






 ZooKeeper作为一款分布式协调服务,广泛应用于配置中心、命名服务、分布式锁及通知协调等场景。它通过提供一致性的数据存储和更新机制,简化了分布式系统的设计与管理。
ZooKeeper作为一款分布式协调服务,广泛应用于配置中心、命名服务、分布式锁及通知协调等场景。它通过提供一致性的数据存储和更新机制,简化了分布式系统的设计与管理。
一、ZK简介
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是一个精简的文件系统,是Google的Chubby一个开源的实现。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
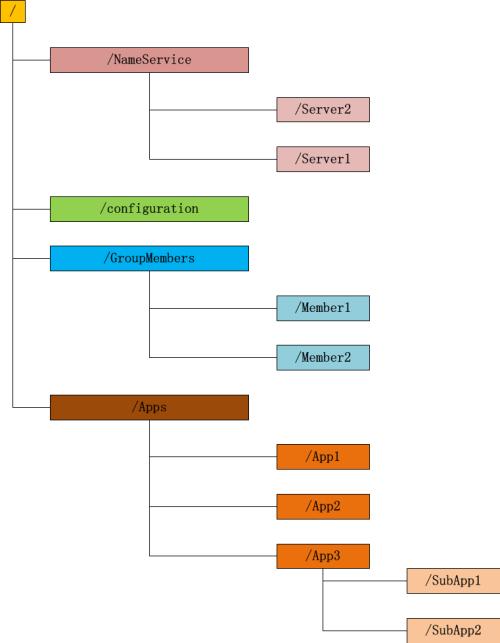
二、应用场景
2.1 配置中心
发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息等就非常适合使用。
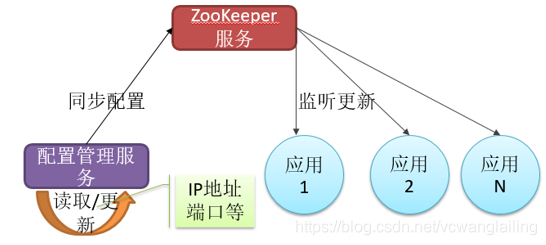
在分布式系统里,我们会把一个服务应用分别部署到n台服务器上,这些服务器的配置文件是相同的,如果配置文件的配置选项发生变化,那么我们就得一个个去改这些配置文件,如果我们需要修改的地方特别多,那么更改配置选项就是一件麻烦而且危险的事情。
这时候zookeeper就可以派上用场了,我们可以把zookeeper当成一个高可用的配置存储器,把这样的事情交给zookeeper进行管理,我们将集群的配置文件拷贝到zookeeper的文件系统的某个节点上,然后用zookeeper监控所有分布式系统里配置文件的状态。
- 应用中用到的一些配置信息放到ZK上进行集中管理。这类场景通常是这样:应用在启动的时候会主动来获取一次配置,同时,在节点上注册一个Watcher,这样一来,以后每次配置有更新的时候,都会实时通知到订阅的客户端,从来达到获取最新配置信息的目的。
- 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在ZK的一些指定节点,供各个客户端订阅使用。
- 分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用来分配收集任务单元,因此需要在ZK上创建一个以应用名作为path的节点P,并将这个应用的所有机器ip,以子节点的形式注册到节点P上,这样一来就能够实现机器变动的时候,能够实时通知到收集器调整任务分配。
- 系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息的问题。引入ZK之后,就不用自己实现一套方案了,只要将这些信息存放到指定的ZK节点上即可。
注意:在上面提到的应用场景中,有个默认前提是:数据量很小,但是数据更新可能会比较快的场景。
2.2 命名服务
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的API,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
2.3 分布式锁
分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
- 所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
- 控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序
2.4 分布式通知、协调
ZooKeeper中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能够收到通知,并作出相应处理。
- 另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。
- 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了ZK上某些节点的状态,而ZK就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。
- 另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。
总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。

















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









