



 本文介绍了一种解决SQL中A、B、C三表联查时A表数据重复的问题,通过子查询及多层SELECT DISTINCT实现正确求和,避免了数据重复带来的错误结果,适用于一对多及一对一表关系。
本文介绍了一种解决SQL中A、B、C三表联查时A表数据重复的问题,通过子查询及多层SELECT DISTINCT实现正确求和,避免了数据重复带来的错误结果,适用于一对多及一对一表关系。
有A、B、C三表 表与表关系为 A–>B 为一对多 A–>C为 一对一 三表联查求和 会出现 A表数据重复问题 解决办法 子查询 !! 三层 SELECT DISTINCT 亲测 有效
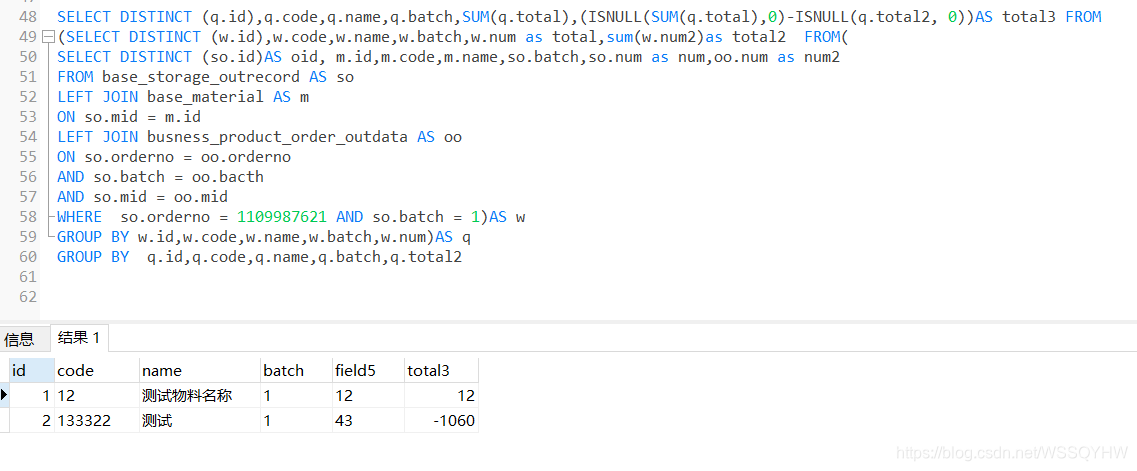
SELECT DISTINCT (q.id),q.code,q.name,q.batch,SUM(q.total),(ISNULL(SUM(q.total),0)-ISNULL(q.total2, 0))AS total3 FROM
(SELECT DISTINCT (w.id),w.code,w.name,w.batch,w.num as total,sum(w.num2)as total2 FROM(
SELECT DISTINCT (so.id)AS oid, m.id,m.code,m.name,so.batch,so.num as num,oo.num as num2
FROM base_storage_outrecord AS so
LEFT JOIN base_material AS m
ON so.mid = m.id
LEFT JOIN busness_product_order_outdata AS oo
ON so.orderno = oo.orderno
AND so.batch = oo.bacth
AND so.mid = oo.mid
WHERE so.orderno = 1109987621 AND so.batch = 1)AS w
GROUP BY w.id,w.code,w.name,w.batch,w.num)AS q
GROUP BY q.id,q.code,q.name,q.batch,q.total

















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









