







 本文使用Python的Matplotlib库,对勒布朗·詹姆斯从2003年至2018年的NBA生涯数据进行可视化,包括得分、篮板、助攻等九项关键指标,通过定制化的柱状图展示其历年表现。
本文使用Python的Matplotlib库,对勒布朗·詹姆斯从2003年至2018年的NBA生涯数据进行可视化,包括得分、篮板、助攻等九项关键指标,通过定制化的柱状图展示其历年表现。
简介
- 本篇文章使用Kaggle.com上的数据集NBA Players stats since 1950中的Seasons_Stats.csv,其包含从1950至今的每个赛季的球员数据,每条数据有53项栏目,是综合性较强的NBA数据集,我尝试从中提取勒布朗詹姆斯的生涯数据,并用Matplotlib库实现可视化功能。
- 第一部分:勒布朗生涯数据可视化(一)用Spark SQL从NBA数据集中提取相关数据
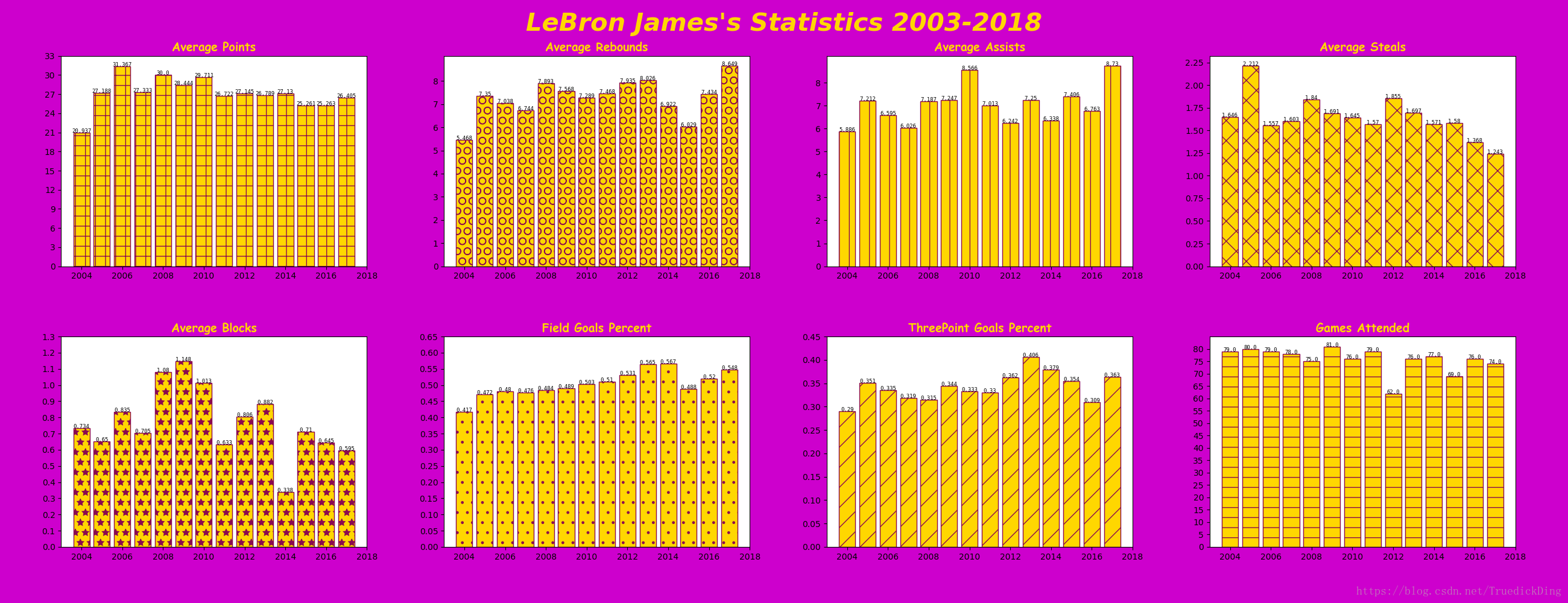
- 第二部分中我们使用第一部分检索出来的相关数据,并绘制出定制样式的柱形图,效果如下:
配置
- 语言:Scala 2.11
- Spark版本:Spark 2.3.1
主要内容
- 建立Figure并分为多个子Plot,分别做图
- Text类解析
- 条形图Bar的创建及属性设置
- 为条形图设置图像上面的具体数据标记
- 条形图坐标轴的域及精度设置
- 通过Fontdict来设置字体样式
编程实践
读取数据并转换格式
第二部分我们获取了勒布朗詹姆斯的九项数据,并保存到csv文件中:
2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015,2016,2017
20.937,27.188,31.367,27.333,30.0,28.444,29.711,26.722,27.145,26.789,27.13,25.261,25.263,26.405
5.468,7.35,7.038,6.744,7.893,7.568,7.289,7.468,7.935,8.026,6.922,6.029,7.434,8.649
5.886,7.212,6.595,6.026,7.187,7.247,8.566,7.013,6.242,7.25,6.338,7.406,6.763,8.73
1.646,2.212,1.557,1.603,1.84,1.691,1.645,1.57,1.855,1.697,1.571,1.58,1.368,1.243
0.734,0.65,0.835,0.705,1.08,1.148,1.013,0.633,0.806,0.882,0.338,0.71,0.645,0.595
79.0,80.0,79.0,78.0,75.0,81.0,76.0,79.0,62.0,76.0,77.0,69.0,76.0,74.0
0.417,0.472,0.48,0.476,0.484,0.489,0.503,0.51,0.531,0.565,0.567,0.488,0.52,0.548
0.29,0.351,0.335,0.319,0.315,0.344,0.333,0.33,0.362,0.406,0.379,0.354,0.309,0.363
这九项数据分别代表年份、得分、篮板、助攻、抢断、篮板、出场数、投篮命中率和三分球命中率,下面我们将其读到我们的Python文件中:
lebron_info = open("D:/SparkProjects/NBADataBase/data/lebron_data.csv")
yearList = [int(i) for i in lebron_info.readline().split(',')]
pointsList = [float(i) for i in lebron_info.readline().split(',')]
reboundsList = [float(i) for i in lebron_info.readline().split(',')]
assistsList = [float(i) for i in lebron_info.readline().split(',')]
stealsList = [float(i) for i in lebron_info.readline().split(',')]
blocksList = [float(i) for i in lebron_info.readline().split(',')]
gamesList = [float(i) for i in lebron_info.readline().split(',')]
fieldPercentList = [float(i) for i in lebron_info.readline().split(',')]
threePercentList = [float(i) for i in lebron_info.readline().split(',')]
笔者原本想使用Python的自带CSV文件处理库 CSV File Reading and Writing,可是由于笔者需要将文件中内容存储到不同的List中保存,使用其更显繁琐,故使用了最笨的方法, 一行一行读取文件,用split函数转换为List,并强制改变了不同List中的数据类型。
设置页面主标题,并将其分割为多个子区域
如上所述,我们有九类数据,现考虑将年份作为横坐标,将其余数据作为纵坐标做表,考虑到不同类型数据的数据值域差别很大,绘制在同一个图中十分难获取相关信息,故我们将其分为八个子区域分别作图:
我们首先对Figure类进行探究:
matplotlib.figure.Figure - Matplotlib 3.0.0 documentation
可见其包含如下参数:
| 参数名 | 意义 |
|---|---|
| figsize | 尺寸大小,默认为界面大小 |
| dpi | “Dots per inch”,衡量图像点密度的指数 |
| facecolor | 规定界面的颜色 |
| edgecolor | 界面边缘的颜色 |
| linewidth | 边缘的宽度参数 |
| frameon | 是否显示边框的参数 |
| subplotpars | 子区域的相关参数 |
| tight_layout | 可以通过包含“w_pad”、"h_pad"和"rect"的字典来改变边缘参数 |
| constrained_layout | 若设置为True则可以自动调整子区域和装饰区域的 |
在此我们通过figsize来将图像大小设置得适中,再通过facecolor设置背景色,然后通过layout这一dict类型数据设置了pad的大小,即边框区域的面积
layout = {
'pad': 5
}
fig = plt.figure(figsize=[26, 10], facecolor='#CD00CD', tight_layout=layout)
然后我们设置了主标题:
fig.suptitle("LeBron James's Statistics 2003-2018", fontstyle='italic',
fontweight='bold', fontsize=30, color='#FFD700',
horizontalalignment='center', verticalalignment='top')
在此我们通过subtitle里面的Text属性定制了字体样式,我们顺便来看一下Text类包含什么参数,来自text - Matplotlib 3.0.0 documentation,我挑选了几个最常用的参数来介绍:
| 参数名 | 介绍 |
|---|---|
| backgroundcolor | 背景颜色 |
| color | 字体颜色 |
| fontfamily | 设置的字体族名称或/及类族名称的一个优先表,会以第一个可以识别的字体为准进行设置,可选值 {FONTNAME, ‘serif’, ‘sans-serif’, ‘cursive’, ‘fantasy’, ‘monospace’} |
| fontname | 选择的字体名称,若不存在则设置为默认字体可选值 {FONTNAME, ‘serif’, ‘sans-serif’, ‘cursive’, ‘fantasy’, ‘monospace’} |
| fontsize | 字体大小,可以设置为标识字号的数字,或字符串{ ‘xx-small’, ‘x-small’, ‘small’, ‘medium’, ‘large’, ‘x-large’, ‘xx-large’} |
| fontstretch | 字体的压缩属性,可以是0-1000的一个数值,也可以是字符串{‘ultra-condensed’, ‘extra-condensed’, ‘condensed’, ‘semi-condensed’, ‘normal’, ‘semi-expanded’, ‘expanded’, ‘extra-expanded’, ‘ultra-expanded’} |
| fontstyle | 可规定字体的倾斜效果,可选 {‘normal’, ‘italic’, ‘oblique’},后两个值均代表倾斜,区别是’italic’从字体自带的效果库中选择倾斜效果,而’oblique’是程序对字体做的倾斜处理 |
| fontweight | 字体大小,可以是0-1000的一个数值,也可以是字符串{‘ultralight’, ‘light’, ‘normal’, ‘regular’, ‘book’, ‘medium’, ‘roman’, ‘semibold’, ‘demibold’, ‘demi’, ‘bold’, ‘heavy’, ‘extra bold’, ‘black’ |
| horizontalalignment | 水平对齐样式选择,可以选择{‘center’, ‘right’, ‘left’} |
| verticalalignment | 垂直对齐,可以选择{‘center’, ‘top’, ‘bottom’, ‘baseline’, ‘center_baseline’} |
最终字体样式如下:

然后我们尝试将其分割为八个子区域,首先我们考察subplot函数的参数:
matplotlib.figure.Figure.subplots - Matplotlib 3.0.0 documentation
| 参数名 | 介绍 |
|---|---|
| nrows, ncols | 分割的行数和列数 |
| sharex, sharey | 设置是否共享坐标轴,取值为 bool or {‘none’, ‘all’, ‘row’, ‘col’} |
| squeeze | 规定是否将1 * M和 N * 1的分割也作为二维数组返回 |
| subplot_kw | 可以设置为字典类型,其中的参数作为add_subplot函数的参数传递到每个子区域中 |
| gridspec_kw | 可以设置为字典类型,其中参数作为GridSpec函数的参数用于构造每个区域,详见 matplotlib.gridspec.GridSpec |
| ax | Axes类型的数组,用于规定每个子区域的格式,详见下文 |
在此我们只规定行数和列数,其他遵循默认设置:
axs = fig.subplots(2, 4)
条形图的绘制和参数设置
因为我们在axes类上画图,故我们先查看 matplotlib.axes.Axes.bar - Matplotlib 3.0.0 documentation 来了解一下参数有哪些:
| 参数名 | 介绍 |
|---|---|
| x | 横坐标的值序列 |
| height | 用于规定条形图的高度的序列 |
| width | 规定条形图每个数据条的宽度,以比例形式给出,默认0.8 |
| bottom | 规定y坐标轴以什么值为最小值显示在图中 |
| align | 数据条的对齐方式,可选{‘center’, ‘edge’},其中‘edge’为左对齐,右对齐可以通过设置width参数为负来实现 |
| color | 规定每个数据条的颜色(包含edgecolor和facecolor) |
| facecolor | 数据条内部的颜色 |
| edgecolor | 数据条边框的颜色 |
| linewidth | 数据条边缘的宽度 |
| tick_lable | 规定数据条的刻度标签,默认为数值标签 |
| hatch | 用于填充的样式,可选有{’/’, ‘’, ’ |
我们据此创建一个柱状图:
axs[0][0].bar(yearList, pointsList, hatch='+', color='#FFD700', edgecolor='#8B0A50')
我们又通过以下语句设置了坐标轴的范围和精度,并在数据条上方显示具体数据:
axs[0][0].set_yticks(np.arange(0, 35, 3))
axs[0][0].set_xlim(2003, 2018)
for a, b in zip(yearList, pointsList):
axs[0][0].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
即y轴的范围为0至35,精度为3,x轴为2003至2018;
其中fontdict通过字典格式设置了字体样式,一般格式如下:
fontTitle = {
'family': 'fantasy',
'color': '#FFD700',
'weight': 'demibold',
'size': 14
}
axs[0][0].set_title('Average Points', fontdict=fontTitle)
四项分别设置了字体族、颜色、粗细和大小,我们用它设置了分标题,最终第一个子区域如下:
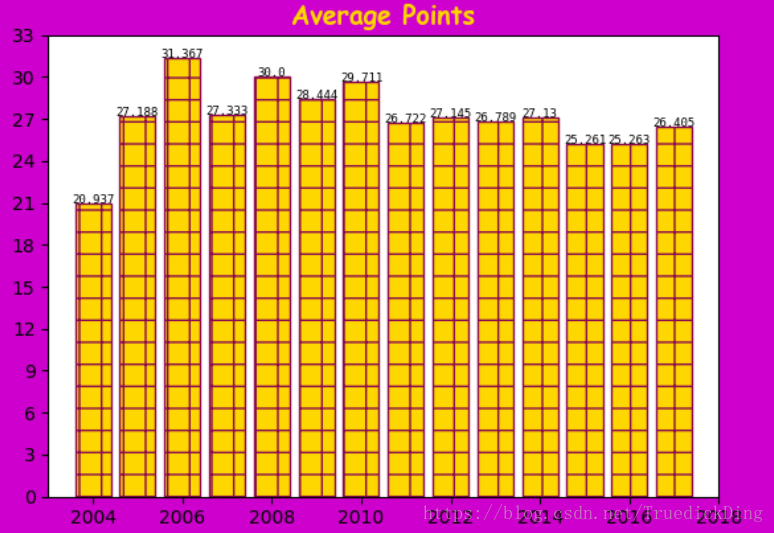 以此方法绘制所有子区域的条形图:
以此方法绘制所有子区域的条形图:
axs[0][0].set_title('Average Points', fontdict=fontTitle)
axs[0][0].bar(yearList, pointsList, hatch='+', color='#FFD700', edgecolor='#8B0A50')
axs[0][0].set_yticks(np.arange(0, 35, 3))
axs[0][0].set_xlim(2003, 2018)
for a, b in zip(yearList, pointsList):
axs[0][0].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[0][1].set_title('Average Rebounds', fontdict=fontTitle)
axs[0][1].bar(yearList, reboundsList, hatch='O', color='#FFD700', edgecolor='#8B0A50')
axs[0][1].set_yticks(np.arange(0, 9, 1))
axs[0][1].set_xlim(2003, 2018)
for a, b in zip(yearList, reboundsList):
axs[0][1].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[0][2].set_title("Average Assists", fontdict=fontTitle)
axs[0][2].bar(yearList, assistsList, hatch='|', color='#FFD700', edgecolor='#8B0A50')
axs[0][2].set_yticks(np.arange(0, 9, 1))
axs[0][2].set_xlim(2003, 2018)
for a, b in zip(yearList, assistsList):
axs[0][2].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[0][3].set_title("Average Steals", fontdict=fontTitle)
axs[0][3].bar(yearList, stealsList, hatch='X', color='#FFD700', edgecolor='#8B0A50')
axs[0][3].set_yticks(np.arange(0, 2.5, 0.25))
axs[0][3].set_xlim(2003, 2018)
for a, b in zip(yearList, stealsList):
axs[0][3].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[1][0].set_title("Average Blocks", fontdict=fontTitle)
axs[1][0].bar(yearList, blocksList, hatch='*', color='#FFD700', edgecolor='#8B0A50')
axs[1][0].set_yticks(np.arange(0, 1.4, 0.1))
axs[1][0].set_xlim(2003, 2018)
for a, b in zip(yearList, blocksList):
axs[1][0].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[1][1].set_title("Field Goals Percent", fontdict=fontTitle)
axs[1][1].bar(yearList, fieldPercentList, hatch='.', color='#FFD700', edgecolor='#8B0A50')
axs[1][1].set_yticks(np.arange(0, 0.7, 0.05))
axs[1][1].set_xlim(2003, 2018)
for a, b in zip(yearList, fieldPercentList):
axs[1][1].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[1][2].set_title("ThreePoint Goals Percent", fontdict=fontTitle)
axs[1][2].bar(yearList, threePercentList, hatch='/', color='#FFD700', edgecolor='#8B0A50')
axs[1][2].set_yticks(np.arange(0, 0.5, 0.05))
axs[1][2].set_xlim(2003, 2018)
for a, b in zip(yearList, threePercentList):
axs[1][2].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
axs[1][3].set_title("Games Attended", fontdict=fontTitle)
axs[1][3].bar(yearList, gamesList, hatch='-', color='#FFD700', edgecolor='#8B0A50')
axs[1][3].set_yticks(np.arange(0, 85, 5))
axs[1][3].set_xlim(2003, 2018)
for a, b in zip(yearList, gamesList):
axs[1][3].text(a, b, b,
horizontalalignment='center', verticalalignment='baseline',
fontdict=fontNum)
保存图像
plt.savefig('D:/SparkProjects/NBADataBase/data/lebron_statsfig.png', facecolor='#CD00CD')
plt.show()
注意一点,若想在保存图片之后查看图片,应将show放在savefig之后,因savefig函数运行之后会将plot重置为白色。
最终效果如下,湖人配色的勒布朗生涯技术统计,还算可以吧:
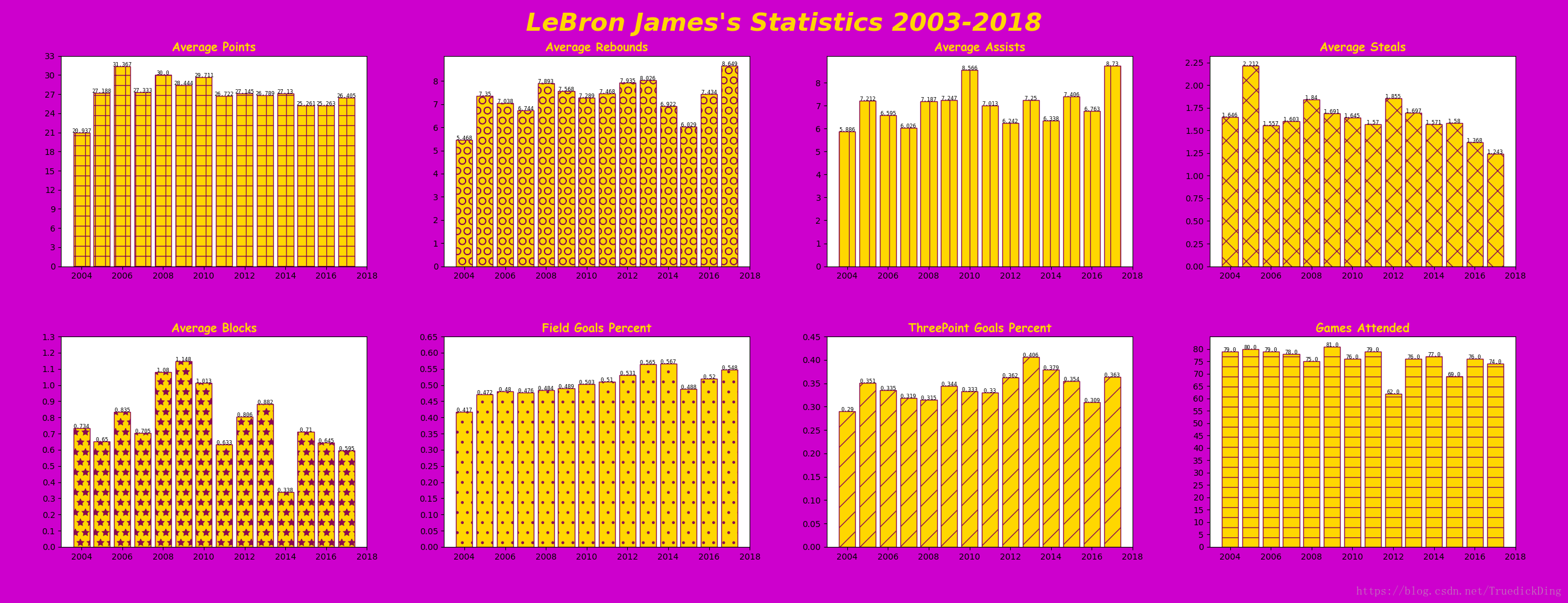



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









