 Linux Ext2文件系统与软硬链接详解
Linux Ext2文件系统与软硬链接详解





文章目录
文章目录
前言
本文阅读需要先掌握Ext系列文件系统(硬件篇)
一,ext2文件系统
1-1 宏观认识
- 所有的准备工作已经完成,是时候认识一下
文件系统了。我们想要在硬盘上存储文件,必须先将硬盘格式化为某种格式的文件系统,才能进行文件的读写操作。文件系统的作用就是组织和管理硬盘中的文件和数据。 - 在 Linux 系统中,最常见的是
ext 系列的文件系统。它的早期版本是ext2,后来发展出了ext3和ext4。虽然 ext3 和 ext4 对 ext2 做了许多增强和优化,但其核心设计并没有发生根本性变化,因此我们仍然以较早的 ext2 作为讲解对象。 - ext2 文件系统会将整个分区划分成若干个大小相同的
块组(Block Group),如下图所示。只要能够管理一个分区,就能够管理所有分区,也就能实现对整个磁盘中文件的统一管理。
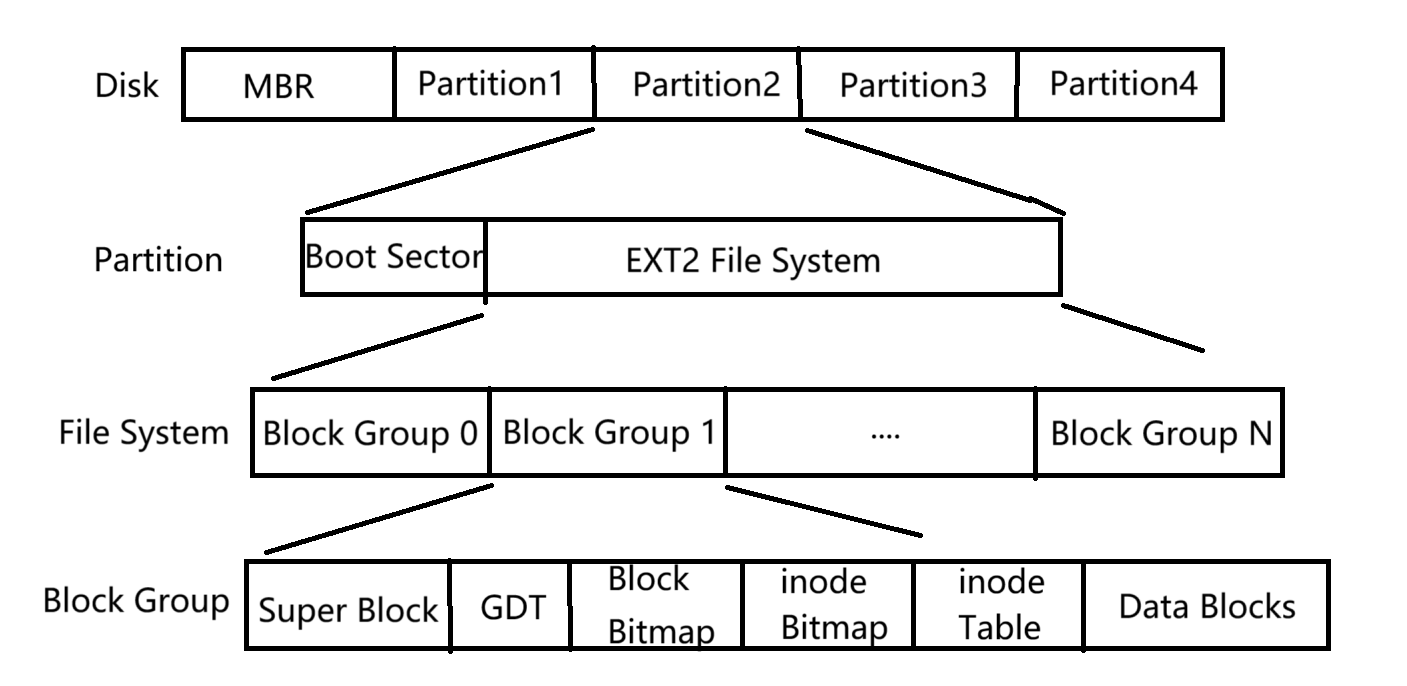
- 在硬盘结构中,最前面的
启动块(Boot Block 或 Boot Sector)大小是固定的,为1KB,这是由 PC 标准所规定的。启动块用于存储磁盘的分区信息(如分区表)以及启动引导程序(Bootloader),是整个系统启动过程中的关键区域。 - 由于启动块的作用十分重要,任何文件系统都不能覆盖或修改它。这也是文件系统在格式化分区时,都会从启动块之后的位置开始布局自身结构的原因。
- 因此,在启动块之后,才是 ext2 文件系统的起始区域,包括
超级块(Super Block)、组描述符表(Group Descriptor Table)、块位图、inode 位图、inode 表等核心结构。
1-2 Block Group
Block Group是 Ext 文件系统为了提升效率而设计的“磁盘管理单元”,类似把大仓库分成多个小房间,每个房间独立管理自己的物品。
1-3 块组内部构成
一个块组由超级块副本、组描述符副本、块位图、inode位图、inode表和数据块组成,用于局部管理文件系统的元数据和文件数据。
1-3-1 超级块(Super Block)
- 超级块(Super Block)是一个结构体用于存放文件系统本身的结构信息,描述整个分区的文件系统状态和配置。它记录了大量关键数据,包括:
block和inode的总数、未使用的block和inode数量、每个block和inode的大小、文件系统创建和挂载的时间、上一次写入数据的时间、上一次进行文件系统检查(fsck)的时间等其他重要的文件系统元信息。 - 由于超级块在整个文件系统中的地位至关重要,一旦其信息被破坏,就可能导致整个文件系统无法识别和使用,因此可以说超级块的损坏等同于文件系统结构的损坏。
- 超级块(Super Block)在每个块组的开头都会保存一份备份拷贝(第一个块组必须包含,后续块组则可以选择是否备份)。为了确保文件系统在磁盘某些扇区出现物理损坏时依然能够正常工作,文件系统会将超级块的信息备份到多个块组中。这些超级块备份区域的数据会保持一致,从而提高文件系统的可靠性和容错能力。
超级块源代码
struct ext2_super_block {
__le32 s_blocks_count; /* 总的 block 数量 */
__le32 s_inodes_count; /* 总的 inode 数量 */
__le32 s_free_blocks_count; /* 未使用的 block 数量 */
__le32 s_free_inodes_count; /* 未使用的 inode 数量 */
__le32 s_log_block_size; /* 一个 block 的大小 */
__le16 s_inode_size; /* 一个 inode 的大小 */
__le32 s_mtime; /* 最近一次挂载时间 */
__le32 s_wtime; /* 最近一次写入数据的时间 */
__le32 s_lastcheck; /* 最近一次检验磁盘的时间 */
....
};
1-3-2 块组描述符表GDT(Group Descriptor Table)
块组描述符表是一个数组用于描述各个块组的属性信息。整个分区被划分为多个块组,因此块组描述符的数量与块组数相同。每个块组描述符记录该块组的关键信息,比如 inode 表的起始位置、数据块的起始位置,以及空闲的 inode 和数据块数量等。为了提高文件系统的可靠性,块组描述符表会在每个块组的开头保存一份备份拷贝。
struct ext2_group_desc {
__le32 bg_block_bitmap; /* 块位图所在块号 */
__le32 bg_inode_bitmap; /* inode 位图所在块号 */
__le32 bg_inode_table; /* inode 表起始块号 */
__le16 bg_free_blocks_count; /* 该块组中空闲块数 */
__le16 bg_free_inodes_count; /* 该块组中空闲 inode 数 */
__le16 bg_used_dirs_count; /* 该块组中已使用的目录数量 */
__le16 bg_flags; /* 标志位 */
__le32 bg_exclude_bitmap_lo; /* 用于防止碎片的排除位图(低32位) */
__le16 bg_block_bitmap_csum_lo; /* 块位图校验和低16位 */
__le16 bg_inode_bitmap_csum_lo; /* inode 位图校验和低16位 */
__le16 bg_itable_unused; /* 未使用的 inode 计数 */
__le16 bg_checksum; /* 描述符校验和 */
/* ext4 扩展字段(高32位校验和等)省略 */
};
1-3-3 块位图(Block Bitmap)
Block Bitmap 是位图数组记录了数据块(Data Block)使用情况,用于标示哪个数据块已经被占用,哪个数据块仍然是空闲的。
1-3-4 inode位图(Inode Bitmap)
inode位图是一个数组每个bit表⽰⼀个inode是否空闲可⽤。
1-3-5 i节点表(Inode Table)
Inode 表(Inode Table)是一个由结构体数组组成的表,每个 inode 结构体存储一个文件或目录的元数据信息(如大小、权限、时间戳、数据块指针等)。
1-3-6 Data Block
数据块(Data Block)是用于存放实际文件内容的区域,不同类型的文件,其数据在数据块中的组织方式有所不同:
- 普通文件(Regular File):文件的实际内容直接保存在数据块中。文件较大时,可能需要多个数据块。
- 目录文件(Directory):目录下的所有子文件名和子目录名保存在数据块中。数据块中保存的是目录项(Directory Entry),每个目录项包含文件名和对应的 inode 编号。至于 ls -l 等命令显示的权限、大小、时间等信息,则存储在对应文件的 inode 中。
- 符号链接、设备文件等特殊文件:其存储结构可能不同,视具体实现而定。
1-4 inode和datablock映射
1-4-1 作用
-
在 inode 结构中,存在一个数组字段:
__le32 i_block[EXT2_N_BLOCKS],其中EXT2_N_BLOCKS = 15,该数组用于指向文件实际存储的数据块(block),实现 inode 到数据块的映射关系。 -
因此,对于文件而言,“文件 = 内容 + 属性” 的结构通过
inode得以完整表示,其中内容通过i_block定位到数据块,属性则直接保存在 inode 中。 -
一个文件的数据可能分布在多个数据块(block)中
-
因为一个数据块大小固定(通常是 1KB、2KB 或 4KB),如果文件很大,就必须使用多个块
-
为了实现从 inode 到这些数据块的映射,inode 中有一个字段:
__le32 i_block[15]; // EXT2_N_BLOCKS = 15
i_block[15] 的结构如下:
- 0 - 11:直接块(Direct Blocks)共 12 个,直接指向数据块
- 12:一级间接块(Indirect Block),指向一个块,这个块中存放的是数据块的地址
- 13:二级间接块(Double Indirect),指向一个块,该块中是一级间接块的地址
- 14:三级间接块(Triple Indirect),原理类似,递归两次,最终指向数据块
例子:
- 如果一个块是 1KB,一个文件大小是 20KB,那就需要 20 个块。
- 前 12 个块可以直接由 i_block[0] 到 i_block[11] 找到。
- 剩下的 8 个就要依赖 i_block[12]
(一级间接块)来继续定位。
创建一个文件:

上图创建文件的流程如下图

- 存储属性(分配 inode)
- 内核首先从
inode 位图中寻找一个空闲 inode(例如编号为 263466),并将该文件的属性信息(如权限、所有者、时间戳、文件大小等)记录到这个inode中。
- 内核首先从
- 存储数据(分配数据块)
- 该文件需要占用 3 个数据块,内核从数据块位图中找到了空闲的数据块编号为:300、500 和 800。
内核将缓冲区中的文件数据依次写入这些块中:
第一个数据块 → 300
第二个数据块 → 500
第三个数据块 → 800
- 该文件需要占用 3 个数据块,内核从数据块位图中找到了空闲的数据块编号为:300、500 和 800。
- 记录分配情况(更新 i_block[])
- 文件内容按顺序存放在块号 300、500 和 800 中。
内核会将这 3 个数据块的编号写入inode的i_block[]数组中,作为该文件的块映射信息。这样,文件的数据位置就与inode建立了连接。
- 文件内容按顺序存放在块号 300、500 和 800 中。
- 添加文件名到目录(建立文件名与 inode 的对应)
- 新文件命名为
"abc"。
内核会在当前目录文件中添加一条目录项(目录项 = 文件名 + inode 号),即:
(abc, 263466)
这样,用户通过文件名 “abc” 就可以在目录中查到对应的 inode 号,从而找到文件的属性和数据内容。
- 新文件命名为
总结:
-
一个 inode 对应一个文件,而 i_block[15] 数组提供了从该 inode 到所有实际存储文件数据的 block 的完整路径。
-
分区完成后的格式化操作,本质上是对该分区进行文件系统的初始化。它会将分区划分为若干个
Block Group(块组),并在每个块组中写入关键的管理信息,如:Super Block(SB)、Group Descriptor Table(GDT)、Block Bitmap、Inode Bitmap、Inode Table等。这些管理信息的集合,统称为文件系统结构。 -
只要知道一个文件的
inode 号,就能通过算法计算出该 inode 位于哪一个块组,再根据该块组中的 inode table 精确定位到这个 inode 的位置。 -
拿到 inode 后,就可以读取该文件的
所有属性(权限、大小、时间等),以及通过i_block[]数组定位到 实际存储内容的数据块,从而获取或修改文件的全部信息。
1-5 目录与文件名
目录也是一种文件,但在磁盘层面,并不存在“目录”这一独立概念,只有“文件属性”和“文件内容”这两个基本构成。
对于目录文件而言,其属性部分与普通文件类似,不再赘述;而其内容部分则保存了文件名与对应 inode 编号的映射关系,用于标识该目录下包含的文件或子目录。
直接看代码
readdir.c
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<dirent.h>
#include<sys/types.h>
#include<unistd.h>
int main(int argc,char *argv[])
{
if(argc != 2)
{
fprintf(stderr,"Usage:%s <directory>\n",argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]);//DIR 是表示目录流的结构体,用于读取目录内容
if(!dir)
{
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;//struct dirent 表示目录中的单个文件项信息
while((entry = readdir(dir))!=NULL)
{
if(strcmp(entry->d_name,".")==0 || strcmp(entry->d_name,"..")==0)//d_name 是目录项中文件或子目录的名称
{
continue;
}
printf("Filename:%s,Inode:%lu\n",entry->d_name,(unsigned long)entry->d_ino);//d_ino 是文件或目录对应的 inode 编号,用于唯一标识文件
}
closedir(dir);
return 0;
}
演示结果
[gch@hcss-ecs-f59a day7]$ gcc -o readdir readdir.c
[gch@hcss-ecs-f59a day7]$ ./readdir /
Filename:proc,Inode:131073
Filename:usr,Inode:393223
Filename:boot,Inode:131077
Filename:mnt,Inode:131084
Filename:sys,Inode:131074
Filename:opt,Inode:131085
Filename:root,Inode:524290
Filename:var,Inode:524291
Filename:tmp,Inode:131075
Filename:media,Inode:131083
Filename:working,Inode:1835009
Filename:sbin,Inode:16
Filename:home,Inode:131082
Filename:lib64,Inode:15
Filename:CloudrResetPwdAgent,Inode:264516
Filename:lib,Inode:13
Filename:dev,Inode:393217
Filename:lost+found,Inode:11
Filename:etc,Inode:393218
Filename:.autorelabel,Inode:14711
Filename:run,Inode:524289
Filename:srv,Inode:131086
Filename:bin,Inode:17
[gch@hcss-ecs-f59a day7]$ ls -li /
total 68
17 lrwxrwxrwx. 1 root root 7 Jul 26 2024 bin -> usr/bin
131077 dr-xr-xr-x. 5 root root 4096 Jul 15 12:58 boot
264516 drwxr-xr-x 7 root root 4096 Jul 26 2024 CloudrResetPwdAgent
1026 drwxr-xr-x 19 root root 3020 Jul 15 13:03 dev
393218 drwxr-xr-x. 78 root root 4096 Jul 25 08:55 etc
131082 drwxr-xr-x. 3 root root 4096 Jul 15 13:05 home
13 lrwxrwxrwx. 1 root root 7 Jul 26 2024 lib -> usr/lib
15 lrwxrwxrwx. 1 root root 9 Jul 26 2024 lib64 -> usr/lib64
11 drwx------. 2 root root 16384 Jul 26 2024 lost+found
131083 drwxr-xr-x. 2 root root 4096 Apr 11 2018 media
131084 drwxr-xr-x. 2 root root 4096 Apr 11 2018 mnt
131085 drwxr-xr-x. 2 root root 4096 Apr 11 2018 opt
1 dr-xr-xr-x 123 root root 0 Jul 15 13:03 proc
524290 dr-xr-x---. 5 root root 4096 Jul 15 19:33 root
1259 drwxr-xr-x 24 root root 640 Jul 25 09:12 run
16 lrwxrwxrwx. 1 root root 8 Jul 26 2024 sbin -> usr/sbin
131086 drwxr-xr-x. 2 root root 4096 Apr 11 2018 srv
1 dr-xr-xr-x 13 root root 0 Jul 15 13:05 sys
131075 drwxrwxrwt. 13 root root 4096 Aug 8 15:53 tmp
393223 drwxr-xr-x. 13 root root 4096 Jul 26 2024 usr
524291 drwxr-xr-x. 19 root root 4096 Jul 26 2024 var
1835009 drwxrwxrwx 3 root root 4096 Jul 15 14:59 working
所以在文件系统里,访问一个文件需要经过以下步骤:
打开当前目录
因为文件名只是存在目录文件里的一个名字,目录本身也是一种文件,保存着“文件名和对应inode号”的映射关系。根据文件名查找 inode 号
通过读取当前目录文件的内容,找到对应文件名所关联的inode(文件索引节点)编号。通过 inode 访问文件内容
inode 记录了文件的元信息和数据存储位置,系统根据inode可以定位到文件实际内容,从而实现文件访问。
重点是:
-
文件系统访问文件不是直接通过文件名,而是先打开包含该文件的目录,读取目录内容找到文件对应的 inode。
-
因此,必须知道“当前工作目录”(即当前所在的目录),才能打开它,查找目标文件的 inode,才能访问文件。
1-6 路径解析
-
访问文件时,必须先打开当前工作目录文件,查看其内容,因为目录文件保存着
文件名与 inode号的映射关系。当前工作目录本身也是一个目录文件,要访问它,必须知道它的inode号。 -
因此,要访问当前工作目录,需要先打开它的上级目录。上级目录也是目录文件,访问它同样需要知道其
inode,进而访问其上级目录。如此形成了一个递归过程,需要依次解析路径中的所有目录,直到根目录/。 -
实际上,任何文件都有一个完整路径,例如
/home/whb/code/test/test/test.c。访问目标文件时,必须从根目录开始,依次打开每一级目录,根据目录名找到对应目录,逐级向下,直到定位到目标文件。这一过程称为Linux 路径解析。 -
由此可见,访问文件必须提供目录和文件名,即完整路径。根目录的文件名和
inode号是固定的,系统启动后即已知,无需查找。 -
路径信息由进程提供,进程维护当前工作目录(CWD),用户在访问文件时通过指令或工具提供路径。
-
Linux 设计根目录以及众多默认目录,是为了构建完整的路径体系。用户也可以自行新建目录,任何新建文件都依附于某个目录,这样天然形成了路径结构。系统和用户共同构建了 Linux 的路径层级结构。
1-7 路径缓存
-
Linux磁盘中不存在
真正的目录,磁盘上只有文件,文件由文件属性和文件内容组成。 -
访问任何文件都需要从根目录
/开始进行路径解析。原则上路径解析是逐层进行的,但为了提高效率,Linux 会缓存历史路径结构。 -
目录的概念由操作系统产生,当打开的文件是目录时,操作系统会在内存中维护路径信息。
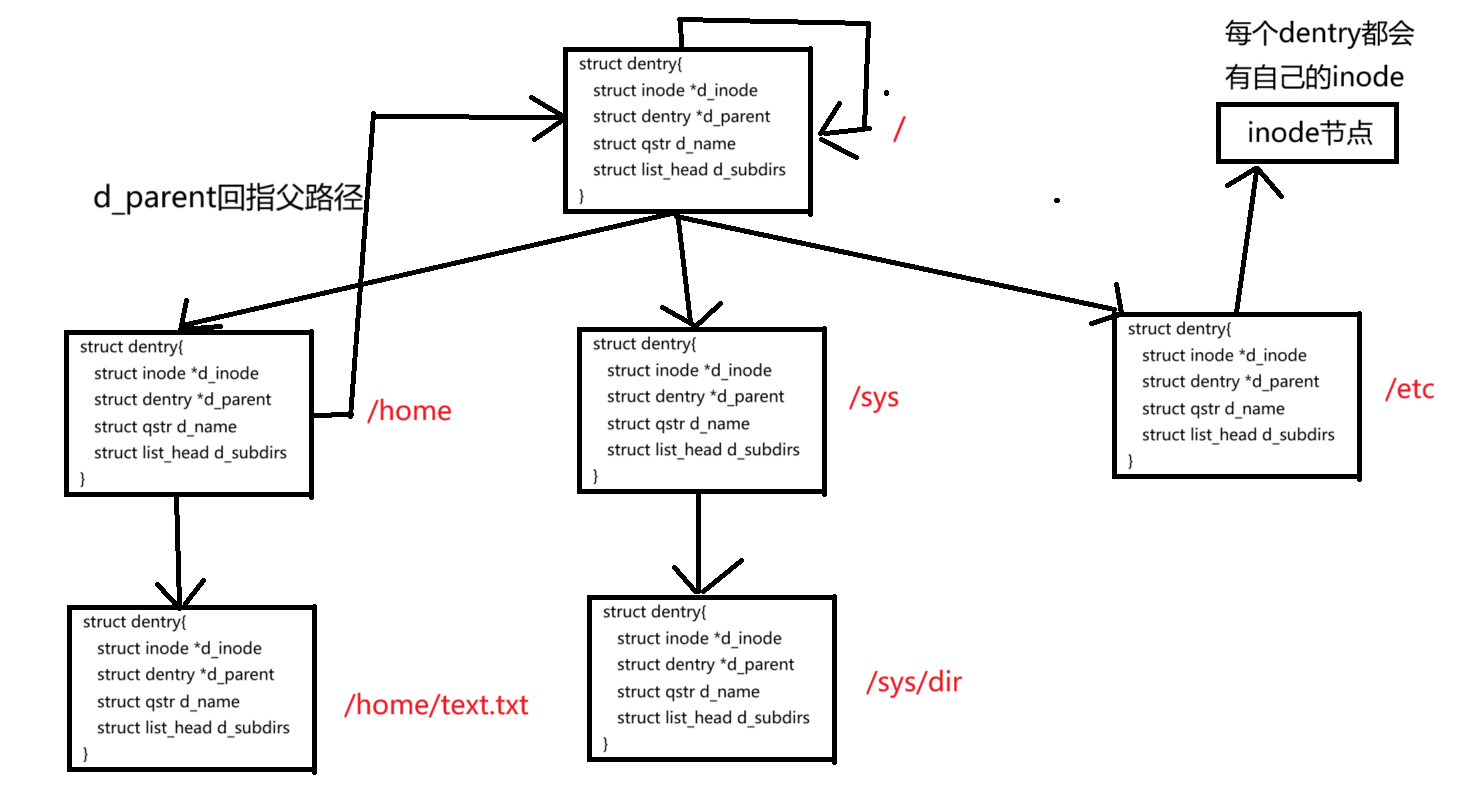
在 Linux 内核中,用于维护树状路径结构的核心数据结构是 struct dentry
struct dentry {
struct inode *d_inode; // 指向该目录项对应的 inode,表示文件或目录的元信息
struct dentry *d_parent; // 指向父目录的 dentry,形成目录树的层级结构
struct qstr d_name; // 目录项的名称,包含名字字符串及其长度、哈希值
struct list_head d_lru; // 用于管理 dentry 缓存的 LRU 链表节点
struct list_head d_subdirs; // 链表头,指向当前 dentry 的所有子目录项,维护目录的子节点链表
// ... 结构体中还有其他成员
};
-
每个文件其实都会对应一个
dentry 结构体,包括普通文件也是这样。这样一来,所有打开过的文件在内存里就能组成一棵完整的树。 -
这棵树的节点同时会被放进一个叫做
LRU(最近最少使用)的结构里,方便系统淘汰不常用的节点,节省内存。 -
另外,这些节点还会被放进
哈希表里,方便快速查找。 -
更重要的是,这整棵树其实就是 Linux 的路径缓存。每次访问文件时,系统会先在这棵树里根据路径查找对应的节点,如果找到了,就直接返回文件的
inode和内容;找不到的话,就从磁盘加载对应路径,创建新的dentry 结构,缓存起来。
1-8 挂载分区
-
我们已经可以根据
inode号在指定的分区中定位文件,也能够通过目录文件的内容找到对应的inode,因此在同一个分区内,文件访问是没有限制的,可以自由操作。 -
但是,inode 编号在不同分区之间并不通用,不能跨分区使用。而 Linux 系统通常会包含多个分区,这就带来了一个问题:在访问文件时,系统必须明确知道当前所处的是哪个分区。
-
为了解决这个问题,Linux 文件系统会为每个挂载的分区(也就是文件系统)维护一个挂载点,并记录每个分区的
根 inode和挂载路径。通过这些挂载信息,系统就可以确定路径中每一级目录属于哪个分区,从而正确地解析每个目录项和inode的对应关系,实现跨分区的路径解析。
struct mount {
struct mount *mnt_parent; // 指向父挂载点(如 /mnt/usb 的父是 /mnt)
struct dentry *mnt_mountpoint; // 指向挂载点目录的 dentry,比如 /mnt
struct vfsmount *mnt; // 指向挂载的文件系统信息(早期叫 vfsmount)
struct list_head mnt_children; // 所有挂载在此挂载点下的子挂载点
struct list_head mnt_instance; // 用于将 mount 实例插入全局链表
};
二,软硬链接
2-1 硬链接
我们可以看到,在 Linux 中真正用来定位磁盘上文件的,其实不是文件名,而是 inode。文件名只是一个“门牌号”,而 inode 才是找到文件内容的“钥匙”。
实际上,Linux 允许多个不同的文件名指向同一个 inode,这意味着它们共享同一份文件内容。这种机制就叫做硬链接。换句话说,多个文件名可以像“别名”一样,共同指向同一个文件实体。
[gch@hcss-ecs-f59a day7]$ touch adc
[gch@hcss-ecs-f59a day7]$ ln adc def
[gch@hcss-ecs-f59a day7]$ ls -li
total 16
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 adc
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 def
比如 adc 和 def 两个文件,它们其实指向的是同一个 inode,链接状态完全一样。这种情况被称为硬链接,它们本质上是同一个文件,只是有两个不同的文件名而已。
内核会记录这个 inode 被多少个文件名引用,这个数字叫做硬链接数。比如 inode 编号为 263466 的文件,它的硬链接数是 2,就说明有两个名字(比如 abc 和 def)指向它。
当我们删除一个文件时,其实做了两件事:
1.== 从目录中把这个文件名的记录删掉==;
2. 把对应 inode 的硬链接数减 1。
如果减到0,说明没有任何文件名再指向这个 inode,系统就会把它对应的磁盘空间释放掉,文件内容才会真正消失。
2-2 软链接
在 Linux 中,硬链接是通过共享 inode 来引用同一个文件;也就是说,多个文件名指向同一个 inode,文件内容完全相同,彼此是“平级”的,没有主从关系。
而软链接(符号链接)是通过路径名来引用另一个文件,本质上是一个独立的文件,它里面保存的是目标文件的路径。软链接的 inode 和原文件不同,可以看作是一个快捷方式。
[gch@hcss-ecs-f59a day7]$ ll
total 0
-rw-rw-r-- 2 gch gch 0 Aug 8 16:48 adc
-rw-rw-r-- 2 gch gch 0 Aug 8 16:48 def
[gch@hcss-ecs-f59a day7]$ ln -s adc abc
[gch@hcss-ecs-f59a day7]$ ls -li
total 0
1835333 lrwxrwxrwx 1 gch gch 3 Aug 8 16:58 abc -> adc
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 adc
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 def
2-3 软硬链接对比
硬连接(Hard Link)——同一个人多个名字
特点:
-
多个文件名 → 指向 同一个 inode(身份证)
-
内容完全一致,本质上是“同一个文件”
-
删除任意一个文件名不会影响文件本身,除非所有名字都删掉
-
只能用于同一个分区
比喻:
就像一个人叫“张三”,又被朋友叫“老三”。
无论你叫哪个名字,他还是同一个人(inode)。
软连接(Symbolic Link)——指向地址的快捷方式
特点:
-
文件名中保存的是“
另一个文件的路径” -
是一个独立的文件,拥有自己的 inode
-
被链接的目标文件如果被删除或移动,链接就失效(变成断链)
-
可以跨分区
比喻:
就像你电脑桌面上的快捷方式(.lnk 文件)。
它指向某个程序的位置,但自己不是真正的程序。
如果程序被删除,快捷方式就打不开了。

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









