



 本文介绍了ELSKE模型,一种针对大规模文本的关键词提取方法。该模型基于改进的TF-IDF排序算法,能适应文档集合的增长,解决传统方法在长文本中的效率问题。提取关键词主要包括高效提取候选词组和考察候选词组集合两个步骤,通过删除Stop-words、长词组和短词组,优化结果。
本文介绍了ELSKE模型,一种针对大规模文本的关键词提取方法。该模型基于改进的TF-IDF排序算法,能适应文档集合的增长,解决传统方法在长文本中的效率问题。提取关键词主要包括高效提取候选词组和考察候选词组集合两个步骤,通过删除Stop-words、长词组和短词组,优化结果。
2021SC@SDUSC

本文内容
传统的关键词、词组提取方法可分为两个流程:一是找出一系列的候选词组集合;二是通过评估每个词的重要性得分找出最符合条件的词组。
一、ESKLE模型的基本思想
关键词提取技术可以用在各种各样的地方。比如社交媒体往往会是大量段文本的集合,并且随着时间推移,文本会逐渐增多。当前存在的很多方法不能满足实时分析这些增长的文本集合的需求,因为他们要么代价太大,要么对于关键词的结构有着很严格的约束。ELSKE方法旨在高效提取文档集合的关键词,并且在独立文档上也表现出惊人的竞争力。
ELSKE提出了一个基于改进后的TF_IDF的排序算法,使其能够适应大量文本的关键词提取:
T
F
−
I
D
F
(
v
i
)
=
f
s
(
v
i
)
l
n
N
f
d
(
v
i
)
TF-IDF(v^{i} )=f_{s}(v^{i}) ln\frac{N}{f_{d}(v^{i})}
TF−IDF(vi)=fs(vi)lnfd(vi)N
P F − I D F ( p j ) = s ( p j ) = f s ( p j ) 1 μ l n N f d ( p i ) PF-IDF(p^{j} )=s(p^{j})=f_{s}(p^{j})^{\frac{1}{\mu}}ln\frac{N}{f_{d}(p^{i})} PF−IDF(pj)=s(pj)=fs(pj)μ1lnfd(pi)N
上面两个公式,是ELSKE的核心排序思想。
在TF_IDF中,最大的问题是TF_IDF会受到源文档的规模的影响:比如随着源文档规模逐渐增大, f s ( v i ) f_{s}(v^{i}) fs(vi)的值将会不断增大,将逆文档频率与其相乘,值仍然会十分大。此时,逆文档频率就难以对整体的得分产生较大的影响,从整体上看,TF_IDF将会对长文本有利。因此,ELSKE提出了PF_IDF,其核心是一种对词频的一种归一化方法。通过将 f s ( p j ) f_{s}(p^{j}) fs(pj)与 1 μ \frac{1}{\mu} μ1做幂运算得 f s ( p j ) 1 μ f_{s}(p^{j})^{\frac{1}{\mu}} fs(pj)μ1,可以很好的对于文档的长度进行自动的适应。
这个 μ \mu μ将这样的到:设置一个文档规模的限制,我们设置为500。当文档的可能出现的最大词数 f s m a x f_{s}^{max} fsmax高于这个限制时, μ = l o g 500 f s m a x \mu=log_{500}f_{s}^{max} μ=log500fsmax(否则 μ = 1 \mu=1 μ=1)这样就很好的完成了归一化,解决了文档规模问题。
二、步骤1:高效提取候选词组
我们的目标是提取前k个关键词组,但是直接对1,2,3,4…元词组,逐一计算其源文档词组频率,以及逆文档频率显得十分不现实(尤其是在文本规模大了之后,提取的关键词组长度会开始没有止境,工作量巨大,提取十分缓慢),采用下面步骤提取候选词组,就可以极大的加速该过程。
1)提取1,2元词组
第一步,我们取出“1,2元词组”(不包含STOP WORDS),计算出其对应的PF-IDF的值 s ( p i ) s(p^{i}) s(pi),并按照降序排序。
我们将排好序的结果以下面结构存储:
| p j p^{j} pj | f s ( p j ) f_{s}(p^{j}) fs(pj) | f d ( p j ) f_{d}(p^{j}) fd(pj) | s ( p j ) s(p^{j}) s(pj) 即PF-IDF值 |
|---|---|---|---|
| director | |||
| costume | |||
| scene |
第二步,我们将求出一个限制值 f t h f^{th} fth。在后面提取更长词组的操作中,任何在最终前k个中的词组其文档频率 f s ( p j ) ⩾ f t h f_{s}(p^{j})\geqslant f^{th} fs(pj)⩾fth。 f t h f^{th} fth的确定方法,假设k位置处的 s ( p i ) s(p^{i}) s(pi)值 s k s^{k} sk是最低限制,则有
f t h = ( s k l o g N ) μ f^{th}=(\frac{s_{k}}{logN})^{\mu} fth=(logNsk)μ
2)提取3,4,5…元词组
我们将取出“3,4,5…元词组”(不能全是STOP WORDS,也不能只出现一次)
有如下规律:2元词组的频率 f s ( p j ) f_{s}(p^{j}) fs(pj)是任何包含这个词组的父词组的最大频率。
第一步,使用前面步骤所得的“存储的表格”以及 f t h f^{th} fth值,我们将含有小于 f t h f^{th} fth的子词组的多元词组去除,的到“3,4,5…元的候选词组”的集合。
3)去除多余的子词组
对任意词组 ( v 1 i , . . . , v m i ) (v_{1}^{i},...,v_{m}^{i}) (v1i,...,vmi),我们都有m-1个子词组 ( v 1 i ) (v_{1}^{i}) (v1i) ( v 1 i , v 2 i ) (v_{1}^{i},v_{2}^{i}) (v1i,v2i)…
我们将 f s ( p j ) f_{s}(p^{j}) fs(pj)值和原父词组相等的子词组删除。
4)计算每个候选词组的文档频率
计算每个候选词组的文档频率 f s ( p j ) f_{s}(p^{j}) fs(pj),并计算出他们对应的PF-IDF值 s ( p j ) s(p^{j}) s(pj),若 s ( p j ) < s k s(p^{j})<s_{k} s(pj)<sk,则将其删除。
提速方法:建造一个2元词组在参考文档集合上的索引。
三、步骤2:考察候选词组的集合
在上一步结束后,我们其实已经可以根据PF-IDF值 s ( p j ) s(p^{j}) s(pj)来选出前k个了,然而,我们在这里要进一步删去一些有重复的词组,再选出前k个,以达到令人满意的结果。
1)删除Stop-words比重大的候选词组
有些词组有很多Stop-words但是却仍然出现在候选词组集合中,可能是由于大比重的Stop-words让它们最终超过限制,我们将这些词组除去:
如果一个词组它只包含一个非Stop-word,并且这个词的 s ( v i ) < s k s(v_{i})<s_{k} s(vi)<sk,就将这个词组删除。
2)删除长的候选词组
如果 p j p^{j} pj包含 p i p^{i} pi,则称 p j p^{j} pj为 p i p^{i} pi的更长词组,比如at a birthday party 和 birthday party 。
如果 p j p^{j} pj比 p i p^{i} pi在前面或后面多了最多两个词语,我们称 p j p^{j} pj比 p i p^{i} pi多的词语为overhang。
我们将保留这样一些长词组:overhang自己的PF-IDF值足够高。
s
(
v
j
)
⩾
λ
s
k
s(v_{j})\geqslant\lambda s_{k}
s(vj)⩾λsk
s
(
(
v
j
,
v
j
+
1
)
)
⩾
λ
s
k
s((v_{j},v_{j+1}))\geqslant\lambda s_{k}
s((vj,vj+1))⩾λsk
我们设置
λ
=
0.1
\lambda=0.1
λ=0.1
3)删除短的候选词组
有些短一点的候选词已经可以很好地被长的候选词表达,比如"memorial day"和"stpatricks day"就能覆盖大多数"day"出现的场合,因此我们希望删掉"day"
对某一个候选词
p
i
p^ {i}
pi,令
M
i
⊆
U
M^{i}\subseteq U
Mi⊆U为最短的互异的长词组集合:
p
j
∈
M
i
p^{j}\in M^{i}
pj∈Mi,
p
l
∈
M
i
p^{l}\in M^{i}
pl∈Mi,二者互不包含,且互相矛盾(指都包含
p
i
p^ {i}
pi并且在相同方向延伸)。我们将这样的
p
i
p^ {i}
pi删除:
s
(
p
i
)
−
∑
j
∈
M
i
s
(
p
j
)
<
s
k
s(p^{i})-\sum _{j\in M^{i}}s(p^{j})<s_{k}
s(pi)−j∈Mi∑s(pj)<sk
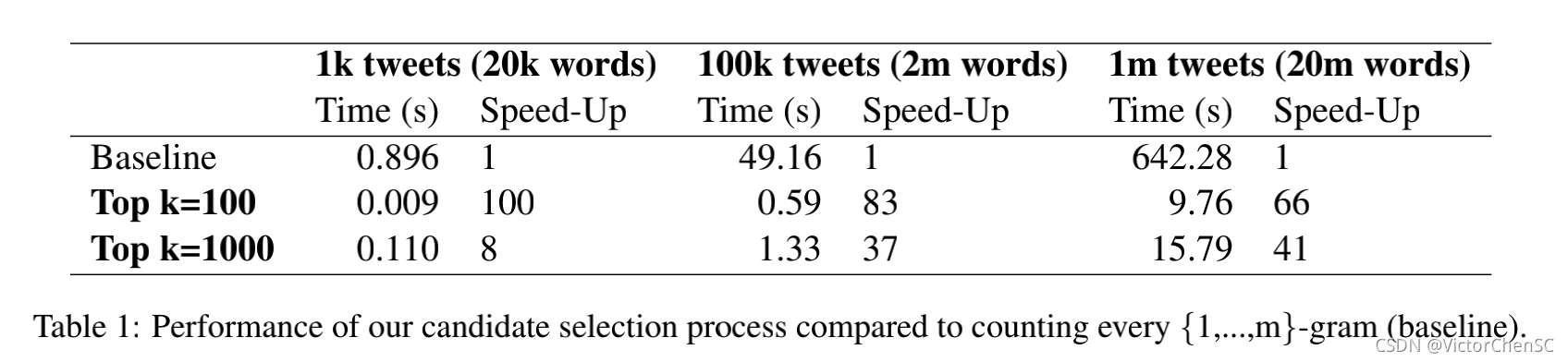
四、性能展示



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









