



文章目录
一、HTTP 报文是什么?
-
想象一下,你(客户端/浏览器)和服务器(网站)之间在进行一场对话,或者更准确地说,是在互相寄包裹。
-
HTTP报文,就是在这个网络世界里传输的“包裹”本身。 -
这个包裹里装的可能是你点的歌(音频数据)、你想要看的网页(HTML代码),或者你提交的账号密码。
-
HTTP报文主要分为两类:
请求报文 (Request):你去敲服务器的门:“嗨,给我一张皮卡丘的图片”(就像你填写的外卖订单)。
响应报文 (Response):服务器回复你:“好嘞,图片给你。”或者“抱歉,没货了”(就像送达的外卖)。
二、拆解报文
无论是请求还是响应,这个“包裹”的结构都非常标准,分为四层。我们把它想象成一个快递箱:
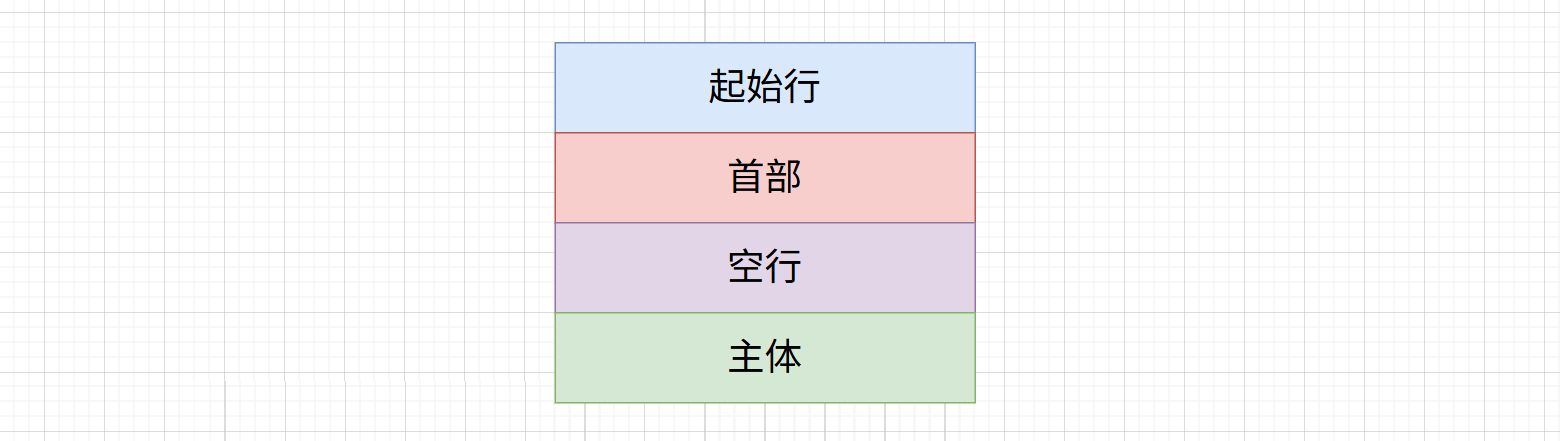
第一层:起始行
这是最关键的一行,写在最上面,告诉对方这个包裹是干嘛的。
如果是请求(你发给服务器):
- 写着:我要做什么(比如
GET获取数据,POST提交数据) + 我要找什么(网址路径) + 我是什么版本HTTP/1.1。 - 人话翻译: “服务器,我要
GET那个叫做/index.html的菜单,我用的是普通话HTTP/1.1交流。”
如果是响应(服务器发给你):
- 写着:版本 + 状态码(200, 404等) + 短语。
- 人话翻译: “我是用普通话
HTTP/1.1回复你的,结果是200 OK,也就是成功发货!
第二层:首部
这里有一堆密密麻麻的信息,用来描述包裹的属性,但不是包裹里的东西。
比如:
Host: 寄给谁的?Content-Type: 里面装的是文本还是图片?User-Agent: 我是用什么浏览器(Chrome/Edge)发的?Content-Length: 这个包裹有多重(多少字节)?
形象理解: 就像快递单上贴的:“易碎品”、“请勿倒置”、“重1kg”、“发件人:张三”
第三层:空行
这层非常简单,就是一个空行。
- 作用: 它是为了把上面的“标签信息”和下面的“实际货物”隔开。
- 形象理解: 电脑是很笨的,它读到这个空行就知道:“哦!标签读完了,下面开始是正经东西了
第四层:主体
这才是你真正想要的数据。
- 在请求中: 如果你在登录,这里装的就是你的“用户名和密码”;如果你在上传头像,这里装的就是“图片数据”。(如果是简单的获取网页
GET,这里通常是空的)。 - 在响应中: 这里装的就是你看到的网页代码、图片数据、视频流等
请求报文示例:
GET /hello.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept-Language: zh-CN
(此处为空行,GET请求通常没有主体)
响应报文示例:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2023 12:28:53 GMT
Content-Type: text/html
Content-Length: 25
(此处为空行)
<html><body>Hello</body></html>
三、报文的特性
3-1 报文分离
数据变成了连绵不绝的 0 和 1 在网线上传输,接收方的 OS 怎么切分这些数据?这里要区分OS内核层和应用层的处理方式
- 内核层:
当数据包到达网卡时,最先处理它的是操作系统内核。内核非常忙,处理速度必须极快
定长报头的优势: TCP 头和 IP 头通常有固定的最小长度(如 20 字节),或者在固定位置写了头长度
OS 的操作: 操作系统不需要逐个字符去读,它直接切下前 20 个字节:“这是 IP 头,我看懂了,扔掉”;再切下 20 个字节:“这是 TCP 头,我看懂了,扔掉”
结合点: 协议设计成“定长”或“固定位置描述长度”,是为了让 OS 内核能用最高的效率剥离头部,取出里面的货物(HTTP 报文)
- 应用层:
当 OS 把剥离好的数据包交给浏览器(应用层)时,拿到的是 HTTP 报文。HTTP 是文本协议,头部长度不固定。
分离头部与主体(空行):程序不得不逐个字节扫描,直到发现 \r\n\r\n(空行)。这比解析定长头部慢,但对人类更友好。
分离主体与下一个请求(Content-Length):因为 HTTP 的 Body(比如图片)里面啥字符都有,不能用特殊符号结尾。所以 HTTP 必须在头部里放一个 Content-Length: 1000,这本质上是模拟了“定长”的思想:告诉程序,“读完空行后,再往后数 1000 个字节,就是完整的结构体数据
3-2 报文分用
网线传来的数据包里,不仅有你浏览网页的数据,还有 QQ 聊天的消息。操作系统怎么知道把这个结构体还原给谁?
端口号:在操作系统内部,每一个联网的程序(进程)启动时,都要向 OS 申请一个 端口号(Port)
Web 服务器(Nginx): 拿着 80 号号码牌。
SSH 服务: 拿着 22 号号码牌
OS 的分发过程
-
数据包到达:操作系统的网络协议栈收到一个
TCP段,它读取TCP头部(定长报头),看到 目标端口号:80。 -
查表(分用):
OS内核里有一张巨大的Hash Map(哈希表)记录了每个端口对应的进程,OS发现这是给进程1024的 -
唤醒与传递:
OS此时把这堆数据(HTTP 报文),从内核空间拷贝到Nginx进程的用户空间内存里。然后唤醒Nginx -
结构体还原(反序列化):
Nginx醒来,读取这段内存,按照HTTP规则解析,把字符串重新填回到它自己的struct HttpRequest结构体中
3-3 报文的本质
HTTP 报文在教科书里是字符串,但在程序员和操作系统(OS)的眼里,它其实是一个被压扁的结构体
在你的浏览器(客户端进程)或者 Nginx(服务端进程)的内存里,HTTP 请求并不是一串乱糟糟的字符,而是一个井井有条的 对象(Object) 或 C语言结构体(Struct)
struct HttpRequest {
int method; // 1 代表 GET, 2 代表 POST
char* url; // 指向 "/index.html"
char* host; // 指向 "www.baidu.com"
int body_len; // 1024 字节
void* body_data; // 指向具体的图片数据
};
公司 A(你的电脑)想把这个 struct HttpRequest 发给公司 B(服务器),你不能直接把内存地址传过去!因为公司 B 的内存里没有这个地址,那是你家里的内存
序列化:操作系统和网络库合作,把这个立体的结构体,按照 HTTP 协议的规则,打印成平面的字符串流(即 HTTP 报文),method=1 转换成字符串 GET,url 转换成字符串 /index.html,加上空格、换行符 \r\n
这就是 HTTP 报文的本质:它是结构体在网络传输时的“临时形态”(序列化形态)
四、报文的传输
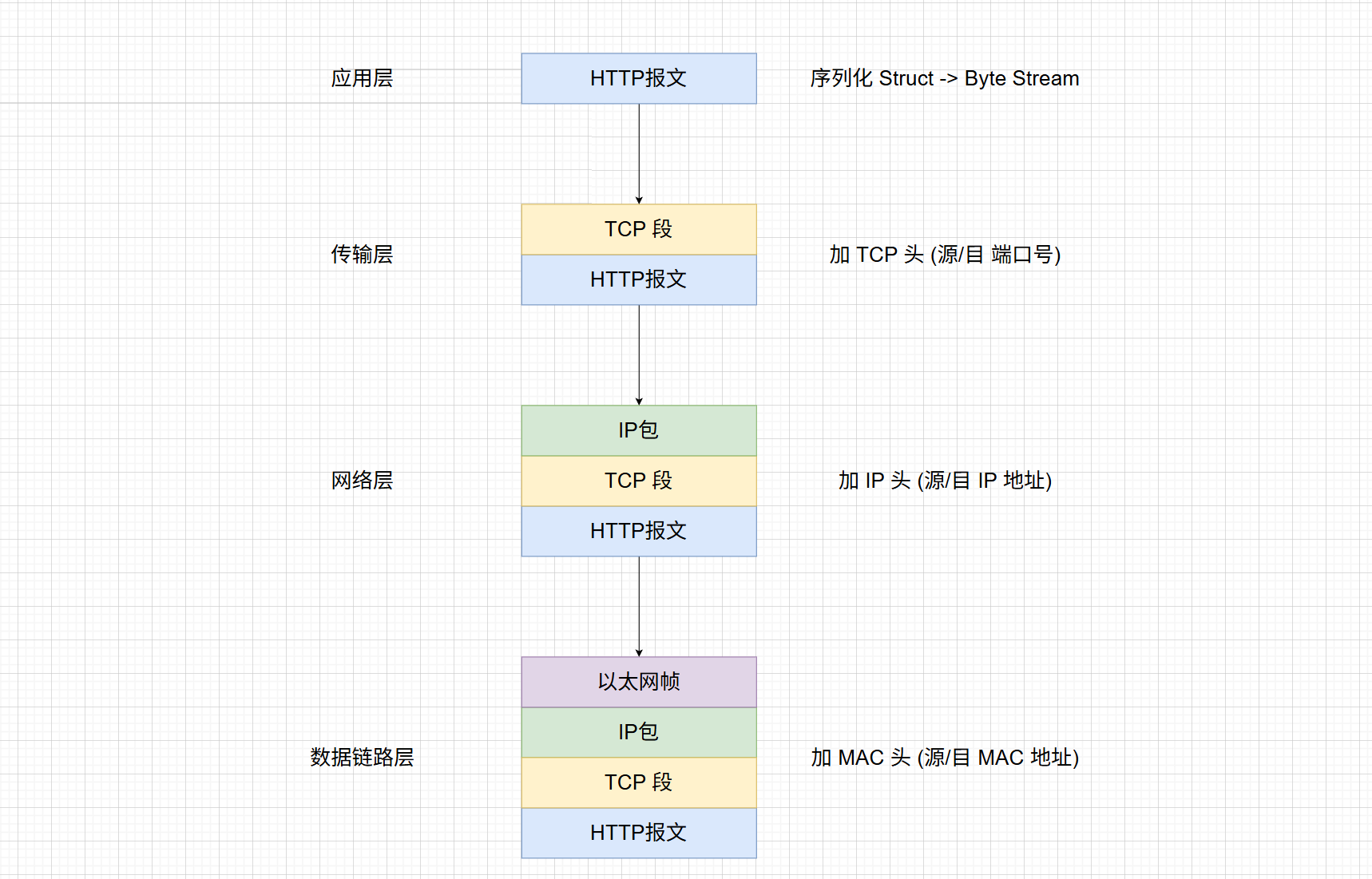
我们把数据从你的电脑传到服务器的过程,想象成寄一个俄罗斯套娃”,或者“层层打包的过程,准确地说,HTTP 数据(货物)是在应用层生成的,但真正能在网络上跑的“标准化快递箱TCP 段是由传输层制造的,下面我们按照发送数据(下楼)的顺序,结合结构体和OS的知识来演示全过程
场景:你在浏览器输入网址,敲下回车
- 第一步:应用层
浏览器(应用程序)构建了一个 HTTP 请求结构体(就是我们刚才说的 struct),状态:此时它是纯粹的数据,比如 GET /index.html HTTP/1.1...,在OS的视角这就是一坨存在内存里的用户数据
- 第二步:传输层
建立端到端的连接,生成 TCP 报文段 ,数据进入内核空间。TCP 协议栈接管数据,内核在 HTTP 数据前添加 TCP 头部(通常 20 字节),TCP 头部包含 源端口和 目标端口,如果 HTTP 报文过长(超过 MSS,最大报文段长度),TCP 会在此层将数据切割成多个段
这里确立了数据是由哪个进程发出的,以及要发给对方哪个进程
- 第三步:网络层
寻址与路由,生成 IP 数据包,内核在 TCP 段的前面继续添加 IP 头部,IP 头部包含 源 IP 地址 和 目标 IP 地址,这里确立了数据要从哪台主机发往哪台主机。
- 第四步: 数据链路层
物理寻址,生成以太网帧,内核或网卡驱动在 IP 包的前后添加 MAC 头部 和 帧尾 (FCS),MAC 头部包含 源MAC 地址 和 目标 MAC 地址,通常是网关/路由器的 MAC,这里确立了数据在物理线路上如何从一个节点跳到下一个节点
五、报文的序号
序号概念位于 传输层的 TCP 协议 范畴
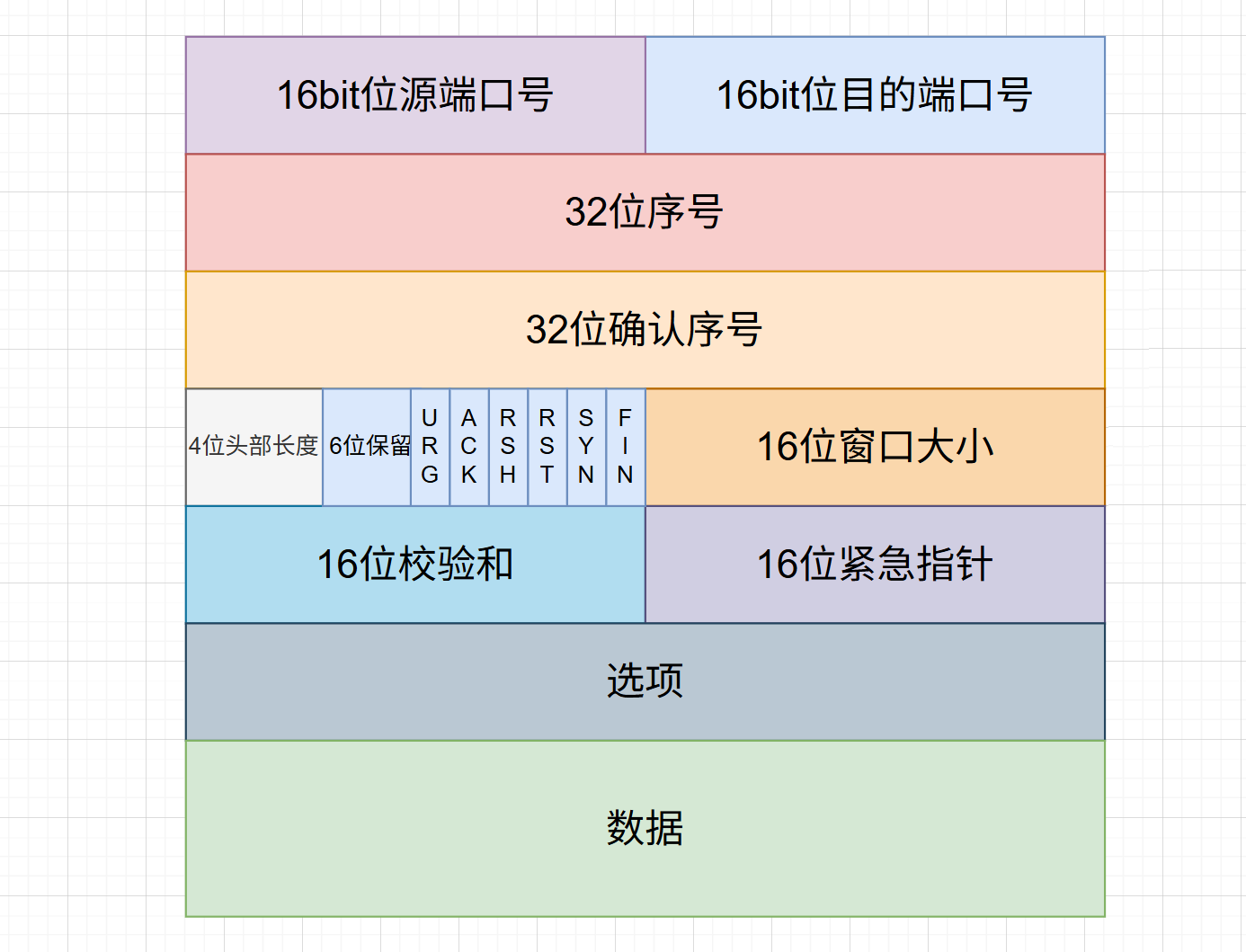
HTTP 报文本身不包含序号,它只是一个长文本,序号和 确认序号是 TCP 协议头部的核心字段
它们的存在是为了解决网络传输中的三大核心问题:丢包、乱序、重复,从而在不可靠的 IP 网络上构建出可靠的字节流传输
5-1 序号的定义
在 TCP 报文段(Segment)的头部中,这两个字段占据了非常重要的位置:
序号 (32位):占据第 4-7 字节
确认序号 (32位):占据第 8-11 字节
5-2 序号
序号表示我发出的数据是从第几个字节开始的,TCP 是面向字节流的协议,而不是面向报文的。这意味着 TCP 会对每一个字节进行编号
TCP序号在工程和文档中一般都用 Seq表示
Seq 值表示本报文段所包含的数据块的第一个字节在整个传输流中的偏移量
初始值:连接建立时(三次握手),操作系统会生成一个随机的初始序号,例如1000,出于安全和避免旧连接干扰,通常不是 0
递增规则:下一个Seq=当前Seq+本报文段数据长度
假设 ISN = 1000,发送端要发送 300 字节的数据,分三个包发,每包 100 字节:
包 1:Seq = 1000,长度 = 100。(涵盖字节 1000~1099)
包 2:Seq = 1100,长度 = 100。(涵盖字节 1100~1199)
包 3:Seq = 1200,长度 = 100。(涵盖字节 1200~1299)
5-3 确认序号
我期待你下次发给我的数据是从第几个字节开始的,
TCP序号在工程和文档中一般都用Ack表示
Ack 是接收端反馈给发送端的,告诉发送端:“我已经收到了哪些数据,请发接下来的数据”,Ack 值表示接收端期望收到的下一个字节的序号,这也意味着:Ack 值 减 1以前的所有字节,接收端都已经全部接收并确认无误
TCP 采用累积确认机制。如果接收端收到了字节 1000 和 1299,但中间缺了 1100~1199,它不能回复 Ack=1300,它只能回复 Ack=1100,这会触发发送端的重传机制
计算公式:Ack=接收到的Seq+接收到的数据长度
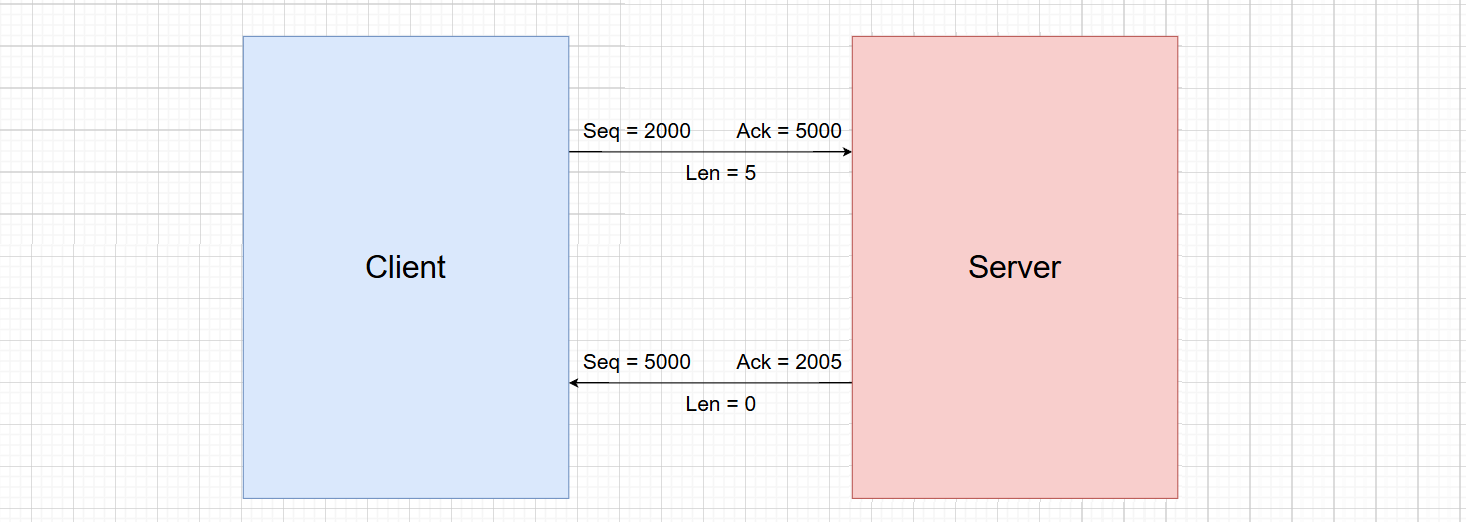
5-4 交互过程演示
假设客户端(Client)向服务端(Server)发送数据。ISN 分别为:Client=2000, Server=5000
场景:Client 发送 “Hello” (5 bytes) 给 Server
Client 发送:Seq = 2000 (这是我数据的起始位置),Ack = 5000 (我之前收到了你 4999 以前的数据,等你发 5000),Len = 5 (“Hello” 长度)
数据流向:2000, 2001, 2002, 2003, 2004
Server 接收处理:Server 内核收到包,检查 Seq=2000,长度=5,计算:2000+5=2005,这说明 2005 以前的数据都齐了
Server 回复 (ACK):Seq = 5000 (Server 发送自己的数据,如果没有数据带载,此处仍是 5000),Ack = 2005 (关键点:确认收到了 Client 的 5 个字节,请发 2005),Len = 0 (纯确认报文,无数据)
5-5 序号的作用
解决乱序:
IP网络路径不同,包 2 可能比包 1 先到达,接收端的TCP栈维护一个 重组缓冲区。- 收到
Seq=1100的包(包2),但OS期望的是Seq=1000(包1)。 OS发现Seq(1100)>Expected(1000),这是一个“未来的包”。OS不会把它放入用户进程的读取缓冲区,而是暂存在重组队列中(红黑树或链表结构)。- 等到包 1 (
Seq=1000) 到达后,OS 将包 1 和包 2 拼好,Ack更新为1200,然后一起交给应用层。
解决丢包:
- 发送端发了包 1,但没收到
Ack,发送端的TCP控制块中维护着一个 重传定时器 - 发送
Seq=1000后,定时器启动 - 如果在超时时间内(RTO)没有收到
Ack >= 1100的包,内核判定丢包 - 内核重新提取发送缓冲区中的该段数据,再次构建
TCP段发送
流量控制与窗口
Seq和Ack实际上定义了滑动窗口的边界- 发送窗口的左边界 = 已确认的
Ack - 发送窗口的右边界 = 已确认的
Ack+ 接收端通告的窗口大小
六、标志位
标志位同样位于 传输层的 TCP 协议头部 中
如果说“序号”和“确认序号”是数据的定位坐标,那么标志位就是控制指令。它们告诉操作系统内核的 TCP 协议栈:“这个报文段是用来干什么的?”(是请求建立连接?是传输数据?还是断开连接?)
在 TCP 首部中,标志位位于“保留位”之后,“窗口大小”之前。传统上有 6 个核心标志位(现代 TCP 增加了 ECN 相关的 CWR 和 ECE,共 8 个),每个标志位占用 1 bit,当某个标志位的值为 1 时,表示该标志生效

6-1 六大核心标志位详解
-
SYN同步位:发起一个新连接,当
Server的操作系统收到一个SYN=1的报文时,它知道有一个Client想要建立连接,如果端口在监听,内核会为这个连接分配内存结构,并进入SYN_RCVD状态,SYN报文消耗一个序号(Seq),即使它不携带数据 -
ACK确认位:确认序号字段有效,只有当
ACK=1时,TCP头部的确认序号字段才会被内核读取和处理,除了握手阶段的第一个报文(SYN 包),在TCP连接建立后的所有报文传输中,ACK标志位必须全部置为1 -
FIN结束位:释放连接,当内核收到
FIN=1,表示对端已经没有数据要发了,内核会将连接状态转变为CLOSE_WAIT(被动关闭)或TIME_WAIT(主动关闭),并准备释放相关内存资源 -
RST重置位:强制断开连接,这是
TCP的“紧急刹车”。当收到RST=1时,内核不会发送任何确认(ACK),而是直接销毁该连接的TCB结构体,释放内存,并通知应用层“Connection Reset by Peer”错误 -
PSH推送位:立即将数据上交给应用层,不要在缓冲区逗留,发送端通常
TCP为了效率,会由Nagle算法控制,凑够一定大小的数据包才发。但如果应用层设置了PSH(或者socket缓冲区写满),内核会立即发送,不等待,接收端内核收到PSH=1的包后,不会等待接收缓冲区填满,而是立即触发“数据可读”事件(如epoll_in),唤醒Nginx或浏览器进程来读取数据 -
URG紧急位:高优先级数据,当
URG=1时,表示报文中有“紧急指针(Urgent Pointer)”指向的数据需要优先处理
6-2 三次握手
我们以最经典的连接建立过程为例,看标志位如何控制 OS 内核的状态机

-
第一次握手 (Client -> Server):标志位:
SYN=1,ACK=0,OS语义:Client 说“我想建立连接,我的初始序号是 X” -
第二次握手 (Server -> Client):标志位:
SYN=1,ACK=1,OS语义:Server 说“确认收到你的请求(ACK生效),我也同意建立连接(SYN生效),我的初始序号是 Y”。 -
第三次握手 (Client -> Server):标志位:
SYN=0ACK=1,OS语义:Client 说“收到你的同意了,连接建立成功”。此后进入数据传输状态
总结
报文的最终形态

















 6万+
6万+



 到【灌水乐园】发言
到【灌水乐园】发言








