field:
return 'Analyzed-三方包问题'
return 'Analyzing-Unclassified'
dataframe['BSW Analysis Conclusions'] = dataframe.apply(bsw_analysis_conclusions, axis=1)
# Stack Classification
def stack_classification(component):
if pd.isna(component):
return 'Unclassed'
stacks = ['Com_Stack', 'Cdd_Stack', 'CybSec_Stack', 'Diag_Stack',
'Fbl_Stack', 'FuSa_Stack', 'IoHwAb_Stack', 'Mem_Stack',
'ModeMgm_Stack', 'OS_Stack', 'Sys_Stack']
for stack in stacks:
if stack in component:
return stack
return 'Unclassed'
dataframe['Stack Classification'] = dataframe['Component/s'].apply(stack_classification)
# BSW Reason Classification
def calculate_bsw_reason_classification(row):
if row['Involvement of BSW'] == 'No':
return '底层未参与分析'
if pd.notna(row['Custom field (Custom_2)']):
custom_field = row['Custom field (Custom_2)']
if '非BSW问题' in custom_field or 'Non-BSW' in custom_field:
return '非BSW问题'
elif '开发设计问题' in custom_field or 'Development Design Issue' in custom_field:
return '开发设计问题'
elif '需求问题' in custom_field or 'Requirement Issue' in custom_field:
return '需求问题'
elif '平台问题' in custom_field or 'Platform Issue' in custom_field:
return '平台问题'
elif '三方包问题' in custom_field or 'Party Package Issue' in custom_field:
return '三方包问题'
return 'Analyzing-Unclassified'
dataframe['BSW Reason Classification'] = dataframe.apply(calculate_bsw_reason_classification, axis=1)
# total列
dataframe['total'] = dataframe.apply(
lambda row: 0 if row['Project key'] == 'KOCHI_PL' else 1
if row['Project key'] != 'KOCHI_PL' and row['Issue Type'] in ["KOCHI AE Issue", "Problem"] else 0,
axis=1
)
# BSW Analyzed
regex = r'需求问题|平台问题|开发设计问题|非BSW问题|三方包问题|Non-BSW|Development Design Issue|Requirement Issue|Platform Issue|Party Package Issue'
dataframe['BSW Analyzed'] = dataframe.apply(
lambda row: 1 if (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes' and
pd.notna(row['Custom field (Custom_2)']) and
row['Custom field (Custom_2)'].str.contains(regex, regex=True))
else 0,
axis=1
)
# BSW Unanalyzed
dataframe['BSW Unanalyzed'] = dataframe.apply(
lambda row: 1 if (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes' and
(pd.isna(row['Custom field (Custom_2)']) or
not row['Custom field (Custom_2)'].str.contains(regex, regex=True)))
else 0,
axis=1
)
# BSW Staff List
dataframe['BSW Staff List'] = dataframe['Assignee'].apply(
lambda x: "Yes" if x in bsw_staff_set else "No"
)
# Found By Classification
def classify_found_by(row):
found_by = row['Custom field (Found By)']
labels = row['Labels'] if pd.notna(row['Labels']) else ""
if found_by == 'SW Integration Test' and 'BSW_IT' in labels:
return 'BSW_IT'
elif found_by == 'SW Integration Test':
return 'SWIT'
elif found_by == 'Cybersecurity Monitoring':
return 'Cybersecurity Monitoring'
elif found_by in ['HIL TEST', 'HILP TEST', 'System Test']:
return 'System Test'
elif found_by in ['OEM Test', 'OEM', 'End user']:
return 'OEM&End user'
elif found_by == 'Development Audit' and 'BSW_PT' in labels:
return 'BSW_PT'
elif found_by in ['Review', 'SW Unit Test', 'Development']:
return '开发自测'
return 'Others'
dataframe['Found By Classification'] = dataframe.apply(classify_found_by, axis=1)
# High Priority Unanalyzed
def calculate_high_priority_unanalyzed(row):
if not (row['Issue Type'] in ["KOCHI AE Issue", "Problem"] and
row['Involvement of BSW'] == 'Yes' and
row['Priority'] == 'High'):
return 0
if pd.isna(row['Created']):
return 0
days_diff = (current_time - row['Created']).days
if days_diff <= 15:
return 0
custom_field = str(row.get('Custom field (Custom_2)', ''))
exclude_keywords = [
'需求问题', '平台问题', '开发设计问题', '非BSW问题', '三方包问题',
'Non-BSW', 'Development Design Issue', 'Requirement Issue',
'Platform Issue', 'Party Package Issue'
]
if any(keyword in custom_field for keyword in exclude_keywords):
return 0
return 1
dataframe['High Priority Unanalyzed'] = dataframe.apply(calculate_high_priority_unanalyzed, axis=1)
# 5. 日期相关列
if 'Updated' in dataframe.columns:
dataframe['Updated'] = pd.to_datetime(dataframe['Updated'], errors='coerce')
days_since_update = (current_time - dataframe['Updated']).dt.days
condition_base = (
(dataframe['Issue Type'].isin(["KOCHI AE Issue", "Problem"])) &
(dataframe['Involvement of BSW'] == 'Yes') &
(dataframe['BSW Staff List'] == 'Yes')
)
dataframe['update_over_15'] = (condition_base & (days_since_update >= 15)).astype(int)
dataframe['update_over_7'] = (condition_base & (days_since_update > 7) & (days_since_update < 15)).astype(int)
logging.info("成功添加所有分析列")
return dataframe
def assign_responsibles(dataframe, config_dict):
"""根据配置字典为 DataFrame 增加 'Responsible' 和 'Email' 列"""
if not config_dict:
logging.warning("配置字典为空,无法分配责任人")
dataframe['Responsible'] = "Unassigned"
dataframe['Email'] = ""
return dataframe
def get_responsible_and_email(project_key):
project_key = str(project_key)
# 首先检查具体项目配置
if project_key in config_dict:
project_config = config_dict[project_key]
return (
project_config.get("Responsible", "Unassigned"),
project_config.get("Email", "")
)
# 其次检查默认配置
default_config = config_dict.get("Default", {})
return (
default_config.get("Responsible", "Unassigned"),
default_config.get("Email", "")
)
dataframe[['Responsible', 'Email']] = dataframe['Project key'].apply(
lambda x: pd.Series(get_responsible_and_email(x))
)
return dataframe
# ------------------ 数据库相关 ------------------
def get_database_engine(db_name="default"):
"""创建数据库连接引擎"""
prefix = "BSW_" if db_name == "bsw_jira" else ""
host = os.getenv(f"{prefix}DB_HOST")
user = os.getenv(f"{prefix}DB_USER")
password = os.getenv(f"{prefix}DB_PASSWORD")
database = os.getenv(f"{prefix}DB_NAME", db_name)
port = int(os.getenv(f"{prefix}DB_PORT", 3306))
if not all([host, user, password, database]):
raise ValueError(f"缺少{db_name}数据库配置")
# 增加连接池参数优化
connection_uri = f"mysql+pymysql://{user}:{password}@{host}:{port}/{database}?charset=utf8mb4"
return create_engine(
connection_uri,
pool_size=5, # 减少连接池大小
max_overflow=10,
pool_recycle=3600, # 1小时后回收连接
pool_pre_ping=True, # 执行前检查连接是否有效
isolation_level="READ COMMITTED" # 设置事务隔离级别
)
def write_to_database(df, engine, table_name, max_retries=5, sub_chunk_size=50):
"""数据库写入函数 - 子分块提交"""
if df.empty:
logging.warning("数据为空,跳过写入")
return 0
total_written = 0
num_sub_chunks = (len(df) - 1) // sub_chunk_size + 1
for sub_idx in range(num_sub_chunks):
sub_start = sub_idx * sub_chunk_size
sub_end = min((sub_idx + 1) * sub_chunk_size, len(df))
sub_df = df.iloc[sub_start:sub_end]
for attempt in range(max_retries):
try:
# 获取目标表列名
inspector = inspect(engine)
target_columns = [col['name'] for col in inspector.get_columns(table_name)]
# 筛选存在的列
existing_columns = [col for col in sub_df.columns if col in target_columns]
filtered_sub_df = sub_df[existing_columns]
# 写入数据库 - 使用更小的chunksize
with engine.begin() as connection:
filtered_sub_df.to_sql(
name=table_name,
con=connection,
if_exists='append',
index=False,
chunksize=50, # 使用较小的chunksize
method='multi'
)
written_count = len(filtered_sub_df)
total_written += written_count
logging.debug(f"子分块 {sub_idx+1}/{num_sub_chunks} 写入成功 [{written_count}行]")
break # 成功则跳出重试循环
except OperationalError as e:
error_msg = str(e).lower()
if ("deadlock" in error_msg or "lock wait timeout" in error_msg) and attempt < max_retries - 1:
wait_time = (2 ** attempt) + random.uniform(0, 1) # 指数退避+随机抖动
logging.warning(f"死锁/锁超时,等待{wait_time:.2f}秒后重试子分块 {sub_idx+1}/{num_sub_chunks} (尝试 {attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
logging.error(f"子分块 {sub_idx+1} 写入失败: {str(e)}")
# 备份失败的子分块
backup_path = os.path.join(OUTPUT_DIR, f"error_subchunk_{sub_idx+1}.csv")
sub_df.to_csv(backup_path, index=False)
logging.warning(f"失败子分块已保存至: {backup_path}")
if attempt == max_retries - 1:
# 最后一次尝试失败,跳过当前子分块继续下一个
logging.error(f"子分块 {sub_idx+1} 重试{max_retries}次后仍失败,跳过该子分块")
continue
except SQLAlchemyError as e:
logging.error(f"数据库错误: {str(e)}")
if attempt < max_retries - 1:
wait_time = 1 + attempt
logging.info(f"等待{wait_time}秒后重试子分块 {sub_idx+1}")
time.sleep(wait_time)
else:
backup_path = os.path.join(OUTPUT_DIR, f"error_subchunk_{sub_idx+1}.csv")
sub_df.to_csv(backup_path, index=False)
logging.warning(f"失败子分块已保存至: {backup_path}")
logging.error(f"子分块 {sub_idx+1} 重试{max_retries}次后仍失败,跳过该子分块")
return total_written
def process_and_write_data(source_engine, target_engine, config_path):
"""查询、处理并写入数据 - 增强死锁处理"""
try:
source_table = os.getenv("SOURCE_TABLE_NAME", "jira_task_bsw")
target_table = os.getenv("TARGET_TABLE_NAME", "jira_task_bsw_deal")
logging.info(f"从 {source_table} 读取数据,写入 {target_table}")
# 加载配置文件
config_dict = load_config(config_path)
logging.info(f"配置加载状态: {'成功' if config_dict else '失败'}")
# 准备BSW人员集合
bsw_staff_set = set(config_dict.get("bsw_staff_list", [])) if config_dict else set()
# 项目筛选
project_keys = ["P09135", "P09192", "P08499", "KOCHI_PL"]
query = f"SELECT * FROM `{source_table}` WHERE `Project key` IN {tuple(project_keys)}"
# 分块处理
chunk_size = 300 # 减小分块大小
chunks = pd.read_sql(query, con=source_engine, chunksize=chunk_size)
total_rows = 0
chunk_count = 0
for chunk in chunks:
chunk_count += 1
logging.info(f"开始处理分块 {chunk_count}")
# 处理数据块
processed_chunk = add_columns(chunk, bsw_staff_set)
processed_chunk = assign_responsibles(processed_chunk, config_dict)
# 写入数据库(使用子分块)
try:
written_count = write_to_database(
processed_chunk,
target_engine,
target_table,
sub_chunk_size=50 # 每个子分块50行
)
total_rows += written_count
logging.info(f"分块 {chunk_count} 处理完成,写入 {written_count} 行")
except Exception as e:
logging.error(f"分块 {chunk_count} 写入过程中发生未处理异常: {str(e)}")
# 保存整个分块到CSV以便后续分析
backup_path = os.path.join(OUTPUT_DIR, f"failed_chunk_{chunk_count}.csv")
processed_chunk.to_csv(backup_path, index=False)
logging.warning(f"失败的分块已保存到: {backup_path}")
logging.info(f"总计写入 {total_rows} 行到 {target_table}")
return total_rows
except Exception as e:
logging.error(f"数据处理失败: {str(e)}")
logging.error(traceback.format_exc())
return 0
# ------------------ 主函数 ------------------
if __name__ == "__main__":
# 环境变量检查
required_vars = ["SOURCE_TABLE_NAME", "TARGET_TABLE_NAME"]
missing_vars = [var for var in required_vars if not os.getenv(var)]
if missing_vars:
logging.error(f"缺少环境变量: {', '.join(missing_vars)}")
exit(1)
# 创建数据库连接
try:
source_engine = get_database_engine("default")
target_engine = get_database_engine("bsw_jira")
logging.info("数据库连接成功建立")
except Exception as e:
logging.error(f"数据库连接失败: {str(e)}")
exit(1)
# 处理并写入数据
try:
start_time = time.time()
row_count = process_and_write_data(
source_engine=source_engine,
target_engine=target_engine,
config_path="responsible_config.json"
)
elapsed = time.time() - start_time
logging.info(f"数据处理完成,共写入 {row_count} 条记录,耗时 {elapsed:.2f} 秒")
exit(0)
except Exception as e:
logging.error(f"主流程执行失败: {str(e)}")
exit(1)
```
### 主要优化点:
1. **子分块提交**:
- 将每个数据分块再拆分为50行一个的子分块
- 每个子分块独立提交事务,大幅减少事务持有锁的时间
2. **指数退避+随机抖动**:
```python
wait_time = (2 ** attempt) + random.uniform(0, 1)
```
3. **更精细的错误处理**:
- 子分块级别备份:每次失败保存对应子分块到CSV
- 跳过失败子分块继续处理后续数据
4. **连接池优化**:
- 设置`pool_pre_ping=True`确保连接有效
- 设置合理的连接池大小
5. **日志增强**:
- 记录每个子分块的写入状态
- 记录每个分块的处理进度
### 其他建议:
1. **临时调整数据库配置**:
```sql
-- 增加锁等待超时时间(临时)
SET GLOBAL innodb_lock_wait_timeout=120;
```
2. **检查目标表索引**:
- 移除不必要的索引(尤其是写操作频繁时)
- 写操作完成后重建索引
3. **调整MySQL配置**(my.ini):
```ini
[mysqld]
innodb_buffer_pool_size=2G
innodb_log_file_size=512M
innodb_flush_log_at_trx_commit=2
```
§§相关问题§§
1. 如何进一步优化MySQL数据库以减少死锁的发生?
2. 在子分块提交的策略中,如何选择最佳的子分块大小?
3. 除了死锁重试,还有哪些方法可以保证数据写入的可靠性?
4. 在Pandas中处理大数据集时,如何避免内存溢出问题?
5. 如何设计一个实时监控数据库死锁的系统?
</think>
我理解您遇到了数据库死锁问题,尽管我之前的优化尝试仍未完全解决。让我提供一个更全面的解决方案,通过多维度优化来彻底解决死锁问题:
```python
import os
import json
import logging
import traceback
import time
import pandas as pd
import random
from datetime import datetime
from sqlalchemy import create_engine, inspect
from sqlalchemy.exc import OperationalError, SQLAlchemyError
from dotenv import load_dotenv
import threading
# 初始化日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler("bsw_task_jira_deal.log"),
logging.StreamHandler()
]
)
# 加载环境变量
load_dotenv()
# 输出文件配置
OUTPUT_DIR = r"D:\AEB Management\output"
OUTPUT_FILE = "processed_data.csv"
os.makedirs(OUTPUT_DIR, exist_ok=True)
# ------------------ 配置加载 ------------------
def load_config(config_path):
"""加载 JSON 配置文件为字典"""
try:
with open(config_path, "r", encoding="utf-8") as file:
config = json.load(file)
logging.info(f"成功加载配置文件: {config_path}")
return config
except Exception as e:
logging.error(f"加载配置文件失败: {str(e)}")
logging.error(traceback.format_exc())
return {
"default_responsible": "管理员",
"default_email": os.getenv("DEFAULT_EMAIL", "admin@example.com")
}
# ------------------ 数据列处理 ------------------
def add_columns(dataframe, bsw_staff_set):
"""根据业务规则动态添加新列"""
current_time = pd.Timestamp.now()
# 添加基础列
dataframe['HorizontalExpansion PN'] = None
# 1. KOCHI_PL 项目处理逻辑 (保持原逻辑不变)
# ... [原有KOCHI_PL处理代码] ...
# 2. 核心业务分析列 (保持原逻辑不变)
# ... [原有业务分析列代码] ...
logging.info("成功添加所有分析列")
return dataframe
def assign_responsibles(dataframe, config_dict):
"""根据配置字典为 DataFrame 增加 'Responsible' 和 'Email' 列"""
# ... [原有责任人分配代码] ...
return dataframe
# ------------------ 数据库相关 ------------------
def get_database_engine(db_name="default"):
"""创建数据库连接引擎 - 增强连接池管理"""
prefix = "BSW_" if db_name == "bsw_jira" else ""
host = os.getenv(f"{prefix}DB_HOST")
user = os.getenv(f"{prefix}DB_USER")
password = os.getenv(f"{prefix}DB_PASSWORD")
database = os.getenv(f"{prefix}DB_NAME", db_name)
port = int(os.getenv(f"{prefix}DB_PORT", 3306))
if not all([host, user, password, database]):
raise ValueError(f"缺少{db_name}数据库配置")
# 增强连接池参数优化
connection_uri = f"mysql+pymysql://{user}:{password}@{host}:{port}/{database}?charset=utf8mb4"
return create_engine(
connection_uri,
pool_size=3, # 减少连接池大小
max_overflow=5,
pool_recycle=1800, # 30分钟后回收连接
pool_pre_ping=True, # 执行前检查连接是否有效
isolation_level="READ COMMITTED", # 设置事务隔离级别
connect_args={
'connect_timeout': 30, # 连接超时时间
'read_timeout': 60, # 读取超时时间
'write_timeout': 60 # 写入超时时间
}
)
def write_to_database(df, engine, table_name, max_retries=5):
"""数据库写入函数 - 增强死锁处理策略"""
if df.empty:
logging.warning("空数据框,跳过写入")
return 0
for attempt in range(max_retries):
try:
# 获取目标表列名
inspector = inspect(engine)
target_columns = [col['name'] for col in inspector.get_columns(table_name)]
# 筛选存在的列
existing_columns = [col for col in df.columns if col in target_columns]
filtered_df = df[existing_columns]
# 写入数据库 - 使用显式事务和更小的chunksize
with engine.begin() as connection:
filtered_df.to_sql(
name=table_name,
con=connection,
if_exists='append',
index=False,
chunksize=50, # 减小批量大小
method='multi'
)
return filtered_df.shape[0]
except OperationalError as e:
error_msg = str(e).lower()
if "deadlock" in error_msg and attempt < max_retries - 1:
# 指数退避 + 随机抖动
wait_time = (2 ** attempt) + random.uniform(0, 1)
logging.warning(f"死锁检测,等待{wait_time:.2f}秒后重试 (尝试 {attempt + 1}/{max_retries})")
time.sleep(wait_time)
elif "lock wait timeout" in error_msg and attempt < max_retries - 1:
wait_time = 3 + attempt * 2
logging.warning(f"锁等待超时,等待{wait_time}秒后重试 (尝试 {attempt + 1}/{max_retries})")
time.sleep(wait





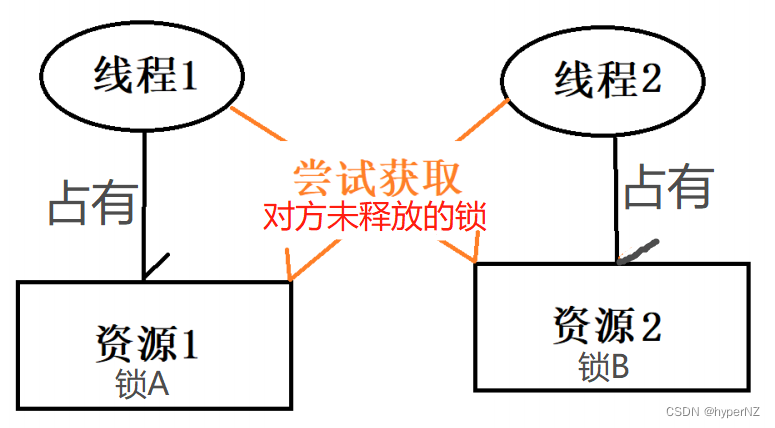
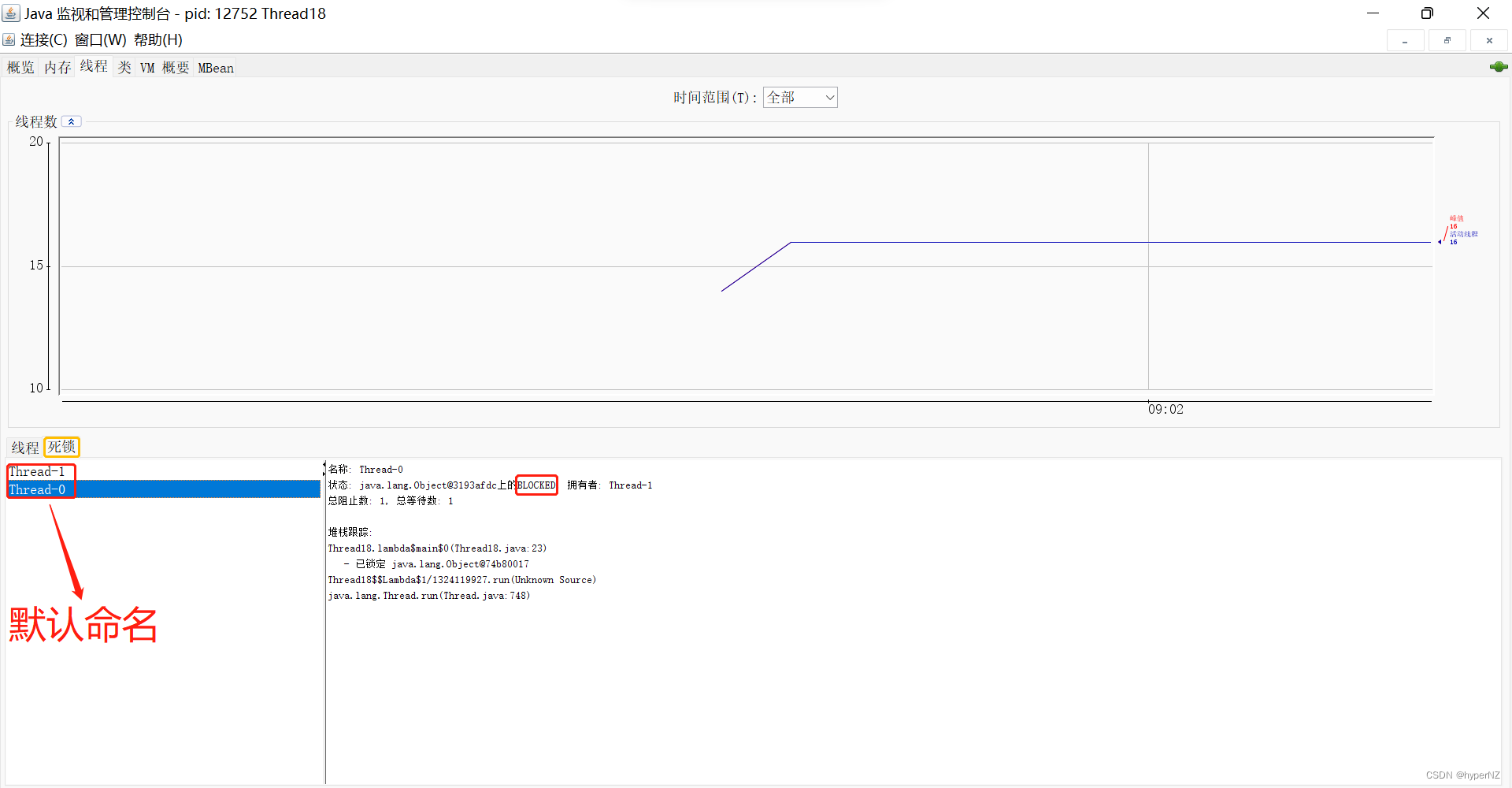
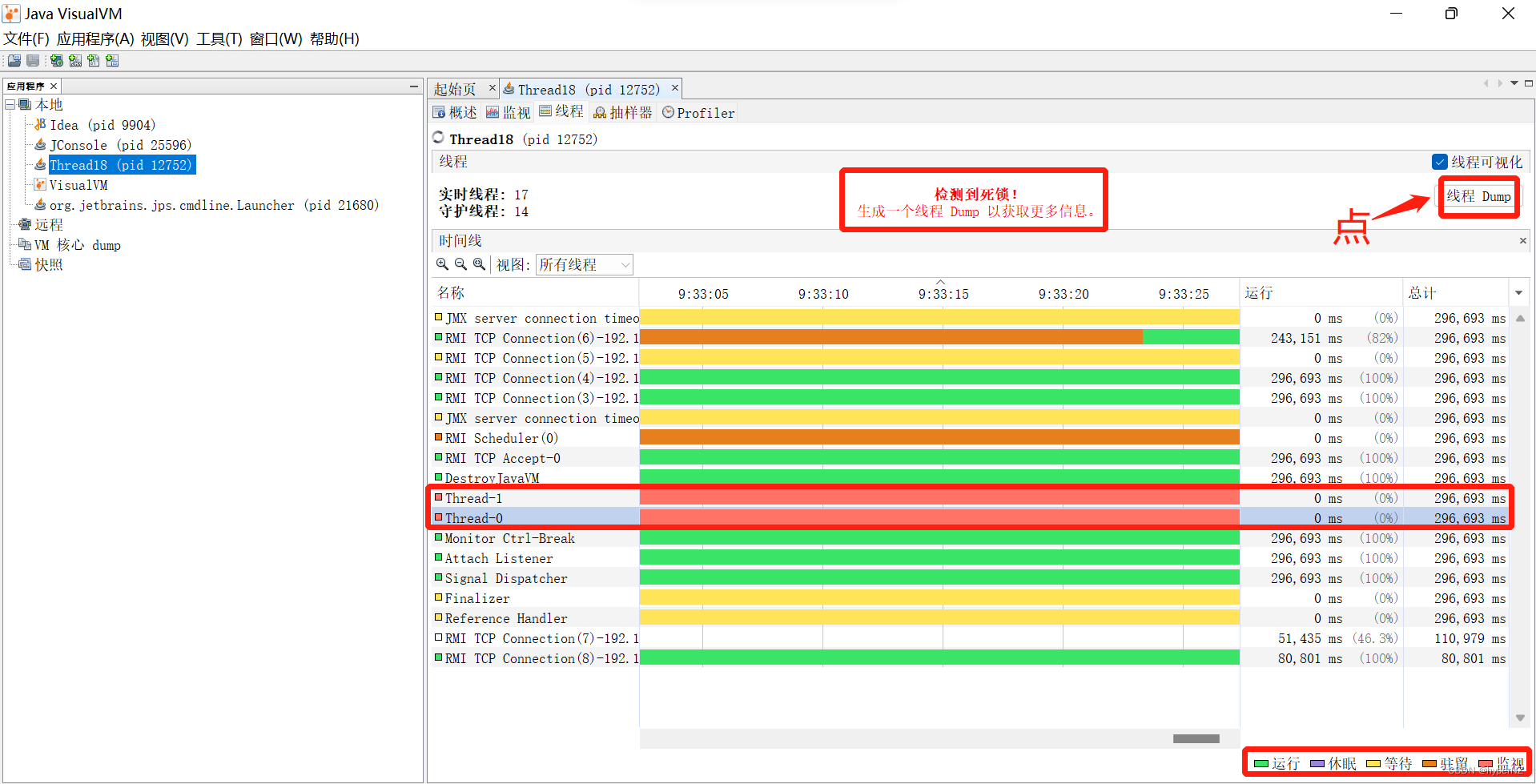
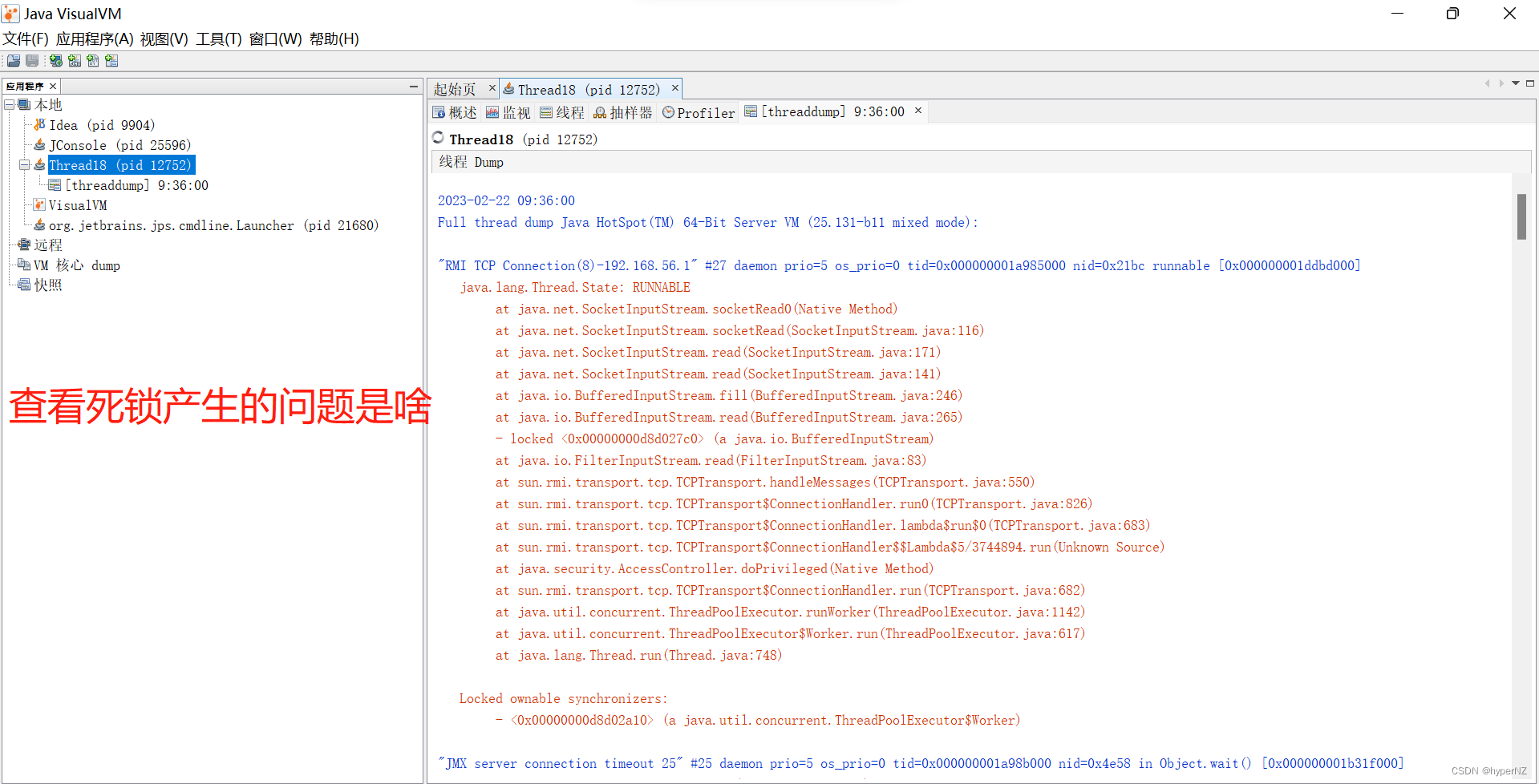
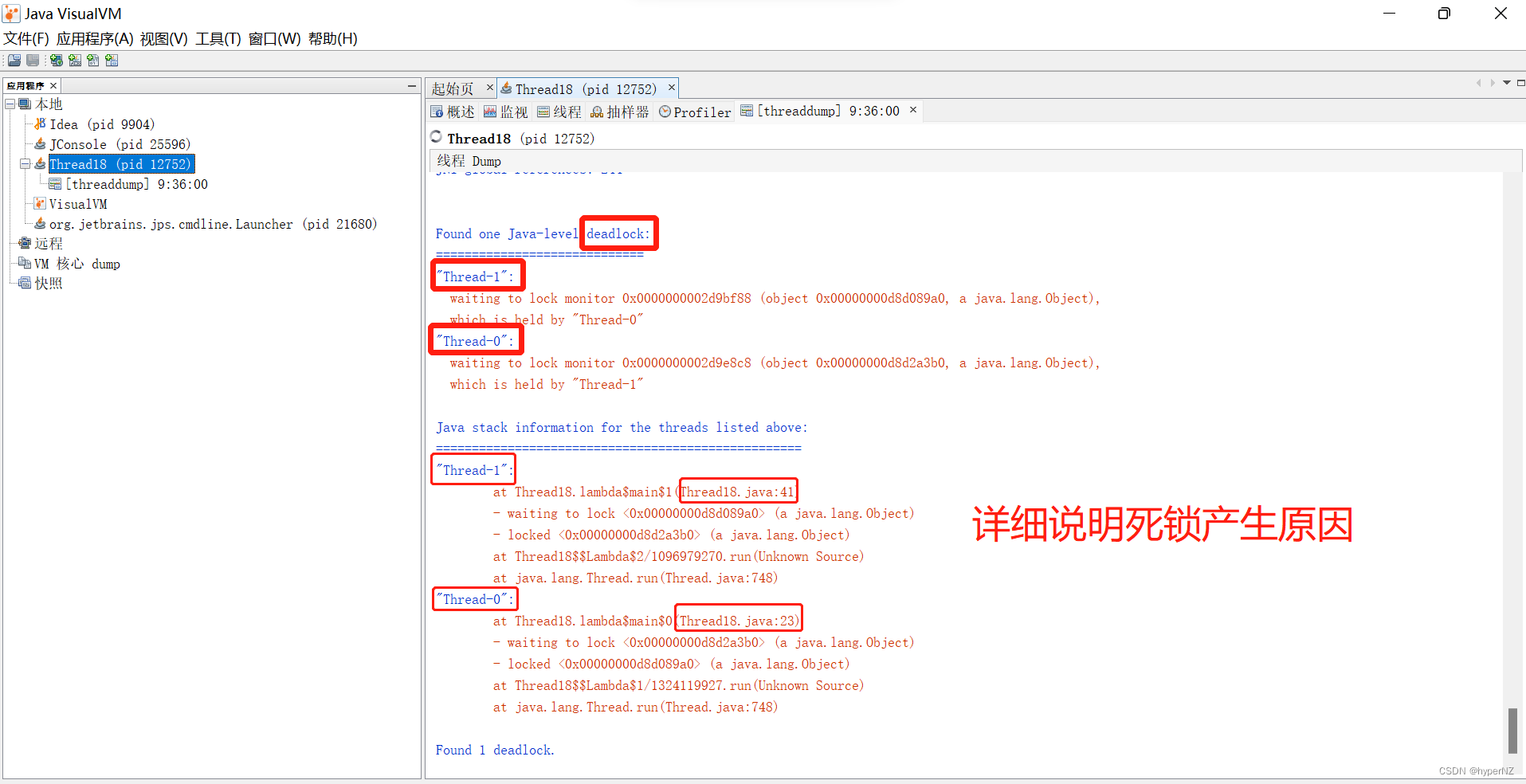
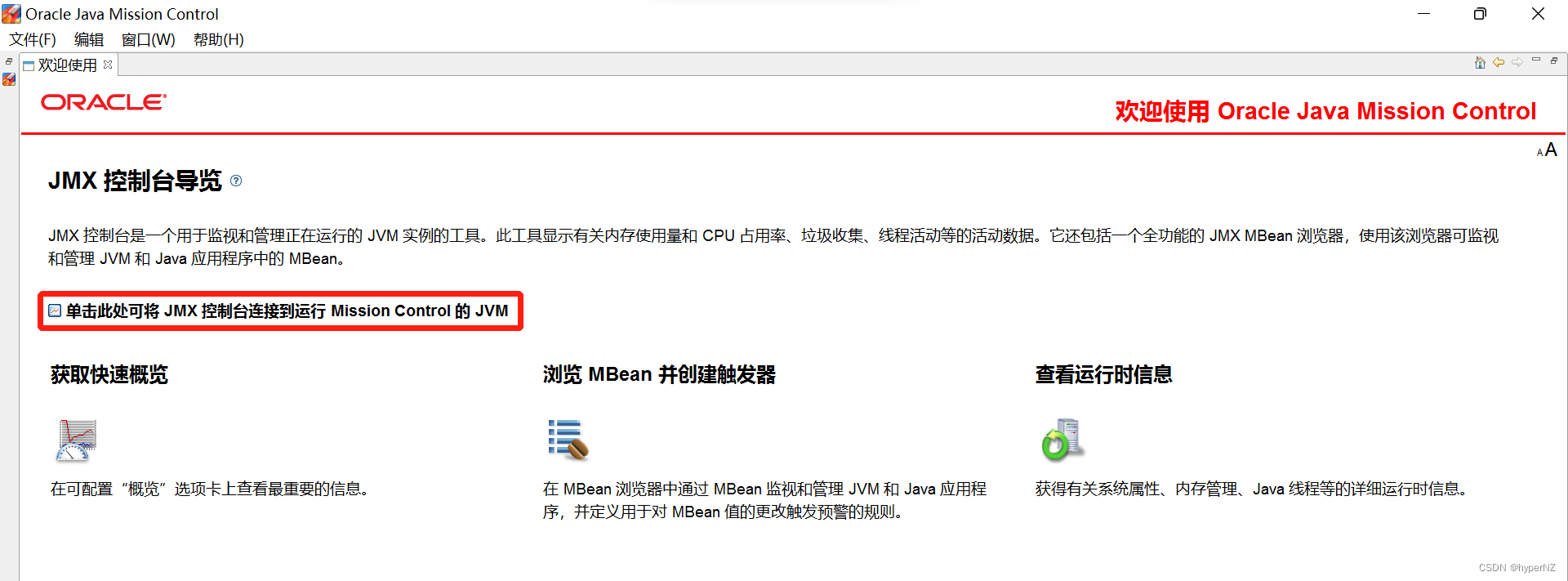
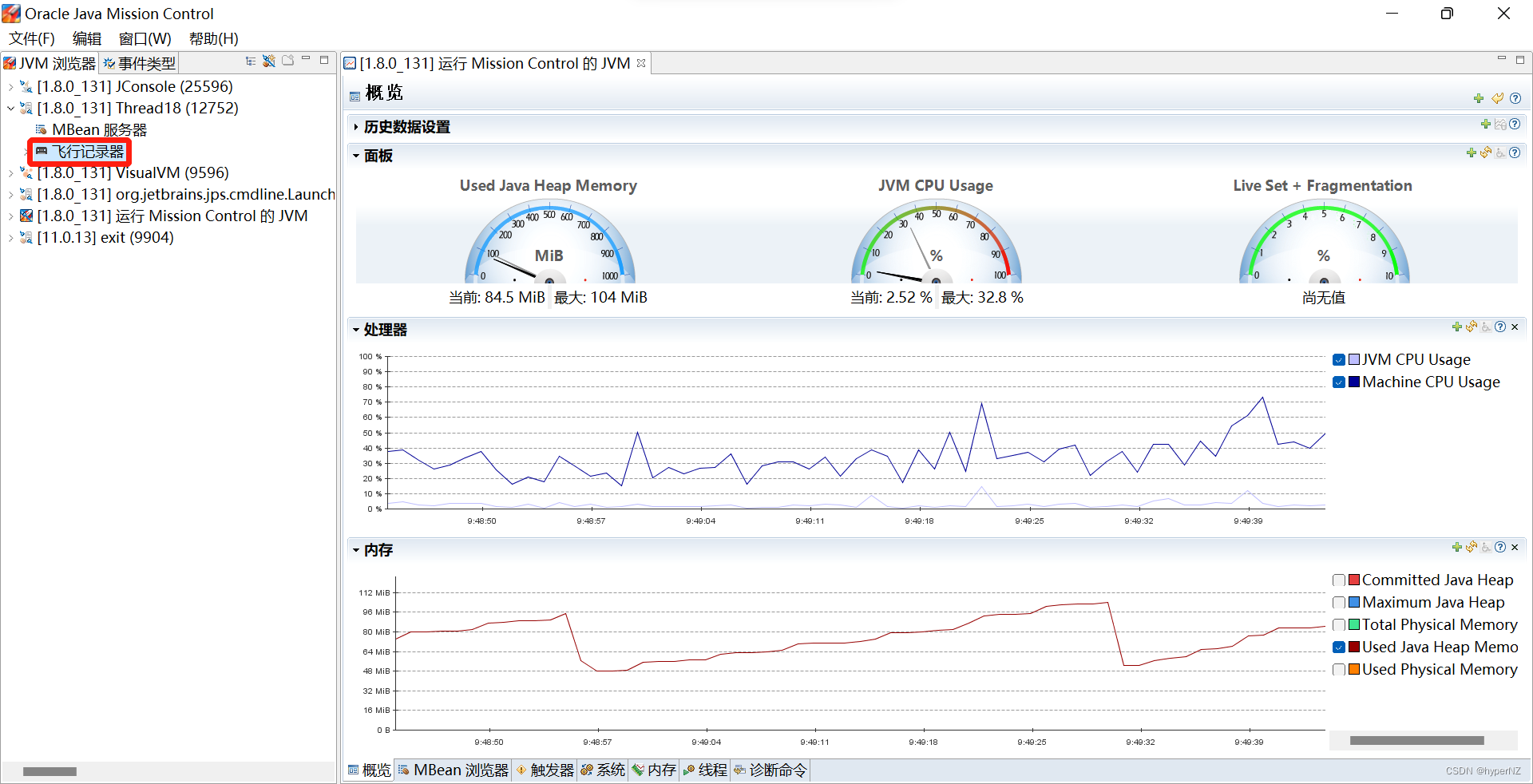
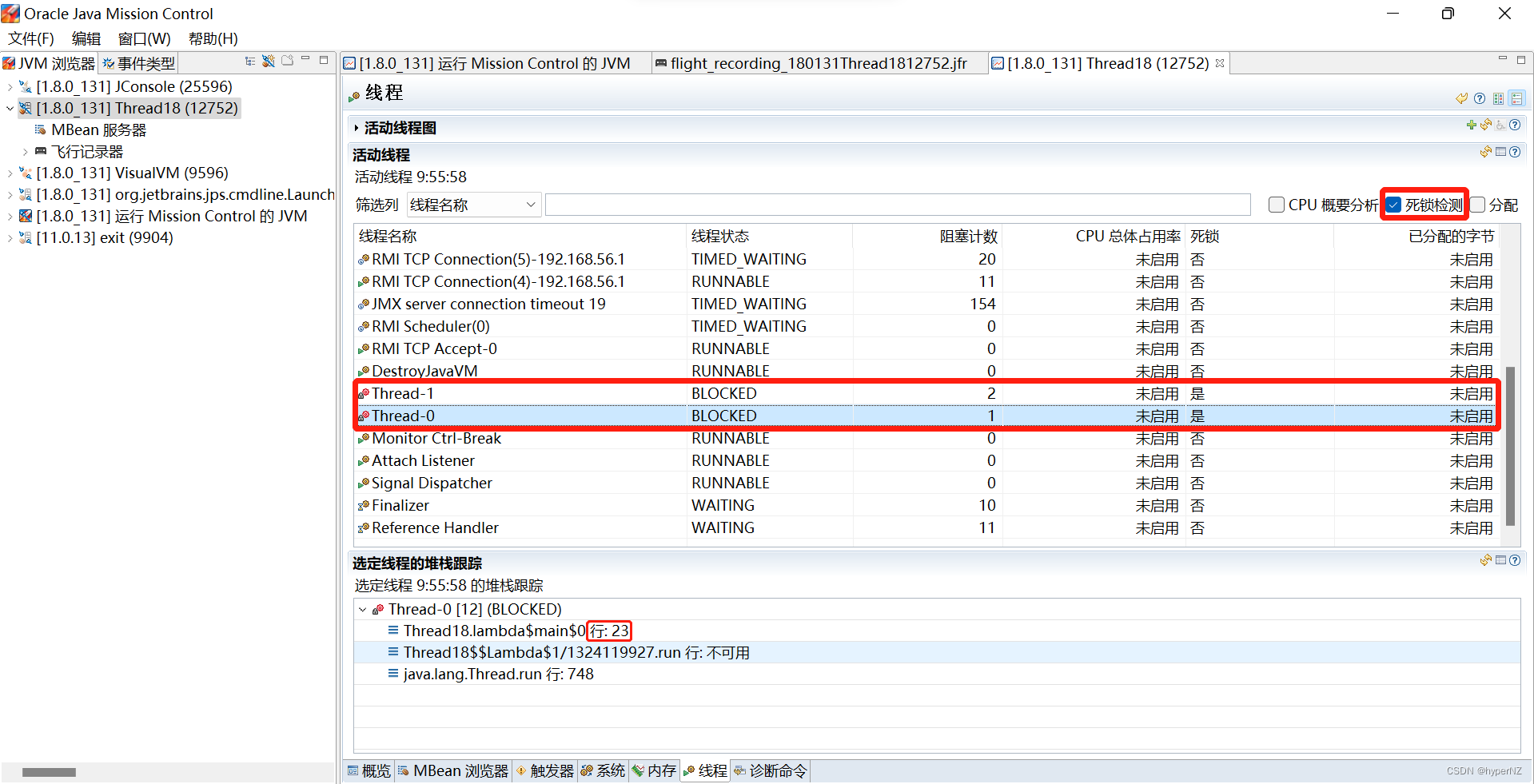
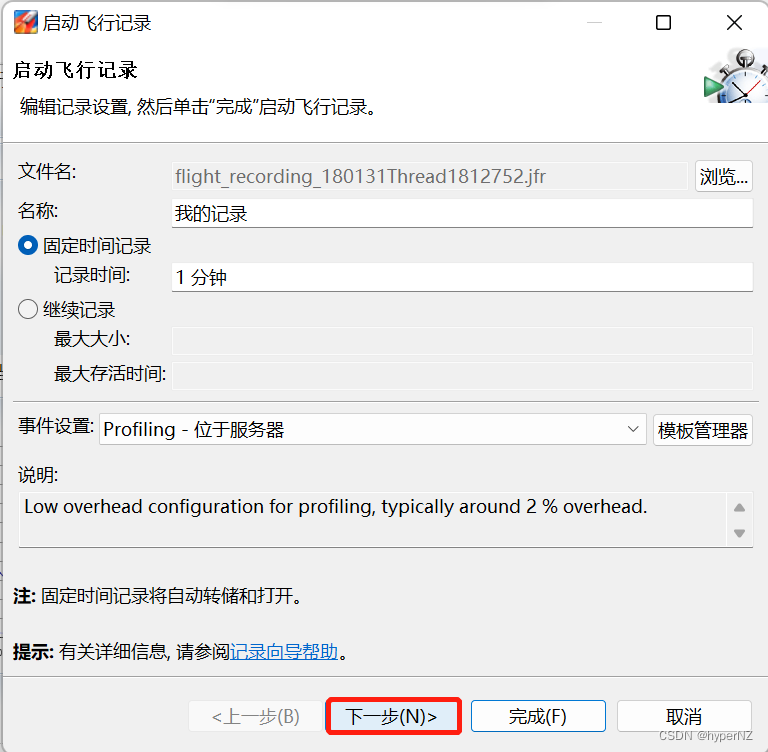
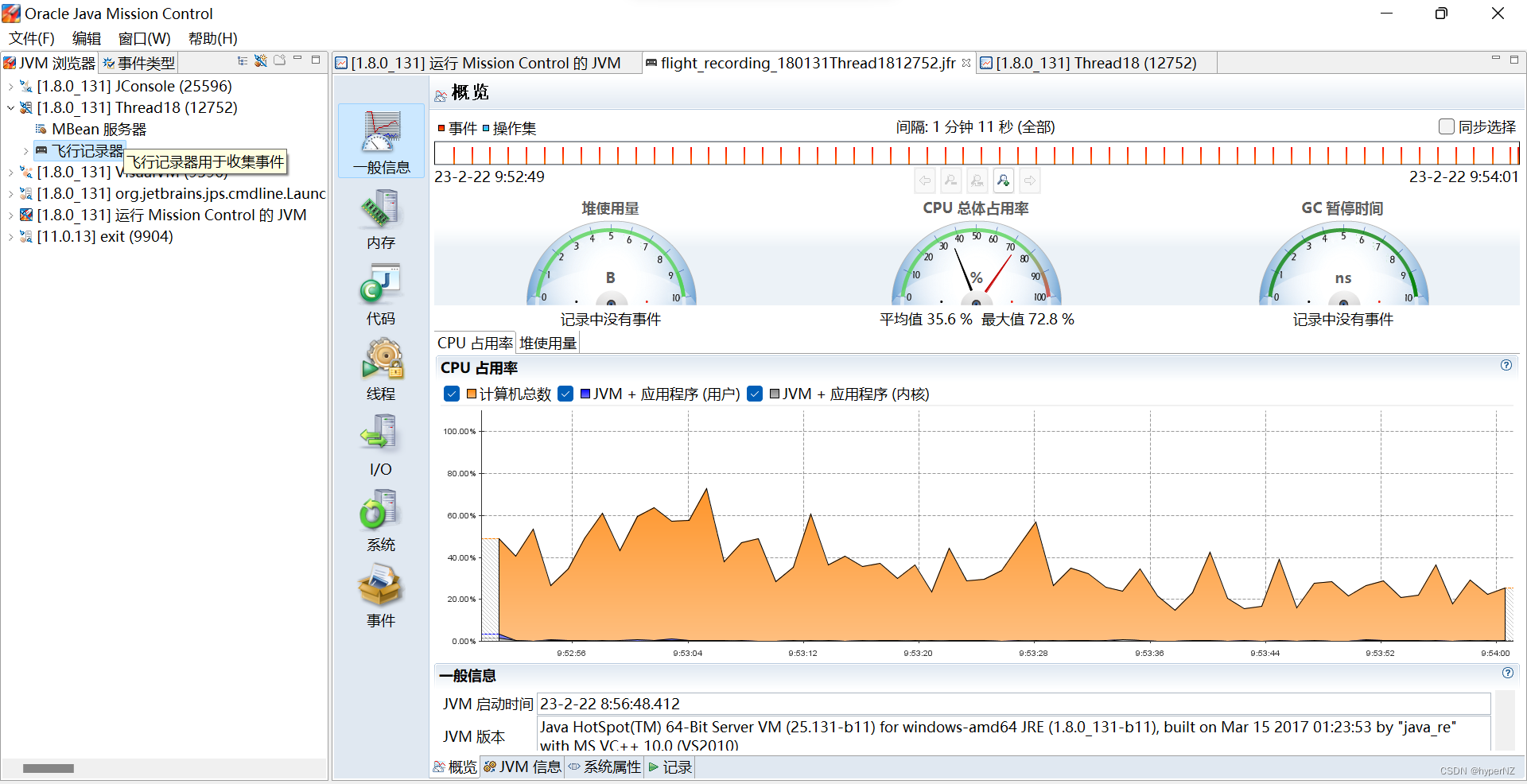
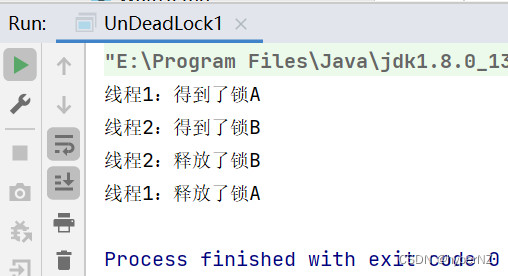
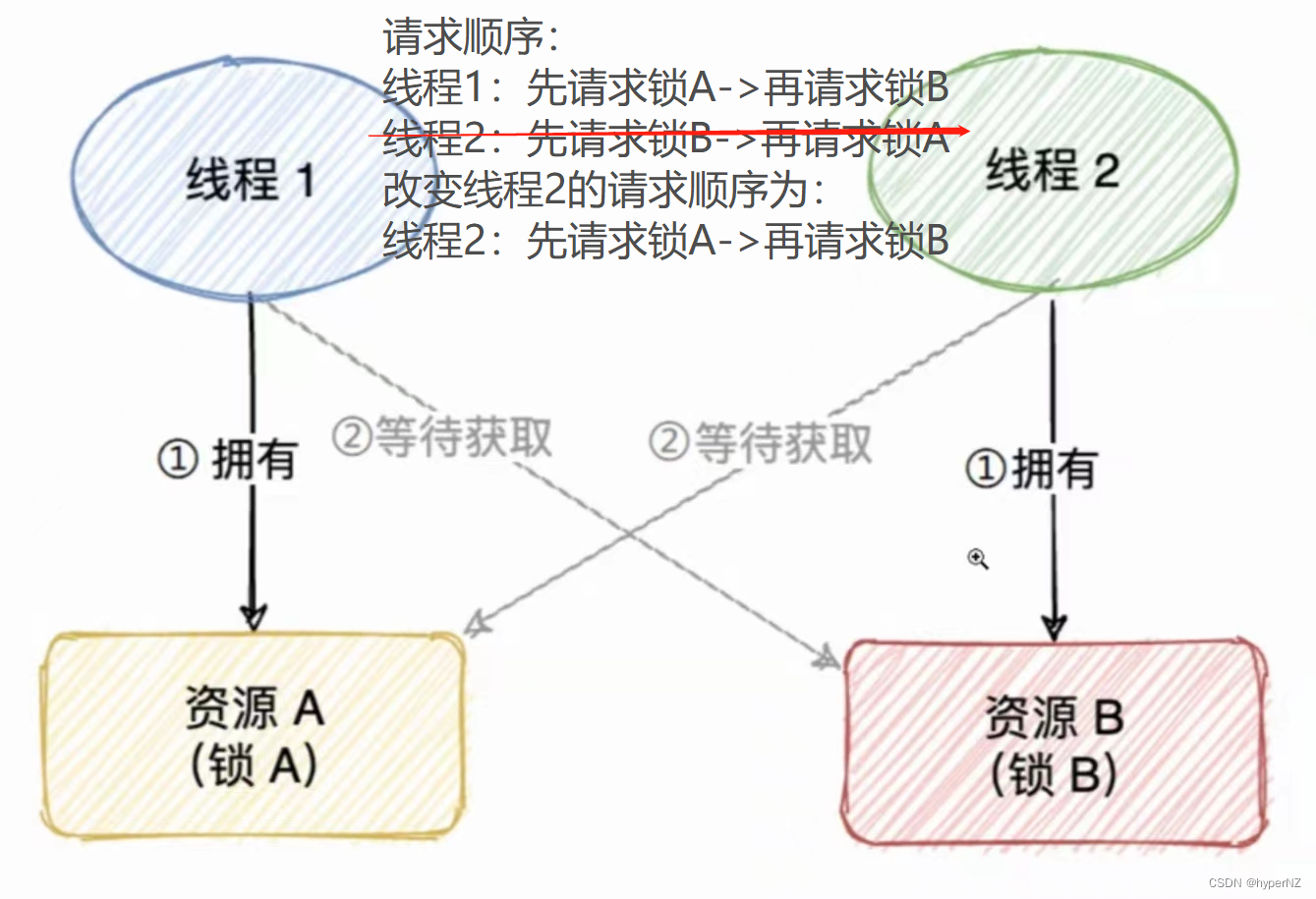
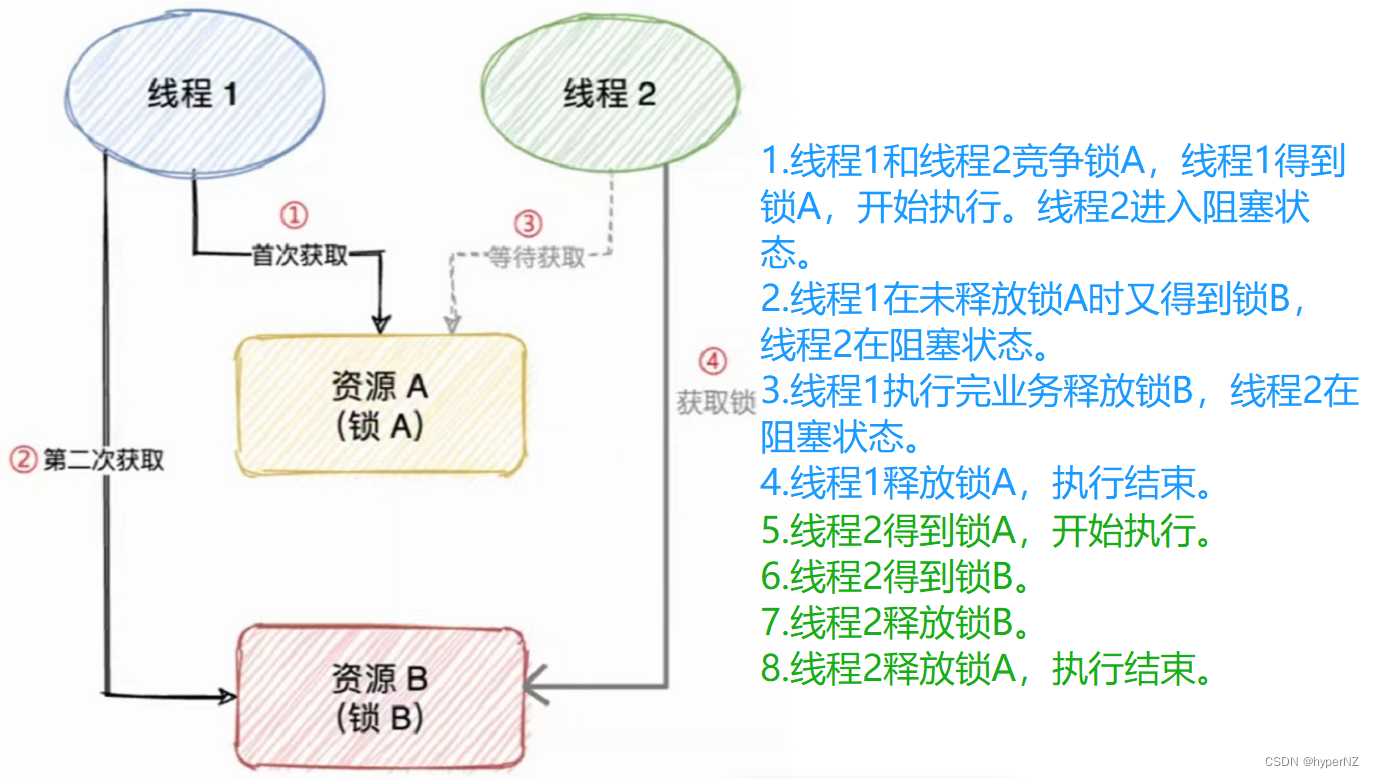
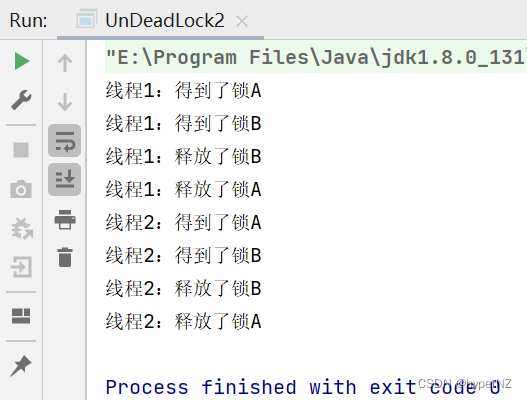
 文章详细解释了死锁的定义,通过代码示例展示了死锁如何发生,并介绍了使用jconsole、jvisualvm和jmc等工具检测死锁的方法。死锁产生的四个条件包括互斥条件、不可被剥夺条件、请求并持有条件和环路等待条件。文章提供了两种解决死锁的策略,分别是破坏请求并持有条件和消除环路等待条件。
文章详细解释了死锁的定义,通过代码示例展示了死锁如何发生,并介绍了使用jconsole、jvisualvm和jmc等工具检测死锁的方法。死锁产生的四个条件包括互斥条件、不可被剥夺条件、请求并持有条件和环路等待条件。文章提供了两种解决死锁的策略,分别是破坏请求并持有条件和消除环路等待条件。





















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









