




摘要:WebUI界面功能分区详解:1)模型选择区包含大模型、VAE等核心组件,决定出图风格与细节;2)提示词区通过正反提示词控制生成内容;3)功能选项区提供文生图/图生图等基础模式;4)参数调整区包含采样方法、尺寸、批次等20+项精细调节参数;5)插件区扩展额外控制维度;6)生成区支持中止/跳过等交互操作;7)展示区呈现成品及参数。系统采用模块化设计,各功能区协同工作,用户可通过灵活配置实现多样化图像生成需求。
学习WebUI的第一步是认识界面都有哪些功能区并初步了解他们的作用,下面我们就web-UI界面的各项功能进行说明。
一张图看懂web-UI界面:功能分区
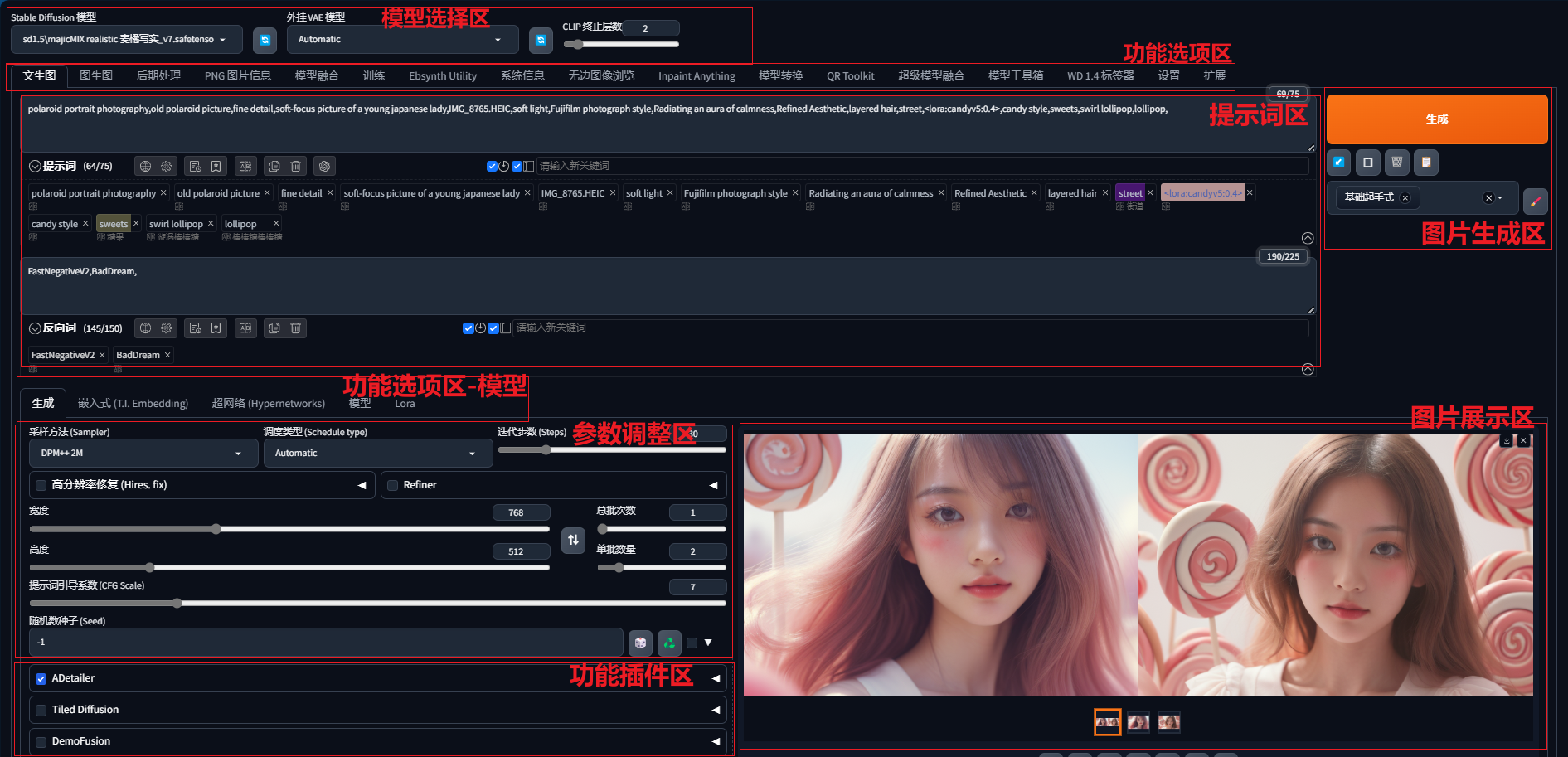
-
1 模型选择区

选择"大模型cheackpoint":我们可以将“大模型”看成不同的“画师”,大模型决定了出图的风格,比如真实系、二次元还有3D效果等;
选择“VAE”:这里先把VAE先看成大模型适配用的滤镜,作用是增加出图细节及丰富色彩,避免出图色调灰暗;
CLIP终止层数:把提示词转化成向量的层数,层数越多语义提取越丰富(数字越小,层数越多),一般保持默认值2即可;
2 提示词区
正向提示词Prompt:告诉SD你想要的,比如画质要求、图中出现的主体、背景等;
反向提示词Negative Prompt:告诉SD不想要的,比如避免畸形、避免多人等不想在图中出现的内容;
3 功能选项区

文生图:通过提示词,生成文字所描述信息相关的图片
图生图:以上传的图片为基础,生成与之有关的图片
-
4 功能选项区/模型

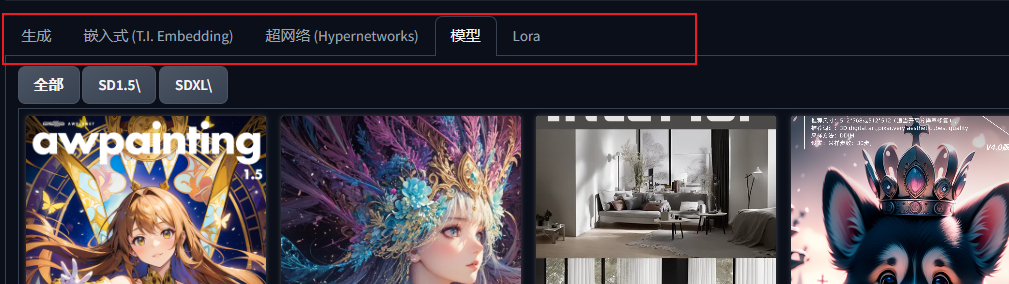
“提示词区”下方的功能选项卡:这里除“生成”页面内调整出图参数、启用功能插件外,其余几个选项卡是指不同类型的模型,点击相应页面内的模型,会自动调用。(“嵌入式”、“超网络”及“lora”指微型模型,在后文进行具体说明)。
5 参数调整区域
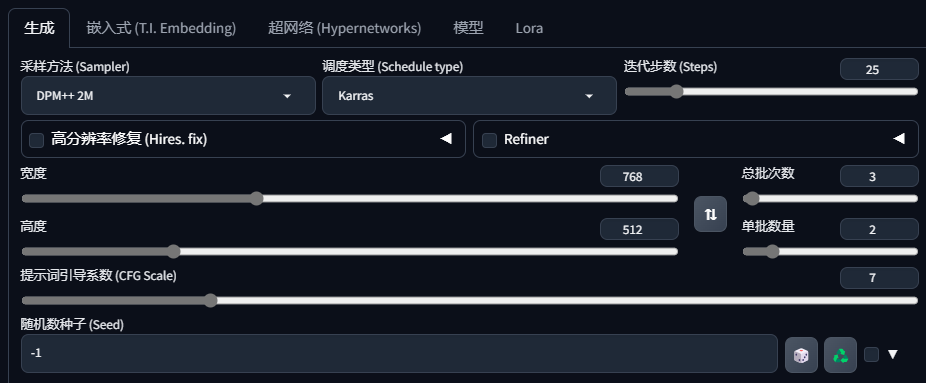

采样方法:生成图片的方式,简单理解为AI在成像过程中的不同算法。
调度类型:主要用于多任务系统的调用方式,一般与采样方法搭配使用。
采样方法与调度类型本身并没有优劣之分,但是他们的出图速度及表现会有区别,一般情况下,推荐使用:Euler a(二次元效果佳)、DPM++ 2M Karras(出图快、细节效果稳定)、DPM++ SDE Karras(真实质感)等。
迭代步数:图片生成过程迭代的次数;人物一般20-30步即可,太高容易出现多人等问题,场景类可以尝试高一些。

高分辨率修复:可以理解为低分辨率尺寸条件下生成图形后,再以图生图模式将图片放大,减小显卡压力,提升出图速度;
Refiner:主要用于出图期间的细节修复,更好地调节图像细节;

高度+宽度:出图尺寸,1.5版大模型一般设置在512*512/512*768等1K分辨率内的尺寸(生育后再进行放大);XL大模型可直接设置1024×1024/1024*1568等较大尺寸。(右侧箭头指图片高宽翻转)
总批次数:总共生成几批次图片;每批次生成结束后,SD会进行内部的计算和处理,然后再开始下一批次的生成,该方式对显卡的负担小。
单批数量:一批生成几张图片,指每次点击生成按钮时SD需要同时处理的图片数量,该方案需要同步处理,对显卡显存的需求较高,一般设置为1。

提示词引导系数CFG Scale:提示词对SD扩散过程的引导程度,CFG值越高,提示词对出图的影响越大(不是越大越好,一般7-12即可,过大容易图像崩坏)。
随机数种子:“-1”是指随机种子,在此情况下,每次出图均使用随机种子,出图均不相同;点击 即“固定种子”,会出现一组序号,这个就是种子的序号,固定种子后其它参数不变的情况下,图片不变。点击“骰子”
即“固定种子”,会出现一组序号,这个就是种子的序号,固定种子后其它参数不变的情况下,图片不变。点击“骰子” 即可再变为随机种子。
即可再变为随机种子。
6 功能插件区
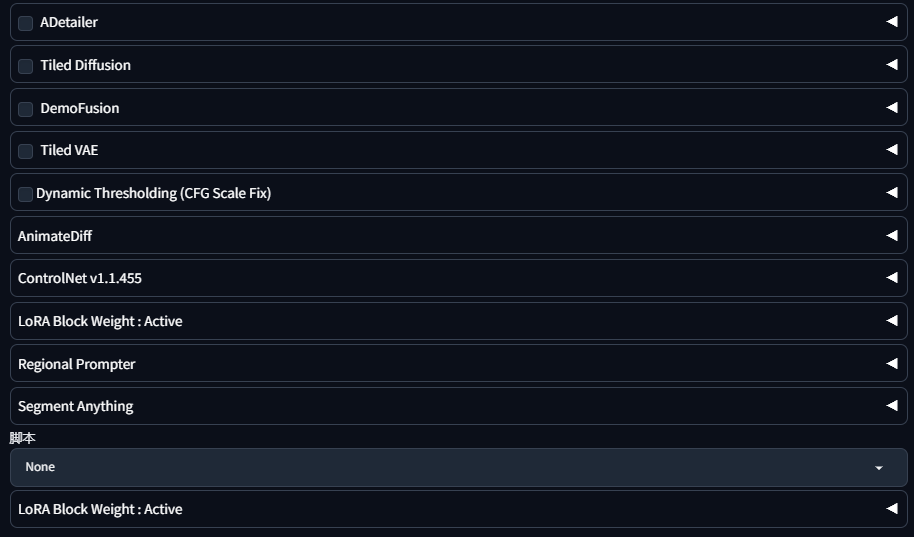
通过启用不同的插件功能,给于SD出图时额外的控制维度,不同的插件有不同的功能,将在后面的文章中对每一个插件进行具体说明。
7 图片生成区
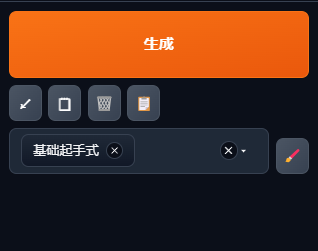
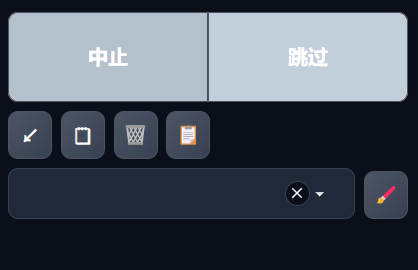
设置好出图参数及提示词后,鼠标左键点击“生成”图标即可启动生图程序,生图过程中会变成右图样式,此时点击“中止”则停止整个出图过程后续出图过程,点击“跳过”则将跳过当前的出图进行下一张图片的绘制。

总批次“4”,生图到第3张时点击“中止”,停止第四张图生成

总批次4,第一张图生图过程点击“跳过”,停止第一张图生成,直接进入第二张图生成
鼠标右键点击“生成”图标则启动无限生图,SD将按照设定参数持续进行出图,常用于多图出图进行抽卡看效果。
“生成”图标下方的主要用于提示词的相关功能,在后续提示词相关章节学习时再进行详细说明。
8 图片展示区
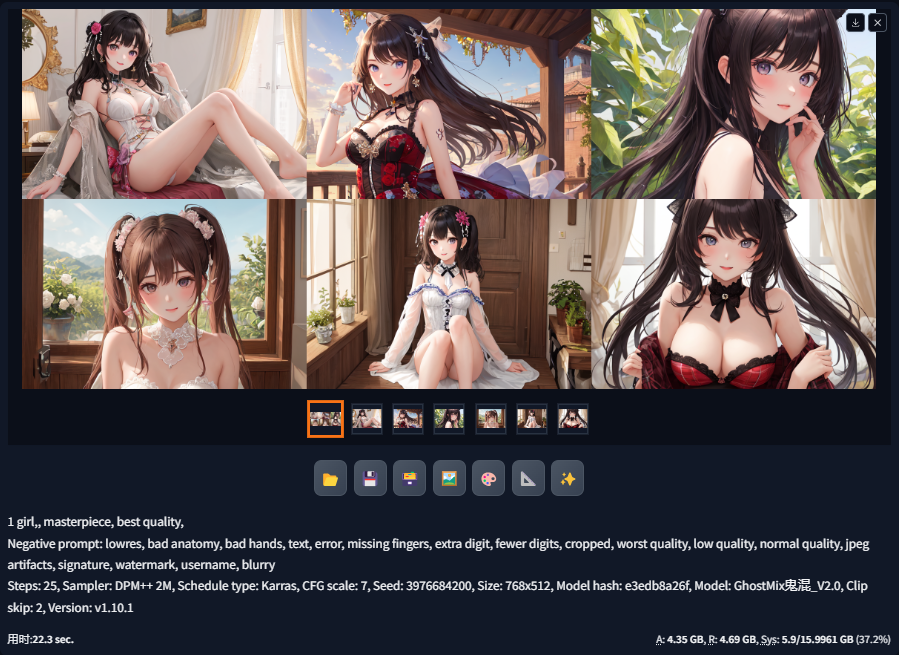
图片展示区:用于展示所生成图片文件的效果,同时底部会显示图片生成的相关参数信息。
图片下部功能选项按钮可以将生成的图片发送至“图生图”的等功能区进行再次编辑。

总结:
这里分享webUI的本地整合包资源,包括秋叶官方基础版本(基础插件和必备模型)及个人自用的整合包(超全插件及模型)两个版本,大家按需下载。
两个版本均为整合包形式,无需安装,Windows系统下载打开即用。
「webui秋叶官方基础包--25G左右」https://pan.quark.cn/s/c1759b141e59
「webui全能包(内置超全插件、模型)--100G左右」https://pan.quark.cn/s/3647679a1966
欢迎正在学习comfyui等ai技术的伙伴V加 huaqs123 进入学习小组。在这里大家共同学习comfyui的基础知识、最新模型与工作流、行业前沿信息等,也可以讨论comfyui商业落地的思路与方向。 欢迎感兴趣的小伙伴,群共享资料会分享博主自用的comfyui整合包(已安装超全节点与必备模型)、基础学习资料、高级工作流等资源……
致敬每一位在路上的学习者,你我共勉!Ai技术发展迅速,学习comfyUI是紧跟时代的第一步,促进商业落地并创造价值才是学习的实际目标。

——画青山Ai学习专栏———————————————————————————————
零基础学Webui:
https://blog.youkuaiyun.com/vip_zgx888/category_13020854.html
Comfyui基础学习与实操:
https://blog.youkuaiyun.com/vip_zgx888/category_13006170.html
comfyui功能精进与探索:
https://blog.youkuaiyun.com/vip_zgx888/category_13005478.html
系列专栏持续更新中,欢迎订阅关注,共同学习,共同进步!
—————————————————————————————————————————




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









