




 本文介绍了一种基于深度学习的肺结核(TB)类型分类方法,通过CT图像的块采样技术,实现了对Drug-Sensitive(DS)和Multi-Drug Resistant(MDR)类型的快速准确区分,准确率达到91.11%。
本文介绍了一种基于深度学习的肺结核(TB)类型分类方法,通过CT图像的块采样技术,实现了对Drug-Sensitive(DS)和Multi-Drug Resistant(MDR)类型的快速准确区分,准确率达到91.11%。
Prediction of Multidrug-Resistant TB from CT Pulmonary Images Based on Deep Learning Techniques
解决的问题:
TB(肺结核)疾病可分为drug-sensitive (DS)和multidrug-resistant (MDR) ,为了发现病人TB所属于的类型,传统的方法是进行复杂的微生物培养菌实验,将持续几个月的时间。因此如何快速,准确的确定TB的所属类型有着重要的意义。
通过CT图像来进行临床分析诊断,以对病人的TB类型进行划分。
贡献:
1.应用块采样的深度学习技术来进行TB的3D分类,方法新颖(patches instead of volume)
2.所用方法成本低,速度快,并且有一个很高的准确率 91.11%
方法:
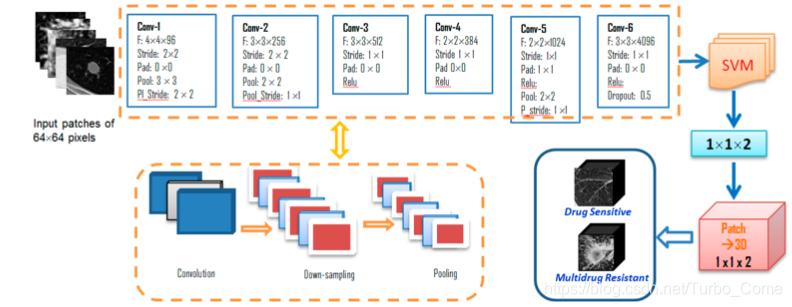
分别对图像进行patch, 然后人工的筛选带有病灶或包含肺部信息的patch,作为其类别的label,来进行分类实验。
Inpput: 64*64灰度图, 首先通过6层网络,每一层的网络设置如图所示。
filter size: 3 × 3× 96, 3 × 3 × 256, 3 × 3 × 512, 2 × 2 × 384, 2 × 2 × 1024, 3 × 3 × 4096
在最后的输出阶段,采用交叉熵损失将得分解释为每个类别的对数概率(未归一化), 之后采用支持向量机(SVM)进行类别划分或Softmax(后续分别做了相关实验),使用铰链损失来鼓励正确的类别得分比其他类别得分高。 每个样本的最终分数根据应用的阈值确定,所有补丁分数计算求和,得出其所属类别的分数。
实验:
230 trian(DS 134, MDR96) ; 214 test
512*512 (55-263 slices)
a volume of 3D TB is downsampled from slices into patches.
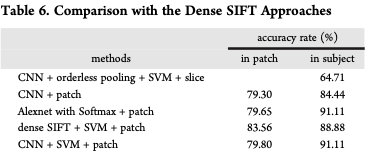
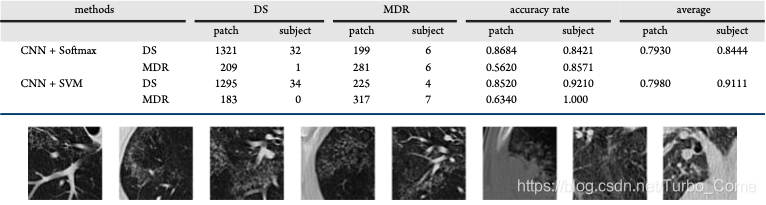
(Dense SIFT算法,是一种对输入图像进行分块处理,再对每一块进行SIFT运算的特征提取过程。SIFT 是一种检测局部特征的算法,通过求一幅图中的特征点及其有关scale 和 orientation 的描述子得到特征并进行图像特征点匹配,获得了良好效果)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









