



GPU训模型遇到的报错
使用gpu训练模型
调用卡:
import os
os.environ['WANDB_DISABLED'] = 'true'
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3,4,5,6,7'
os.chdir(sys.path[0])
import torch
注意os.environ[“CUDA_VISIBLE_DEVICES”] 要在import torch前面,否则可能无法生效:https://zhuanlan.zhihu.com/p/582993579
是否成功上卡
print(torch.cuda.device_count())
#8gpu
print(torch.cuda.is_available())
#True
上卡失败
1.查看pytorch是否是cpu版本,是的话参考:https://blog.youkuaiyun.com/wqufhu/article/details/129295385
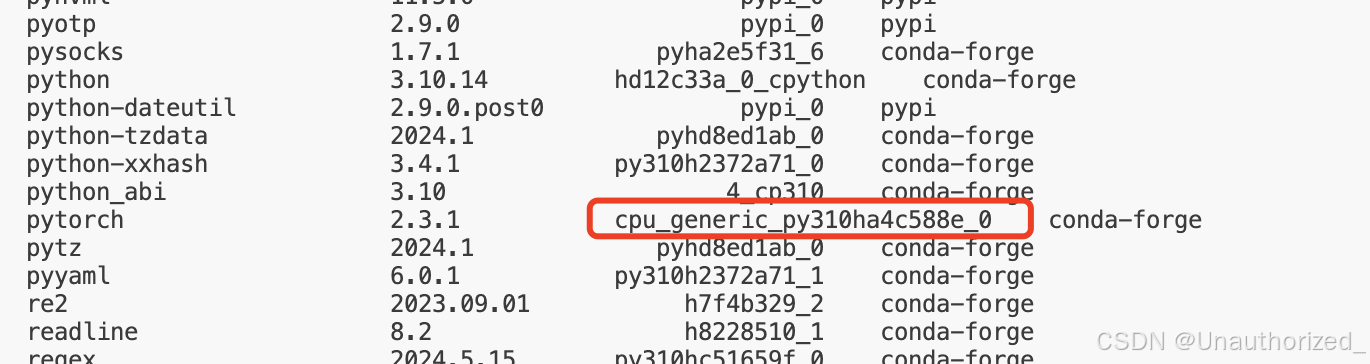
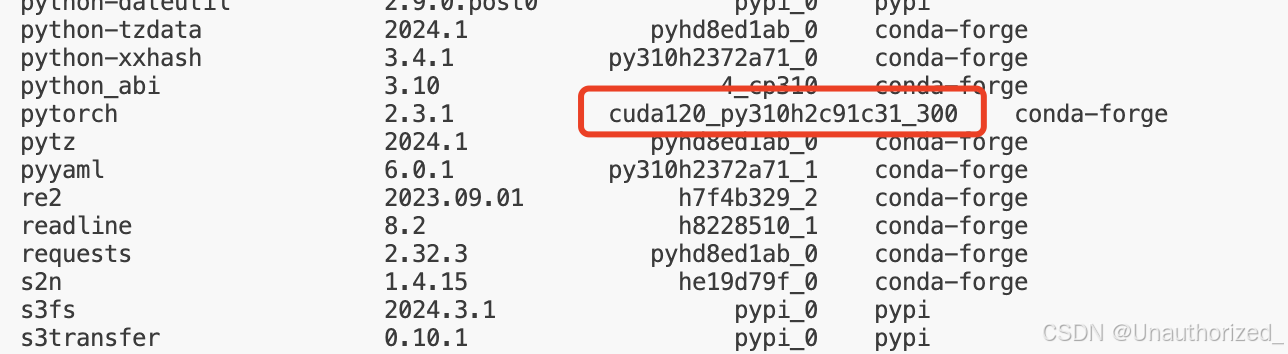
并行模型
if torch.cuda.device_count() > 1:
model.is_parallelizable = True
model.model_parallel = True
dataset加载失败
NotImplementedError: Loading a dataset cached in a LocalFileSystem
is not supported
直接pip install -U datasets
https://blog.youkuaiyun.com/u013250861/article/details/134300884
ValueError: Attempting to unscale FP16 gradients
实际上是环境的问题,可以尝试改变peft的版本
https://blog.youkuaiyun.com/qq_46479446/article/details/136018129
pip install peft==0.4.0
Cuda out of Memory
实际上也是peft的问题
pip install peft==0.4.0
原因不详。只改了这个后就成功了


















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









