



1. COUNT()函数作用
COUNT() 是 MySQL 中用于统计记录数量的聚合函数,它是 MySQL 中通用的聚合统计函数,核心作用是统计满足条件的行数。
2.原理
- COUNT(*)作为 SQL 标准定义的行数统计语法,它不针对任何字段,核心是直接判断行是否存在。执行时,优化器会优先选择最精简的索引(主键、二级索引),仅遍历索引记录判断行的存在性,不读取表中任何字段值,每发现一行符合条件的记录,计数器就加 1,全程只关注 行是否存在,是最直接的行数统计逻辑。
- COUNT(1)本质是对虚拟常量列的非 NULL 计数 —— 执行时不会读取表的实际字段,而是为每一行构造一个值为 1 的虚拟列,由于 1 是常量永远非 NULL,因此每遍历到一行符合条件的记录,就会因该虚拟列非 NULL 而让计数器加 1,最终等价于统计行数,但逻辑上是通过常量列计数间接实现,而非直接判断行的存在性。
MySQL 5.6版本之后的优化器会识别到 count(1) 的虚拟列 1 永远非 NULL,其计数逻辑等价于 count(*),因此会将 count(1) 等价转换为 count(*) 后执行,最终二者的索引选择、扫描行数、IO 消耗完全一致,仅底层计数的逻辑表述不同。
3.实践
3.1 COUNT(*)实践
进入实操环节加深一下记忆
表数据如下:
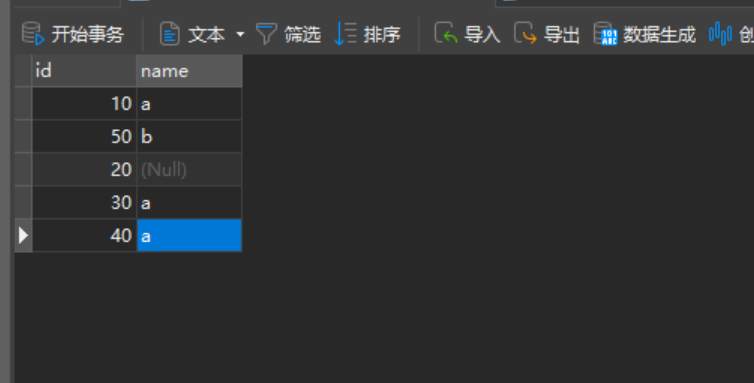
- 当没有 WHERE和 HAVING时,
COUNT(*)用于统计整张表的总行数(包括NULL值),或每个分组的总行数(有 GROUP BY 时)。
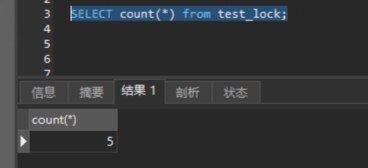
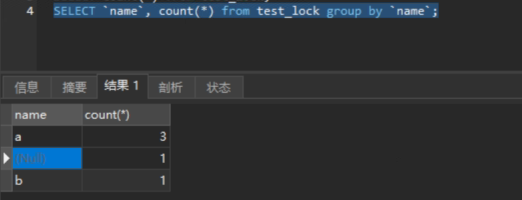
- 有 GROUP BY ,无 WHERE/HAVING → 统计每个分组的行数
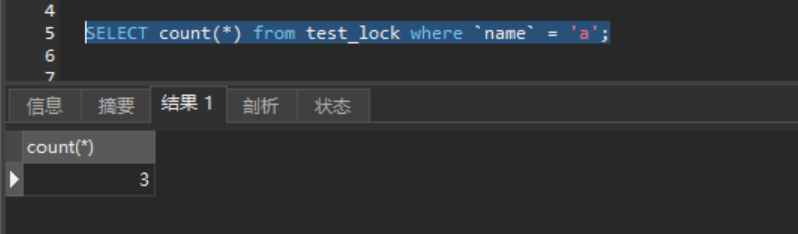
- 有WHERE时,先进行符合条件的过滤,再对行数进行统计
- 有HAVING时,先通过
COUNT(*)是先统计、后过滤分组的逻辑。

COUNT(1) 在WHERE/HAVING以及分组的情况下使用的效果基本等同于COUNT(*)。底层优化器会将 count(1) 等价转换为 count(*) 再优化,最终执行计划完全一致。
4.总结
| 写法 | 是否忽略NULL | 统计逻辑 | 性能 |
|---|---|---|---|
| count(*) | 否 | 统计总行数 | 最优(优化器优先选) |
| count(1) | 否 | 统计常量 1 的非 NULL 行数 | 等价于 count (*) |
| count (字段名) | 是 | 统计该字段非 NULL 的行数 | 更低(需判断 NULL) |

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









