



目录
这三个文件不知道你们下载了多久,反正我下载了半天,感觉烦透了,所以整理了一下,需要文件的我已经整理好了,可以直接在官网:zhixuanxingqiu.com 下载
直接拿走!3 个核心模型文件
做 EasyOCR 文字识别 / 自动化工具,这 3 个文件是刚需,缺一不可:
- 📌
craft_mlt_25k.pth:文本检测模型(负责定位图片中的文字区域) - 📌
zh_sim_g2.pth:中文识别模型(精准识别简体中文) - 📌
english_g2.pth:英文识别模型(支持英文文本识别)
已经整理下载好了
不用再去官网慢慢等,也不用怕下载失败,直接去我官网:zhixuanxingqiu.com 就能拿到,解压后直接用,零配置门槛~
文件下载
解压完毕
亲测可用!做了个工具实测效果
文件下载完,大家肯定会问:“能不能用?会不会有问题?”
为了验证文件有效性,我专门做了一个高颜值的图像识别测试软件(界面简约清晰,操作超简单),实测下来完全没问题!
图像识别软件展示
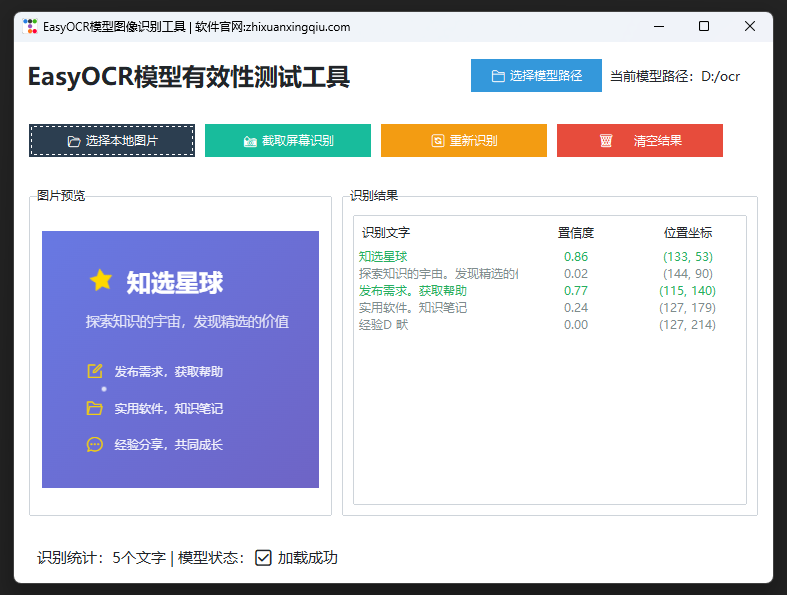
软件核心功能:
- 📂 选择本地图片识别:支持 png、jpg、bmp 等常见格式,上传即识别
- 📸 截取屏幕识别:一键截图,实时识别屏幕上的文字(比如文档、网页、软件界面)
- 📊 清晰展示结果:识别文字、置信度(准确率)、位置坐标一目了然,置信度≥0.5 的文字还会高亮标注
实测效果:
随便找了张包含中文、英文的图片测试,软件秒识别出所有文字,结果准确又清晰;截图识别也超丝滑,屏幕上的按钮文字、文档内容都能精准捕捉,完全满足日常文字识别、自动化脚本的需求~
可以看到可以正常识别图片文字,更多玩法拿到文件后自己用AI进行探索。
用 AI 生成直接生成图像识别工具
拿到文件后,不止能直接用,还能让 AI 帮你快速生成专属图像识别软件,步骤简单到离谱!
给 AI 的提示词直接抄:“用 Python+EasyOCR 做一个图像识别工具,核心模型使用这三个文件:craft_mlt_25k.pth(文本检测)、zh_sim_g2.pth(中文识别)、english_g2.pth(英文识别)。工具需要支持本地图片选择和屏幕截图识别,界面美观易操作,能展示识别文字、置信度和位置坐标,模型路径可自定义选择。”
跟着 AI 生成的代码走,几分钟就能搞定一个属于自己的图像识别工具,不管是做自动化办公脚本,还是文字提取小工具,都 so easy!
选择的模型就是我上面提供的这三个文件
文件没问题,软件没问题
需要的各位可以直接在官网获取
zhixuanxingqiu.com
总结
本来以为下载模型是小插曲,结果耗了半天时间;现在整理好的文件直接拿,解压即用,省去了所有麻烦。
下次再想做图像识别、文字提取、自动化相关的项目,再也不用卡在模型下载上了~
需要的小伙伴直接去官网:zhixuanxingqiu.com 下载,文件没问题,实测能用,拿到手就可以开启你的创作啦!
OK,分享就到这,祝大家开发顺利,拜拜~



















 2628
2628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











