




一.原理
从库从主库读取二进制日志信息,实现同步
二.环境
两台ubuntu16.04(x86_64)虚拟机
ip:192.168.3.221(主); 192.168.2.254(从)
mysql版本:14.14 Distrib 5.7.23, for Linux(x86_64)
三.配置(以下操作在root用户下)
1.修改mysql配置文件
在本系统中,配置文件位置:
/etc/mysql/mysql.conf.d/mysqld.cnf修改配置如下:
主数据库(192.168.3.221)中进行
[mysqld]
log-bin = /var/log/mysql/mysql-bin.log #开启二进制日志,用于从数据库读取
server-id = 1 #设置server-id
bind-address = 0.0.0.0 #默认是127.0.0.1,此处设置为任意地址,放开远程访问(在登陆mysql时,还是需要有权限的用户才能登陆,这里只是开放了对从数据库同步数据的ip限制),这么操作之前一定要确保防火墙配置正确,否则会产生安全风险。本例不做防火墙处理。
从数据库(192.168.2.254)中进行
[mysqld]
server-id = 2 #设置server-id,必须唯一
log_bin = /var/log/mysql/mysql-bin.log #日志也最好打开2.为从数据库创建用户
主数据库(192.168.3.221)中进行
用户名:czh_test2
密码:123456
mysql>GRANT REPLICATION SLAVE ON *.* TO ‘czh_test2’@’192.168.2.254’ IDENTIFIED BY ‘123456’;
mysql>FLUSH PRIVILEGES;3.查看主数据库二进制日志文件名和位置
主数据库(192.168.3.221)中进行
mysql>SHOW MASTER STATUS;
4.告知从数据库读取二进制文件方式
从数据库(192.168.2.254)中进行
mysql>CHANGE MASTER TO
>MASTER_HOST=’192.168.3.221’,
>MASTER_USER=’czh_test2’,
>MASTER_PASSWORD=’123456’,
>MASTER_LOG_FILE=’mysql-bin.000007’,
>MASTER_LOG_POS=11847;5.开启主从复制
mysql>START SLAVE;四.查看和测试
1.查看从数据库配置主从复制信息
从数据库(192.168.2.254)中进行
mysql>show slave status\G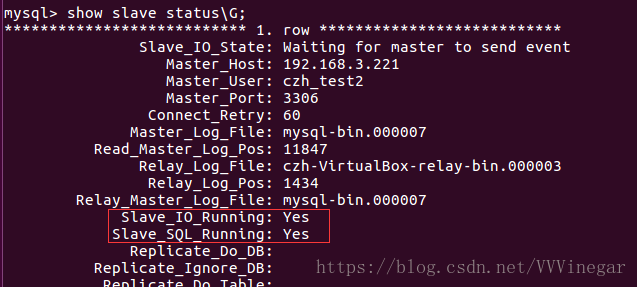
当看到Slave_IO_Running: YES、Slave_SQL_Running: YES才表明状态正常。
否则大概是同步出了问题,一般先执行
mysql>stop slave;再重新执行三.3——三.5,八成就好了。
2.测试
在主数据库新建数据库,新建表,从库也会看到新建的表。
从库登陆mysql用的不是上边主库分配的账号,是从库自己的账号。

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









