





 超级会员免费看
超级会员免费看

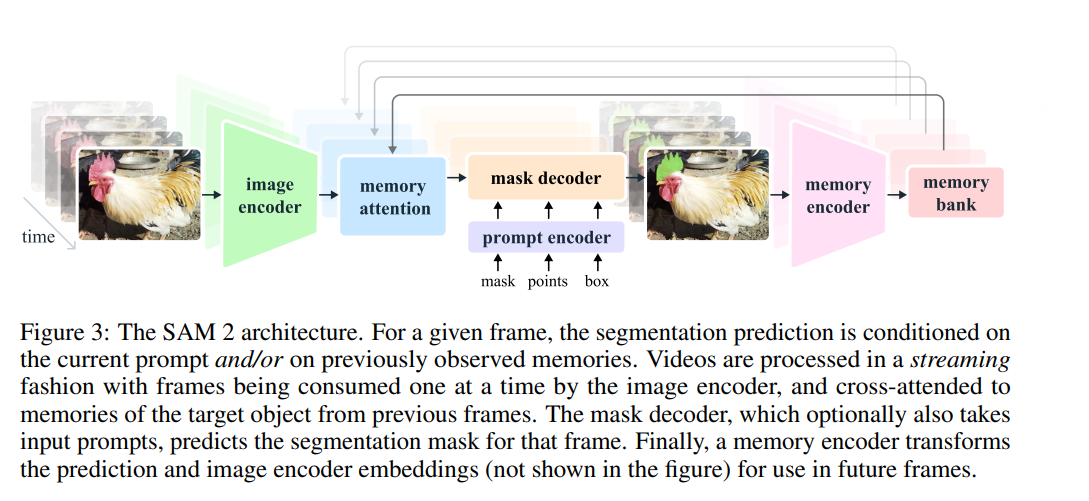
SAM 2 文章核心总结与翻译
一、主要内容总结
SAM 2(Segment Anything Model 2)是一款面向图像和视频的通用提示式分割基础模型,通过统一架构、大规模数据集和交互数据引擎,实现了图像与视频分割任务的高效统一。模型以Transformer为基础,加入流式内存机制支持实时视频处理,在SA-V数据集(含50.9K视频、35.5M掩码)上训练,既保持了图像分割的高精度,又解决了视频分割中目标运动、遮挡、低质量帧等核心挑战,同时提供了更优的交互效率和速度表现。
二、核心创新点
- 任务统一:提出提示式视觉分割(PVS)任务,将图像分割扩展到视频领域,支持点、框、掩码等多种提示类型,可在任意视频帧交互并生成全时序掩码。
- 模型架构:设计流式内存机制,存储历史提示和预测信息,实现视频帧的逐帧处理;采用分层图像编码器(Hiera)和内存注意力模块,兼顾实时性与长时序依赖捕捉。
- 数据引擎与数据集:构建交互式数据引擎,通过“模型-标注者”循环迭代优化数据质量与标注效率,生成的SA-V数据集规模为现有视频分割数据集的53倍,涵盖物体整体与部件、复杂遮挡等场景。
- 性能突破:视频分割中仅需1/3的交互

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 9374
9374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









