









 这篇博客介绍了Elasticsearch的基础知识,包括其与Lucene的关系、与Solr的区别,以及如何使用ES进行CRUD操作。讨论了ES的集群状态,分词和文档映射,并提供了最佳实践步骤。此外,还讲解了通过Java代码操作ES的方法。
这篇博客介绍了Elasticsearch的基础知识,包括其与Lucene的关系、与Solr的区别,以及如何使用ES进行CRUD操作。讨论了ES的集群状态,分词和文档映射,并提供了最佳实践步骤。此外,还讲解了通过Java代码操作ES的方法。
1es的认识(理解)
1.1 什么是es
es 全称elasticsearch
es : 做全文检索的 ,底层基于lucene的开发
lucene 相等于jdbc
es 相当于 mybatis/jpa
1.2 es和lucene的比较
为什么需要使用es.为什么不用lucene?
(1)api操作很麻烦 不方便
搜索 : 创建索引 搜索索引 一堆api
es: get /product/1 – {}
(2)lucene不支持集群
es集群 处理很大的数据量
KB – > MB -->GB – >TB – >PB
1024KB – 1MB
1024MB – 1GB
1024GB – 1TB
1024TB – 1PB
1.3 ES和solr的区别
es 和 solr 都可以做全文检索,solr的重量级的框架,它除了全文检索以外,还可以做其他的事情(比如
命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)),solr可以nosql结合起来使用
solr 在传统的搜索效率要比es好,但是实时搜索领域比es低
2 使用ES(掌握)
(1)安装ES服务端
解压–>bin/elasticsearch.bat–>浏览器访问 http://localhost:9200/
9200web里面展示的效果 9300java程序可以访问的端口
(2)es的客户端的交互方式
a) 基于restful风格API的去操作
get post put delete patch
(1)curl的命令方式 --不用
(2)kibana也可以操作
(3)head工具
安装的时候,如果出现错误:
(4)postman(测试后台的java代码)
b) 通过java代码去操作
java通过9300操作es服务器
(3)restful风格 +JSON方式 操作数据
http特点 就是无状态的
get /shopping/1
put /shopping/2 {“name”:“xx产品”}
post /shopping/2 {“name”:“xx产品”}
delete /shopping/1
3 使用客户端
(1)kibanna客户端
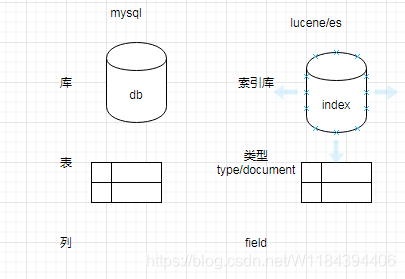
index : 索引库
type: 看成一个表
json:看成一行数据
4 ES(服务) 集群的状态
red: 红色 不健康的状态 服务的有问题
green:绿色 所有的正常 主从都分配好,集群可以使用
yellow:黄色 主从分配 至少有一个从缺失
2主 1从
5 文档的crud
5.1 基本的crud(掌握)
# 完成crud
# 新增
PUT crm/employee/1
{
"name":"xiaorong",
"age":18
}
# 修改 --整个文档
POST crm/employee/1
{
"name":"xiaohuahua"
}
# 修改局部文档
POST crm/employee/1/_update
{
"doc":{"name":"xiaohuahua"}
}
# 查询
GET crm/employee/1
# 删除
DELETE crm/employee/1
5.2 特殊的用法(掌握)
# 展示没有什么效果(了解)
GET crm/employee/AW-tOSHILqo6XVH8f6cg?pretty
# 展示部分的字段
GET crm/employee/AW-tOSHILqo6XVH8f6cg?_source=age,name
# 返回元数据
GET crm/employee/AW-tOSHILqo6XVH8f6cg/_source
# 修改数据 (脚本修改 --了解)
POST crm/employee/AW-tOSHILqo6XVH8f6cg/_update
{
"script" : "ctx._source.age += 5"
}
# 批量新增 --了解
POST _bulk
{ "delete": { "_index": "itsource", "_type": "employee", "_id": "123" }}
{ "create": { "_index": "itsource", "_type": "blog", "_id": "123" }}
{ "title": "我发布的博客111" }
{ "index": { "_index": "itsource", "_type": "blog" }}
{ "title": "我的第二博客2222" }
GET itsource/blog/_search
5.3 文档的查询
1 通过id查询
GET crm/employee/AW-tOSHILqo6XVH8f6cg/_source
2 批量查询
# 不同库 不同表数据 (了解)
GET _mget
{
"docs" : [
{
"_index" : "itsource",
"_type" : "blog",
"_id" : "123"
},
{
"_index" : "crm",
"_type" : "employee",
"_id" : "AW-tOSHILqo6XVH8f6cg",
"_source": ["name","age"]
}
]
}
# 同一个库 同一个表数据
GET itsource/blog/_mget
{
"ids":["123","AW-tQP_4Lqo6XVH8f6ci"]
}
3 其他的查询(掌握)
# 分页查询
GET crm/employee/_search?size=3&from=6
# 带条件查询
GET crm/employee/_search?q=age:38
GET crm/employee/_search?q=age[18 TO 48]
et
{
“ids”:[“123”,“AW-tQP_4Lqo6XVH8f6ci”]
}
3 其他的查询(掌握)
```json
# 分页查询
GET crm/employee/_search?size=3&from=6
# 带条件查询
GET crm/employee/_search?q=age:38
GET crm/employee/_search?q=age[18 TO 48]
如果查询条件很多很多,上面的写法就不方便,es还提供了另外一种写法 DSL的查询和过滤
5.4 DSL的查询和过滤
什么是DSL:
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现
GET itsource/employee/_search?q=fullName:老郑
比如DSL查询:
GET itsource/employee/_search
{
"query" : {
"match" : {
"fullName" : "老郑"
}
}
}
DSL两部分组成 DSL查询 和 DSL过滤
5.5 DSL查询(掌握)
使用DSL查询,必须要传递query参数给ES。
# 完成的DSL查询语句 -- java
GET crm/employee/_search
{
"query":{
"match_all/match": {
"field":"value"
}
},
"from":0,
"size":3,
"_source": ["name","age"],
"sort":[{"age": "asc"}]
}
5.6 DSL过滤(掌握)
DSL过滤语句和DSL查询语句非常相似,但是它们的使用目的却不同 :
DSL过滤 查询文档的方式更像是对于我的条件“有”或者“没有”,–精确查询
而DSL查询语句则像是“有多像”。–类似于模糊查询
DSL过滤和DSL查询在性能上的区别 :
ü 过滤结果可以缓存并应用到后续请求。
ü 查询语句同时 匹配文档,计算相关性,所以更耗时,且不缓存。
ü 过滤语句 可有效地配合查询语句完成文档过滤。
GET crm/employee/_search
{
"query":{
"bool": {
"must": [
{"wildcard": {
"name": "x*1"
}}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 90
}
}
}
}
},
"from":0,
"size":3,
"_source": ["name","age"],
"sort":[{"age": "asc"}]
}
6 分词(掌握)和文档映射
分词: lucene的时候,在创建索引的时候,或者搜索索引的时候,都可以添加分词器
分词器: 按照一定规则把内容拆分开
(1)引入ik的分词器
解压分词器–>es (plugins目录)–>(ik)
在存入值 获取搜索的时候,就可以使用分词器
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
(2)文档映射处理
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。
相当于给文档里面的字段 设置一些类型 类似mysql给name设置varchar
a) 默认类型
存储值的时候,es系统给它默认的类型 – 不用关心
b )自定义类型的映射处理
如果需要指定一些分词器,需要自定义类型映射
delete shop1;
PUT shop1
{
"mappings":{
"goods1": {
"properties": {
"name1": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
}
动态模板:
PUT _template/global_template //创建名为global_template的模板
{
"template": "*", //匹配所有索引库
"settings": { "number_of_shards": 1 }, //匹配到的索引库只创建1个主分片
"mappings": {
"_default_": {
"_all": {
"enabled": false //关闭所有类型的_all字段
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",//匹配类型string
"match": "*_text", //匹配字段名字以_text结尾 name_text
"mapping": {
"type": "text",//将类型为string的字段映射为text类型
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",//匹配类型string
"mapping": {
"type": "keyword"//将类型为string的字段映射为keyword类型
}
}
}
]
}
}}
7 最佳实践步骤(了解)
(1) 如果库里面有数据 – 一般不做映射
(2) 步骤
有库 没有数据 -->删除库 创建库 动态模板 自定义映射 crud测试
没有库 -->创建库 动态模块 自定义映射 crud测试
(3) 开发人员 -->crud
动态模板–制定规则的去写
8 es的集群(了解)
Es集群 宏观图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XqssrsvJ-1579249242544)(es笔记.assets/image-20200117110859140.png)]
8.1 node的类型介绍
一般地,ElasticSearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。这些功能是由两个属性控制的(node.master和node.data)。默认情况下这两个属性的值都是true。
在生产环境下,如果不修改ElasticSearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题,下面详细介绍一下这两个属性的含义以及不同组合可以达到的效果。
一、node.master
这个属性表示节点是否具有成为主节点的资格。
注意:此属性的值为true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。所以,这个属性只是代表这个节点是不是具有主节点选举资格。
二、node.data
这个属性表示节点是否存储数据。
三、四种组合配置方式
(1)node.master: true node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。ElasticSearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,因为这样相当于主节点和数据节点的角色混合到一块了。
(2)node.master: false node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据,后期提供存储和查询服务。
(3)node.master: true node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点,这个节点我们称为master节点。
(4)node.master: false node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
四、其他小知识点
1、默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求。
2、在一个生产集群中我们可以对这些节点的职责进行划分。建议集群中设置3台以上的节点作为master节点【node.master: true node.data: false】,这些节点只负责成为主节点,维护整个集群的状态。
3、再根据数据量设置一批data节点【node.master: false node.data: true】,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大。
4、在集群中建议再设置一批client节点【node.master: false node.data: true】,这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
5、master节点:普通服务器即可(CPU 内存 消耗一般)。
data节点:主要消耗磁盘,内存。
client节点:普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点)。
8.2集群的分配情况
(1)1个节点集群 (3主没有从)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9dfqmtfx-1579249242546)(es笔记.assets/image-20200117113512894.png)]
(2)2个节点(3主3从)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BVlDhM8w-1579249242549)(es笔记.assets/image-20200117113601475.png)]
(3)扩容–>3主3从扩展达到最优效果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f97OGJs9-1579249242550)(es笔记.assets/image-20200117113623771.png)]
(4)容错–>3主3从容错效果
如果主分片所在的节点服务挂掉,会把对应从升级为主 , 挂掉的服务如果再次启动,会把(升级为主的从节点还原到从节点)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-73w7sg5c-1579249242552)(es笔记.assets/image-20200117113653723.png)]
8.3 搭建3个节点集群(了解)
(1) 拷贝三份ES服务
(2)修改jvm的参数配置
(3)修改每个节点配置
# 统一的集群名
cluster.name: my-ealsticsearch
# 当前节点名
node.name: node-1
# 对外暴露端口使外网访问
network.host: 127.0.0.1
# 对外暴露端口
http.port: 9201
#集群间通讯端口号
transport.tcp.port: 9301
#集群的ip集合,可指定端口,默认为9300
discovery.zen.ping.unicast.hosts: [“127.0.0.1:9301”,”127.0.0.1:9302”,”127.0.0.1:9303”]
(4)配置跨域
(5)通过head工具来测试
9 通过java代码操作ES(练习)
连接es服务:
// 得到client对象
public TransportClient getTransportClient() throws UnknownHostException {
//嗅探的方式连接集群
Settings settings = Settings.builder().put("client.transport.sniff", true)
.build();
TransportClient transportClient = new PreBuiltTransportClient(settings).addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
return transportClient;
}
文档新增
@Test
public void testAdd() throws UnknownHostException {
//得到连接对象
TransportClient client = getTransportClient();
//得到builder对象
IndexRequestBuilder builder = client.prepareIndex("crm2", "employe", "1");
//准备数据
HashMap mp = new HashMap();
mp.put("id","1");
mp.put("name","小亮亮");
mp.put("sex","女");
builder.setSource(mp);
//执行代码
IndexResponse indexResponse = builder.get();
client.close();
}
//查询操作
@Test
public void testGet() throws UnknownHostException {
//得到连接对象
TransportClient client = getTransportClient();
//得到builder对象
System.out.println(client.prepareGet("crm2", "employe", "1").get().getSource());
client.close();
}
//修改操作
@Test
public void testUpdate() throws UnknownHostException, ExecutionException, InterruptedException {
TransportClient transportClient = getTransportClient();
IndexRequest indexRequest = new IndexRequest("crm2", "employe", "1");
Map mp = new HashMap();
mp.put("id","1");
mp.put("name","靓仔");
UpdateRequest updateRequest = new UpdateRequest("crm2", "employe", "1");
UpdateRequest upsert = updateRequest.doc(mp).upsert(indexRequest);
//修改
transportClient.update(upsert).get();
transportClient.close();
}
//删除
@Test
public void testDelete() throws UnknownHostException {
TransportClient transportClient = getTransportClient();
transportClient.prepareDelete("crm2","employe","1").get();
transportClient.close();
}
//批量插入
@Test
public void testBulk() throws UnknownHostException {
TransportClient transportClient = getTransportClient();
BulkRequestBuilder builder = transportClient.prepareBulk();
for(int i=1;i<50;i++){
Map mp = new HashMap();
mp.put("id",i);
mp.put("name","lz"+i);
mp.put("age",18+i);
//添加数据
builder.add(transportClient.prepareIndex("crm3", "employee", "" + i).setSource(mp));
}
BulkResponse responses = builder.get();
if(responses.hasFailures()){
System.out.println("出现问题");
}
transportClient.close();
}
DSL过滤
@Test
public void testDSL() throws UnknownHostException {
//(1)得到client对象
TransportClient transportClient = getTransportClient();
//(2)得到需要查询的builder对象
SearchRequestBuilder builder = transportClient.prepareSearch("crm3").setTypes("employee");
//(3) bool条件 bool { must: {matchall:{}},filter:{range:age}}
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
List<QueryBuilder> must = boolQueryBuilder.must();
must.add(QueryBuilders.matchAllQuery());
//(4)组装 年龄范围查询
boolQueryBuilder.filter(QueryBuilders.rangeQuery("age").gte("10").lte("60"));
builder.setQuery(boolQueryBuilder);
//(5)分页
builder.setFrom(2).setSize(5);
//(6)排序
builder.addSort("age", SortOrder.ASC);
//(7)查询字段
builder.setFetchSource(new String[]{"id","age"},null);
//(8)执行
SearchResponse response = builder.get();
//(9)打印结果
SearchHits hits = response.getHits();
System.out.println("总数据"+hits.getTotalHits());
SearchHit[] hits1 = hits.getHits();
for (SearchHit searchHitFields : hits1) {
System.out.println(searchHitFields.getSource());
}
}

















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









