



目录
1. 使用MAT(Memory Analyzer Tool)分析
Step1:Java OOM 的 6 种主要类型
| 类型 | 触发条件 | 典型场景 |
| 1. Heap Space OOM | 堆内存不足,无法分配新对象 | 大对象分配、内存泄漏 |
| 2. Metaspace OOM | 元空间(方法区)存放类元数据耗尽 | 动态生成类(如CGLIB)、反射滥用 |
| 3. Direct Memory OOM | 直接内存(堆外内存)不足 | NIO的 |
| 4. StackOverflowError | 线程栈深度超过限制 | 递归调用无终止条件 |
| 5. GC Overhead OOM | GC耗时超过98%且回收效果低于2% | 小对象频繁分配导致GC恶性循环 |
| 6. Unable to Create Thread | 线程数超过系统限制 | 线程池配置不合理 |
一、快速确认OOM类型
- 查看错误日志:定位OOM的具体区域
# 典型OOM错误示例:
java.lang.OutOfMemoryError: Java heap space # 堆内存溢出
java.lang.OutOfMemoryError: Metaspace # 元空间(方法区)溢出
java.lang.OutOfMemoryError: Direct buffer memory # 直接内存溢出
java.lang.OutOfMemoryError: unable to create new native thread # 线程数超限二、收集关键数据
1. 确保JVM启动参数已开启以下配置
# 启用GC日志记录(必选项)
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:/path/to/gc.log
# 在OOM时自动生成堆转储文件(强力推荐)
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/path/to/heap_dump.hprof
# (可选)保留元空间/OOM现场信息
-XX:+PrintClassHistogramBeforeFullGC # Full GC前打印类直方图
-XX:NativeMemoryTracking=detail # 监控非堆内存2. 手动触发堆转储(若未配置自动转储)
# 找到Java进程PID
jps -lv | grep <app-name>
# 生成堆转储文件(耗时操作,谨慎执行)
jmap -dump:format=b,file=/path/to/heap_dump.hprof <PID>
# (备用)强制Full GC后转储(仅限开放SA的JVM)
jmap -dump:live,format=b,file=dump.hprof <PID>三、实时监控GC状态
1. 使用 jstat 观察GC活动
# 每隔1秒输出一次GC统计(关键指标)
jstat -gcutil <PID> 1000
# 输出字段说明(重点关注列):
# S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
# Survivor区 Eden区 老年代 元空间 压缩类空间 YoungGC次数 耗时 FullGC次数 耗时 总耗时
# 持续FullGC(FGC列持续增长)且Old区(O列)未下降 → 内存泄漏2. 使用 top/htop 查看进程内存占用量
top -p <PID> # 观察RES(物理内存)、VIRT(虚拟内存)变化四、分析堆转储文件
1. 使用MAT(Memory Analyzer Tool)分析
- 步骤1: 下载 MAT工具,加载
.hprof文件 - 步骤2: 查看关键报告:
-
- Leak Suspects Report(自动泄漏分析)
- Dominator Tree(内存支配树,找到最大的对象)
- Histogram(按类统计对象数量及内存占用)
- 典型泄漏线索:
-
- 某个类的实例数异常多(如
HashMap$Node、业务自定义类) - 线程局部变量(ThreadLocal)未清理
- 静态集合(static List/Map)持续增长
- 某个类的实例数异常多(如
2. 使用命令行快速分析
# 查看对象直方图(未安装MAT时使用)
jmap -histo <PID> | head -n 50
# 输出示例:
num #instances #bytes class name
----------------------------------------------
1: 1000000 2000000000 [B // byte数组占用最多
2: 500000 80000000 java.util.HashMap$Node五、高级排查技巧
1. 追踪堆外内存泄漏
# 开启Native Memory Tracking(启动参数)
-XX:NativeMemoryTracking=detail
# 查看NMT报告
jcmd <PID> VM.native_memory detail
# 重点检查:
- Total committed (非堆内存区如Direct Buffer、JNI代码)2. 线程栈分析
# 生成线程快照
jstack <PID> > jstack.log
# 检查死锁或线程阻塞问题(可能导致间接OOM)3. 调优工具(Arthas)
# 安装并启动Arthas
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
# 常用命令:
dashboard # 实时监控内存、线程
heapdump --live /path/to/dump.hprof # 生成堆转储
thread -n 5 # 查看最忙线程六、解决方案分类
| 问题类型 | 解决方案 |
| 堆内存泄漏 | 修复代码(如释放被静态集合持有的对象引用) |
| 堆内存不足 | 调整 参数,增加堆大小(需结合系统物理内存) |
| 元空间溢出 | 增加 值 |
| 直接内存泄漏 | 检查NIO ByteBuffer是否未释放,或调整 |
| FGC频繁且老年代回收效率低 | 优化GC算法(如切换至G1/CMS)、调整Young/Old区比例、或减少大对象生成 |
附录:常见错误排查流程图
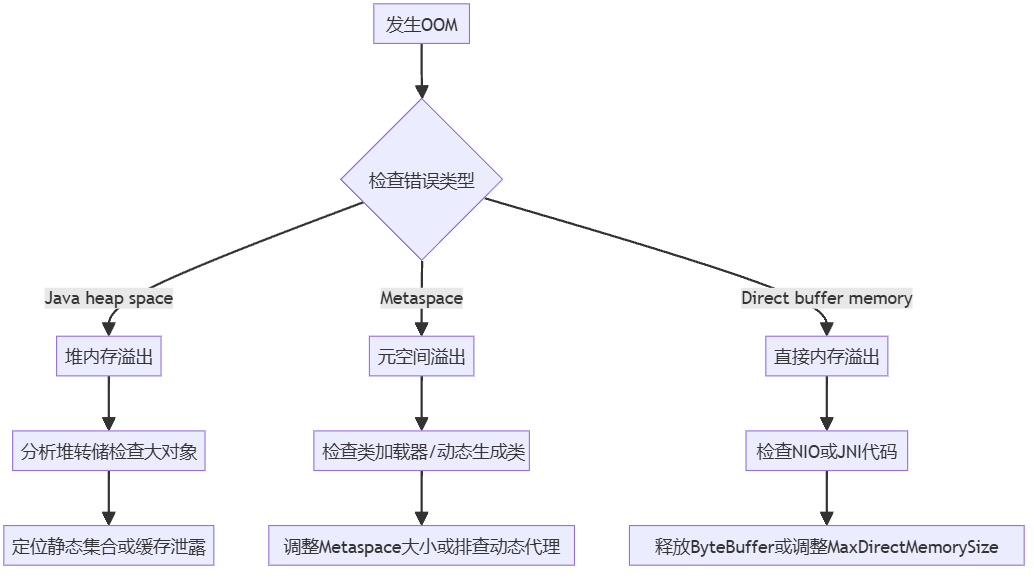
Step2:更贴近实际的 OOM 场景模拟与应急处理方案
一、复杂场景下的 OOM 模拟(附解决方案)
1. 大对象 + 内存泄漏(类似缓存雪崩)
// 模拟缓存服务持续加载大对象未释放
public class CacheService {
private static Map<String, byte[]> cache = new HashMap<>();
public void loadData(String key) {
// 模拟从数据库加载10MB大对象(实际可能是报表、图片等)
byte[] data = new byte[10 * 1024 * 1024];
cache.put(key, data);
}
public static void main(String[] args) throws InterruptedException {
CacheService service = new CacheService();
while (true) {
service.loadData(UUID.randomUUID().toString());
Thread.sleep(100); // 模拟间隔请求
}
}
}触发参数:
java -Xms100m -Xmx100m -XX:+HeapDumpOnOutOfMemoryError CacheService问题现象:
- 服务响应变慢 → Full GC 频繁 → 最终 OOM
- 未直接宕机:但新请求无法处理(线程阻塞在 GC)
应急处理:
- 立即摘流:从负载均衡下线该节点(如 Nginx
weight=0)。 - 快速扩容:临时增加实例内存(K8s 可动态调整
resources.limits.memory)。 - 分析 Dump:
# 生成堆转储(若未自动生成)
jmap -dump:format=b,file=/tmp/cache_leak.hprof <pid>- 临时补救:
-
- 通过 Arthas 动态清理缓存(无需重启):
ognl '@com.example.CacheService@cache.clear()'根治方案:
- 改用
Caffeine或Redis并设置容量和过期时间。 - 添加熔断机制(如
Hystrix请求量阈值)。
2. 死循环 + 线程池满(连锁反应)
// 模拟任务死循环占满线程池
public class ThreadPoolOOM {
private static ExecutorService pool = Executors.newFixedThreadPool(50);
public static void main(String[] args) {
while (true) {
pool.submit(() -> {
while (true) { // 死循环任务
// 模拟内存增长
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(UUID.randomUUID().toString());
}
}
});
}
}
}触发参数:
java -Xms100m -Xmx100m -XX:+HeapDumpOnOutOfMemoryError ThreadPoolOOM问题现象:
- CPU 100% → 线程池满 → 新任务拒绝 → 部分接口超时
- 未完全宕机:但健康检查失败导致被集群驱逐
应急处理:
- 线程池监控:
# 查看线程栈(定位死循环代码)
jstack <pid> | grep -A 10 'RUNNABLE'- 动态调整:
-
- 通过 Arthas 重置线程池(紧急恢复):
ognl '@com.example.ThreadPoolOOM@pool.shutdownNow()'- 限流降级:
-
- 在网关层(如 Spring Cloud Gateway)配置并发限制。
根治方案:
- 改用有界队列:
new ThreadPoolExecutor(core, max, keepAlive, TimeUnit.SECONDS, new LinkedBlockingQueue(1000))。 - 添加任务超时控制:
Future<?> future = pool.submit(task);
future.get(5, TimeUnit.SECONDS); // 超时取消二、OOM 发生后的关键步骤(未宕机时)
1. 快速诊断四连
| 步骤 | 命令/工具 | 目标 |
| 确认内存分布 |
| 找出占用最多的对象类型 |
| 检查GC状态 |
| 判断是否因GC无法回收导致堆积 |
| 抓取线程栈 |
| 排查死循环或锁竞争 |
| 保留现场证据 |
| 供后续分析 |
2. 临时补救措施
- 释放资源:
-
- 调用服务的
/actuator/refresh端点(Spring Boot)重置缓存。 - 通过 JMX 动态调整内存池(如
HotSpotDiagnosticMXBean)。
- 调用服务的
- 流量控制:
-
- 在 API 网关层限制并发请求数(如 Nginx
limit_req_zone)。
- 在 API 网关层限制并发请求数(如 Nginx
三、深度定位工具链
| 工具 | 适用场景 | 关键命令示例 |
| MAT | 分析堆转储文件找出泄漏点 | 查看 |
| Arthas | 在线诊断无需停机 |
|
| Prometheus + Grafana | 监控历史内存趋势 | 配置 |
| Perfino | 商业工具快速定位性能瓶颈 | 自动关联代码和内存分配 |
四、根治方案设计原则
- 防御性编程
-
- 对大集合使用
Guava的EvictingQueue(自动淘汰)。 - 对第三方库调用设置熔断(如
Resilience4j)。
- 对大集合使用
- 资源隔离
-
- 重要服务独立部署(避免被问题服务拖垮)。
- 使用
-XX:MaxDirectMemorySize限制堆外内存。
- 压测验证
-
- 用
JMeter模拟高并发,观察Grafana内存曲线。
- 用
- 监控告警
-
- 基于
Micrometer配置 OOM 前预警(如 Old Gen 使用率 >90%)。
- 基于
五、经典案例分析
案例:某订单服务因导出 Excel 未分页导致 OOM
- 现象:导出 10 万行数据时内存飙升。
- 应急:
-
- 通过
jmap发现XSSFWorkbook对象占 800MB。 - 临时限制导出最大行数(配置中心动态生效)。
- 通过
- 根治:
-
- 改用
EasyExcel流式导出。 - 添加
-XX:+UseG1GC -XX:G1ReservePercent=20提升 GC 效率。
- 改用
总结
- 未宕机时的黄金时间:优先摘流保集群,再内存分析。
- 工具链组合拳:
jmap+MAT定泄漏点,Arthas动态修复。 - 长效机制:资源隔离 + 熔断限流 + 监控覆盖。
通过模拟真实场景的复杂 OOM,结合可落地的应急和根治方案,能有效提升故障应对能力。


















 3413
3413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









