




Ethash是以太坊目前使用的共识算法,其前身是Dagger-Hashimoto算法,但是进行了很大的改动。
1. Dagger-Hashimoto
Dagger-Hashimoto算法想要达到以下几个目标:
- 抵制ASIC矿机
- 轻客户端验证
- 全链数据存储
实际上Dagger-Hashimoto是由两种不同的算法Dagger和Hashimoto融合而成的:
Hashimoto
Hashimoto算法由Thaddeus Dryja发明,旨在通过“内存读取”瓶颈来抵制ASIC矿机。ASIC矿机可以通过设计专用电路来提升计算速度,但是很难提升“内存读取”速度,因为经历了这么多年的发展,内存访问已经经过了极致的优化。Hashimoto算法直接采用区块链数据,也就是区块中的交易作为输入源。
注:为了减小计算量,Dagger-Hashimoto中实际上只使用了低64位参与移位。
Dagger
Dagger算法由Vitalik Buterin发明,旨在通过DAG(有向无环图)来同时获得“memory-hard计算”和“memory-easy验证”这两个特性,其主要原理是针对每一个单独的nonce只需要访问数据集中的一小部分数据。Dagger曾经被认为可以替代一些memory-hard的算法(如Scrypt),但是后来被Sergio Lerner证明该算法易于遭受共享内存硬件加速的攻击,从而逐渐被废弃。
Dagger-Hashimoto vs. Hashimoto vs. Dagger
Dagger-Hashimoto和Hashimoto的主要区别是:
Hashimoto直接使用区块链数据作为输入源,而Dagger-Hashimoto使用一个定制的1GB的dataset(数据集)作为输入源,该dataset每隔N个区块会被更新。dataset是通过Dagger算法生成的,轻客户端验证算法可以针对每一个nonce对其中一个子集完成高效计算。
Dagger-Hashimoto和Dagger的主要区别是:
与Dagger不同,Dagger-Hashimoto用于查询区块的dataset是半持久化(semi-permanent)的,需要间隔很长一段时间才会更新。这样生成dataset的工作量比例接近于0,Sergio Lerner用于共享内存加速的参数就可以忽略不计了。
2. Ethash
Ethash算法主要分为以下几个步骤:
- 根据区块信息生成一个seed
- 根据seed计算出一个16MB的伪随机cache,由轻客户端存储
- 根据cache计算出一个1GB的dataset,其中的每一个数据都是通过cache中的一小部分数据计算出来的。该dataset由完整客户端或者矿工存储,大小随时间线性增长
- 矿工会从dataset中随机取出数据计算hash
- 验证者会根据cache重新生成dataset中所需要的那部分数据,因此只需要存储cache就可以了
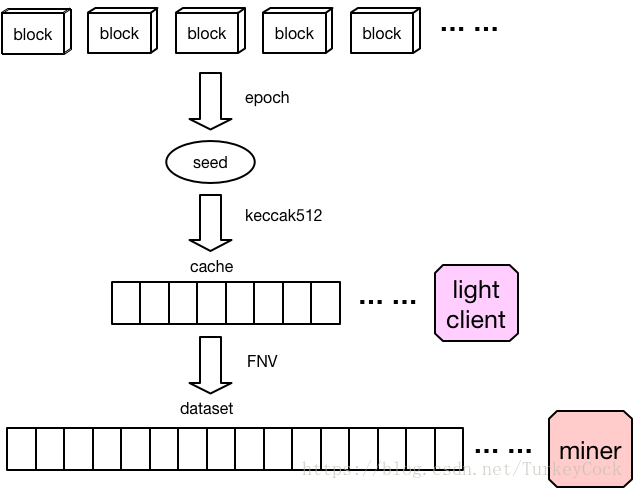
下面分别讨论这几个部分的实现。
2.1 生成seed
consensus/ethash/ethash.go:
func (d 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









